松浦さんの誕生日?という話。

実在する松浦さんのことについてではないです。結論から言うと、作ったスクリプト上で、Wikipedia から API を使って情報を取得する際のロジックにバグがあったので対処した話。メモ程度の内容。
以前、note の記事を Twitter のほうに自動連携するスクリプトを作ったということを記事に書いた。
で、その際に、おまけで実装した、Wikipedia から「今日は何の日?」情報を取得する処理に不具合があった。
事の発端は、本日(3/31)の自分のツイートを確認してみたら、こんなのになっていた。
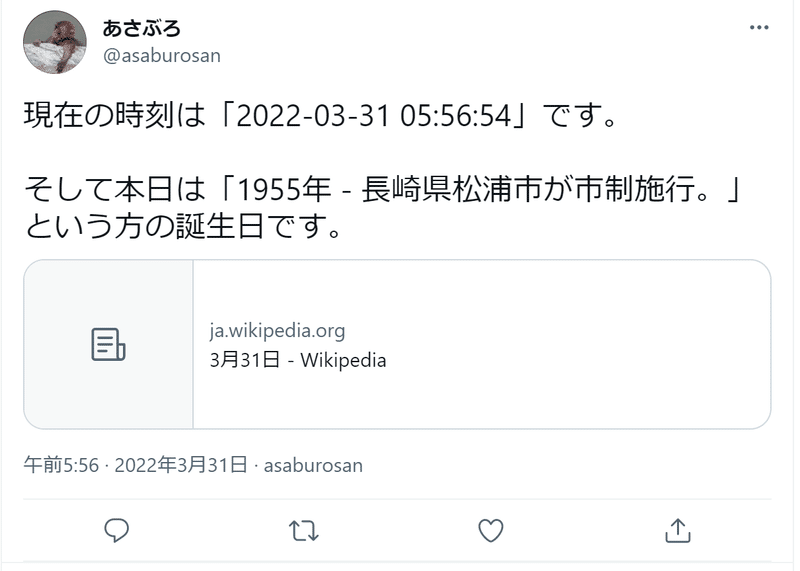
https://twitter.com/asaburosan
「誕生日です」とか言っているのに、なにやら中身は「できごと」っぽいことが書かれている。さて、どうしたものか。
このままでは、毎日私のアカウントのツイートを楽しみにして「今日は歴史上で何があったのかな」「何という人の誕生日なんだろうな」と胸躍らせてくれているフォロワーさんの期待を裏切るようなことになってしまう。もしかしたらその中には、私の Twitter がこの世界で唯一の情報源だという人もいらっしゃるかもしれない。このツイートをよく読みもせず鵜呑みにして「今日3月31日はさ、長崎県の松浦さんって人の誕生日でね」なんて他人に吹聴してしまったことで、赤っ恥をかかせることになりかねない。誤った情報を、これ以上提供するわけにはいかないのだ。(フォロワー0人だけど)
というわけで、調査と対処。
原因は、Wikipedia の「〇月〇日」というページの構成が、想定していたものとは違っていたためだった。「できごと」と「誕生日」の情報を抜きたくて、当初は何も考えずに配列の最初と二番目を引っ張ってきたのだが、どうやらその通りの構成ではないようだった。
たとえば、「3月30日」のページでは、
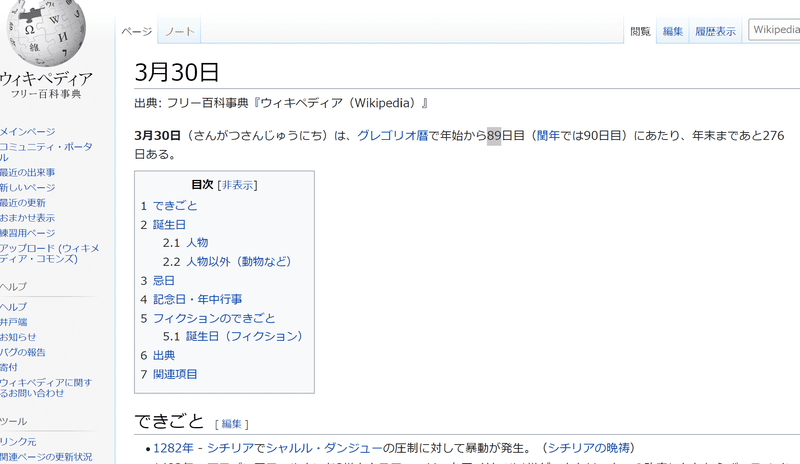
というふうに、「1.できごと」「2.誕生日」となっているため、配列の最初と二番目でそのまま取得することができた。目次というところを見ると、どんなセクションが存在するのか何となく分かる。
・配列の最初の要素⇒「できごと」がとれる
・配列の二番目の要素⇒「誕生日」がとれる
想定した通りだとこういうふうに。
しかし、「3月31日」では、
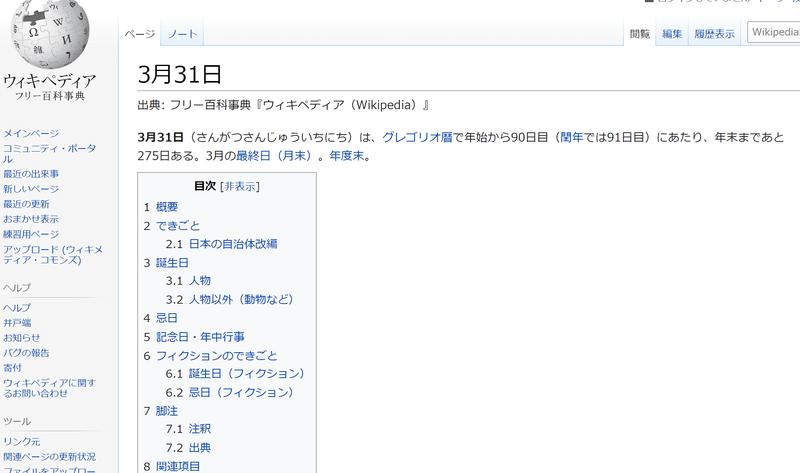
というふうに、最初に「概要」というセクションがあって、「2.できごと」「3.誕生日」となっている。こうなると、単純に配列の最初と二番目を取得しても、正しく「できごと」と「誕生日」は抜けない。
・配列の最初の要素⇒「概要」がとれる
・配列の二番目の要素⇒「できごと」がとれる
あれっ、「誕生日」はどこ行った?
