
note の API が突然使えなくなったのでスクレイピングしてみた話。

タイトル通りです。少し専門的と言いますか、混み入った話。
まず、先日つぶやきでも書きましたが、note の一部のAPI が使えなくなりました。
https://note.com/furokun/n/nfe1a87d0255e
以前に記事でも書いたのですが、私は note の自分の記事を定期的にバックアップを取るようにしています。
※詳細はマガジン参照ください。
https://note.com/furokun/m/md1994df308b3
今では note 標準機能でエクスポートもありますけど、自力でスクリプトを作成してゴリゴリとデータを抜いて、地道にバックアップを取っているわけです。そのバックアップしたデータを、はてブロとかローカルDBに入れたりしています。
で、その自力エクスポートする際に、note に用意されている(あくまで非公式らしいですが)以下の API を用いて、データを取得しています。
--API その1
https://note.com/api/v2/creators/{ユーザ名}/contents?kind=note&page={ページ番号}
--API その2
https://note.com/api/v1/notes/{記事のキー}
今までは、上記「その1」で記事の一覧を取得して、そこから記事のキーをもとに「その2」で記事の詳細を取得してました。
一応「その1」でもそれなりの情報が取得できます。
こんな感じです。
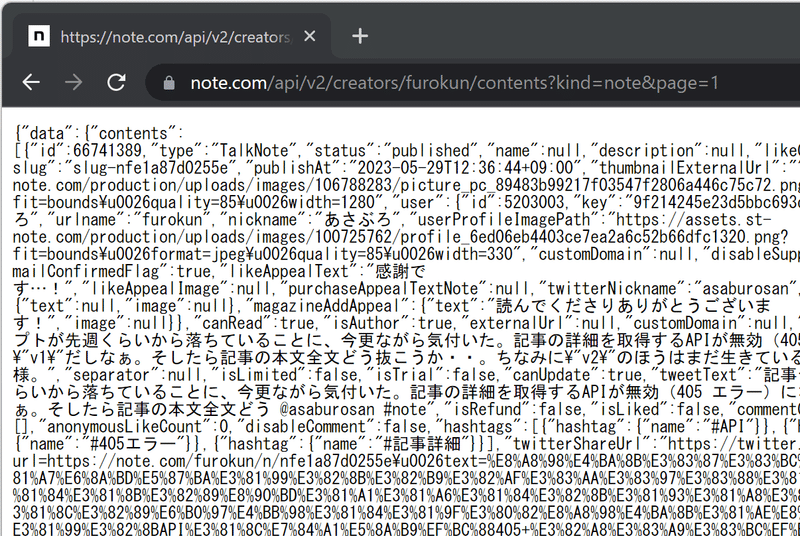
ある程度欲しい情報はここに揃ってる。
ただ、「その1」では肝心の記事本文が全ては取れなかったんですよね。途中で省略されてしまう仕様のようで。
それで仕方なく「その2」を使う、そんな二段構えでデータ取得をしていました。
ですが、先日、「その2」を実行すると、エラーになっていることが分かりました。
こんな感じです。
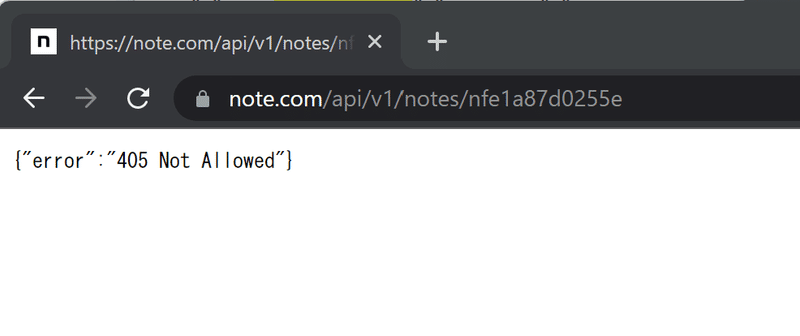
原因は分かりませんけど、たぶん API を廃止したとかなのかなぁと勝手に想像します。非公式ですし。それに v1 って書いてあるから、古いバージョンは廃止しちゃおうとかもあるのかなって。まあこれも勝手な妄想ですけど。もしくは、あまりに API 使ってデータ抜きすぎたから禁止されちゃったとか。
まあ使えなくなってしまったものはしょうがない。ただ、いつまでも放置しておくのもどうかと思ったので、API を使わない方法で実現するようにしました。
ずばり、スクレイピングでやればいいかなと。
(というか正直「スクレイピング」って何?の状態なんですけど、何となくエンジニアとしてそれは恥ずかしい気がしたのでそれは内緒・・)
というわけでこんな感じにしました。
以下コードです。
note の記事データを取得するところだけ抜粋。
私は、Python で上記の連携スクリプトを書いているのですが、まず変更前。
def get_note_entry_body(key):
#""""""""""""""""""""""""""""""""""""""
#""" note から特定の記事の本文全文を取得 """
#""""""""""""""""""""""""""""""""""""""
n_entry_url=f"https://note.com/api/v1/notes/{str(key)}"
res_dictEntry=requests.get(n_entry_url).json()
body = res_dictEntry["data"]["body"] # 本文
return body
def get_note_entry(n_id):
#""""""""""""""""""""""""""""""""""""""
#""" note から記事情報を取得 """
#""" <戻り値> """
#""" [0] note_type:タイプ"""
#""" [1] title:タイトル"""
#""" [2] key:記事ID"""
#""" [3] body:本文"""
#""" [4] uri:記事リンクURL"""
#""" [5] publish:投稿日時"""
#""" [6] tags:タグ"""
#""""""""""""""""""""""""""""""""""""""
res=[]
s = requests.Session()
# 記事一覧(最大251記事。1ページあたり6記事)
for page in range(1,43):
n_list_url=f"https://note.com/api/v2/creators/{n_id}/contents?kind=note&page={str(page)}"
# API
res_dict=s.get(n_list_url).json()
for i in range(len(res_dict["data"]["contents"])):
l = res_dict["data"]["contents"][i]
note_type = l["type"] # タイプ
title = "つぶやき" if note_type == 'TalkNote' else l["name"] # タイトル
key = l["key"] # key
body = get_note_entry_body(key) # 本文(# 上記APIでは記事本文全てが取得できなかったのでKeyをもとに別の関数を呼ぶ)
uri = l["noteUrl"] # URL
publish = l["publishAt"] # 投稿日時
tags = [ i["hashtag"]["name"] for i in l["hashtags"] ] # タグ一覧
res.append([note_type,title,key,body,uri,publish,tags])
return res
そして以下が変更後になります。
def get_note_entry_body(key, n_id):
#""""""""""""""""""""""""""""""""""""""
#""" note から特定の記事の本文全文を取得(API使わずスクレイピング) """
#""""""""""""""""""""""""""""""""""""""
time.sleep(0.5)
n_entry_url=f"https://note.com/{n_id}/n/{str(key)}"
res = requests.get(n_entry_url)
html = res.content
soup = BeautifulSoup(html, "html.parser")
body = str(soup.find('div',attrs={'data-name':'body'})) # 本文
return body
def get_note_entry(n_id):
#""""""""""""""""""""""""""""""""""""""
#""" note から記事情報を取得 """
#""" <戻り値> """
#""" [0] note_type:タイプ"""
#""" [1] title:タイトル"""
#""" [2] key:記事ID"""
#""" [3] body:本文"""
#""" [4] uri:記事リンクURL"""
#""" [5] publish:投稿日時"""
#""" [6] tags:タグ"""
#""""""""""""""""""""""""""""""""""""""
res=[]
s = requests.Session()
# 記事一覧(最大251記事。1ページあたり6記事)
for page in range(1,43):
n_list_url=f"https://note.com/api/v2/creators/{n_id}/contents?kind=note&page={str(page)}"
# API
res_dict=s.get(n_list_url).json()
for i in range(len(res_dict["data"]["contents"])):
l = res_dict["data"]["contents"][i]
note_type = l["type"] # タイプ
title = "つぶやき" if note_type == 'TalkNote' else l["name"] # タイトル