デバッグして中を見るとよく分かる。
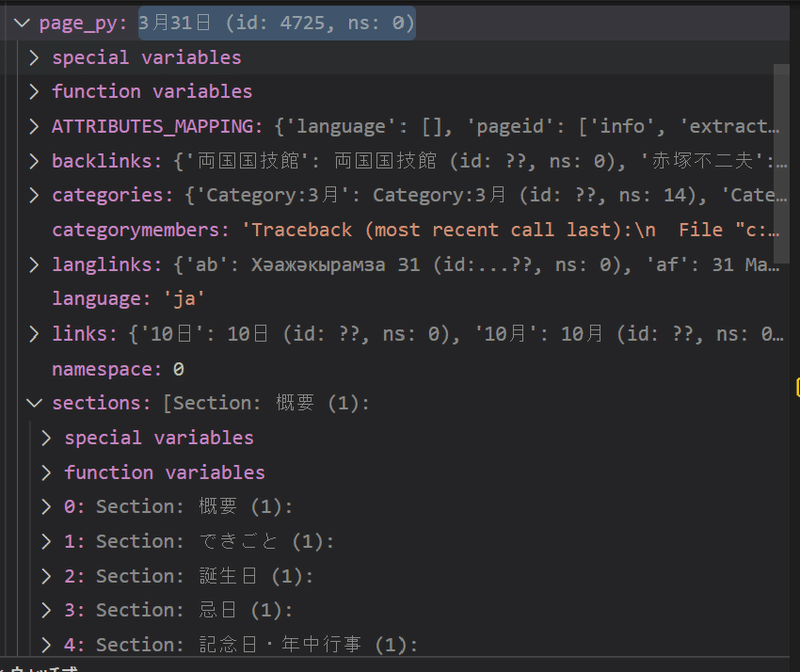
つまり、配列の順番は保証されていなくて、それに左右されないような取得方法でないといけないということだ。
というわけで、当該関数の実装を修正してみた。
def get_today_event():
# Wikipedia API で本日の日付の出来事などを取得
d = datetime.now()
dt = d.strftime("%Y-%m-%d %H:%M:%S")
wiki_wiki = wikipediaapi.Wikipedia('ja')
page_py = wiki_wiki.page(str(d.month) + "月" + str(d.day) +"日")
# ランダムで出来事や誕生日を抽出
idx = 0
idx_event = -1
idx_birth = -1
for sec in page_py.sections:
# sections のインデックスを取得
if "できごと" == sec.title:
idx_event = idx
elif "誕生日" == sec.title:
idx_birth = idx
idx += 1
if idx_event != -1 and idx_birth != -1:
l_idx = [idx_event, idx_birth]
x = random.choice(l_idx)
# sections のインデックスによって出力する文言を分ける
if x == idx_event:
txt_event = page_py.sections[x].text
msg_event = "という出来事があった日"
elif x == idx_birth:
txt_event = page_py.sections[x].sections[0].text
msg_event = "という方の誕生日"
else:
txt_event = None
msg_event = None
if txt_event != None:
l_event = txt_event.split('\n')
y = random.randint(0,len(l_event)-1)
event = l_event[y]
uri = urllib.parse.quote('https://ja.wikipedia.org/wiki/{}月{}日'.format(d.month, d.day), safe='/:')
msg = "現在の時刻は「" + str(dt) +"」です。"
if msg_event != None:
msg += "\n\nそして本日は「" + event + "」" + msg_event + "です。\n" + uri
return (msg)(解説)
ポイントは、page_py.sections オブジェクト(配列)内に、title というプロパティがあるようなので、これを使ったこと。この title で「概要」とか「できごと」とか「誕生日」とかの情報を持っているため、配列自体をループで回して、欲しいセクションの title に該当したら、それらのインデックスをリストで保持しておく。それを後でランダム抽出するように変更した。実に原始的だが、確実だし可読性は割と高いのでこうした。というか私しか読まないコードなので正しい値がとれりゃ何でもいい。
というわけで、今日は長崎県にいる松浦さんという方の誕生日だということが言いたかったわけではなく、「1955年 - 長崎県松浦市が市制施行」された日なのである。謹んでお詫び申し上げます。
(本日が誕生日の松浦さん、おめでとうございます)
この記事が気に入ったらサポートをしてみませんか?