key = l["key"] # key
body = l["body"] if note_type == 'TalkNote' else get_note_entry_body(key, n_id) # 本文(# 上記APIでは記事本文全てが取得できなかったのでKeyをもとに別の関数を呼ぶ)
uri = l["noteUrl"] # URL
publish = l["publishAt"] # 投稿日時
tags = [ i["hashtag"]["name"] for i in l["hashtags"] ] # タグ一覧
res.append([note_type,title,key,body,uri,publish,tags])
return res※上記のソースコードにより生じた如何なる損害についても、一切の責任は負いかねます。あらかじめご了承ください。
思ったよりは簡単に出来たなという印象でした。requestsでゲットしてきたものを使うのは同じ。変更前はあらかじめAPI 側で構造がキチッと決まった状態で提供されていたので扱いやすかったですけど、変更後のほうは自分で必要なのを取捨選択が必要という感じでした。
ざっくり、詳しい変更点はこんなところです。
<get_note_entry_body() メソッド>
・API を叩くのではなく普段みんなが見る通常の記事ページのURLにアクセス。
・高頻度のアクセスだと禁止される可能性があると聞いたので、0.5秒の待機時間を追加。
<get_note_entry() メソッド>
・body メンバーにセットする内容は「つぶやき」か普通の「記事」かで条件分岐。
ポイントは、どうやら記事の本文データは div タグ内の data-name="body" の中にあるということが分かりましたので、BeautifulSoup という Python のライブラリを用いてデータを抽出・整形してます。

「data-name="body"」内に本文全文格納されている。
必要な情報が格納されているタグさえ分かってしまえば実装はそこまで難しくはなかったです。事実、コード書くよりも、パース後のソースを読んでそれを探す作業が一番時間がかかりました。。
なお、インポートするデータの都合上どうしても xml 形式のデータで欲しかったので、text プロパティを参照するようなことはせず、こんな形の抜き方になっています。
で、抜いた情報を文字列化しています。そのままの状態ですと、他のサービスへのインポートなどなど、正しく本文の情報が取り扱えなかったため。
まあこれが正しいスクレイピングの方法なのか正直お作法分かりませんけど、とりあえず欲しいデータは抜けたのでよしとします。意識低い系ですみません。
そんなこんなで、はてブロやローカルDBのほうにも、上手いこと同期できたようなので、これにて無事に解決ということにします。
※現在は非公開
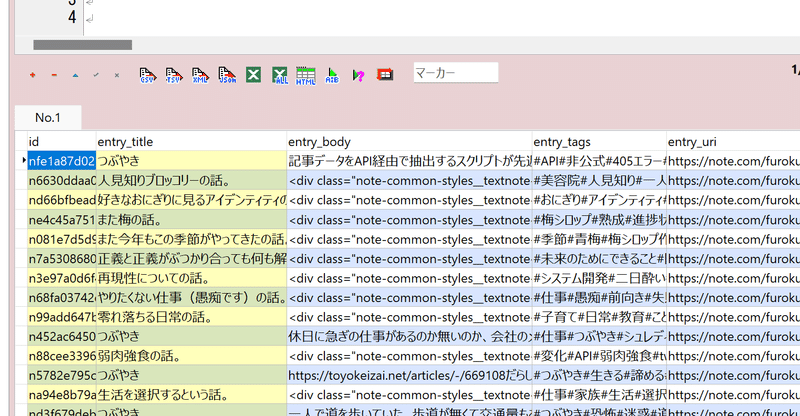
ここで色々な情報を保管。
というわけで一安心。
今回は、急遽 API の代替手段としてスクレイピングを実装してみたわけですけど、もう少し突き詰めれば色々応用が効きそうだなと思いました。データの整形さえ出来てしまえば、あとは収集は簡単というか。何よりライブラリが本当に便利ですよね。充実してます。Python は。仕事であんまり使ったことないので、いまだにスタンダードな書き方分からないですけど。
というか、いい加減 note は非公式じゃなくてキチンと API を公式提供してくれたら良いのにな、なんて。多分いつか v2 のほうも、そのうち突然使えなくなりそうな予感。まあそのときはまた他の方法で情報抜くことしかないですね。ラクをするためなら手を動かすことは惜しみません。面倒くさがりなので。。
ところで、結局スクレイピングって一体何だったんでしょうね。
「スクレイプ(scrape)」=「不要な情報を削って最小限にする」なんですかね。いやそれとも「必要な情報をちょっとずつ削るようにして貰ってくる」みたいなことかな。分かりません。とりあえず「削る」なんですよねきっと。違うのかな。まあいいや。そういう意味でこちらのトップ画を選ばせていただきました。鰹節!
短いですが、以上です。おしまい。
この記事が気に入ったらサポートをしてみませんか?