
大学が文書の機密性を定義して標示する方法|生成AI

2023年にChatGPTをはじめとする生成AIがひろまり、各大学はそれぞれの基本的な考え方を指針として発表した。
データベースで使われている語を分析すると、その内容や指摘している項目、語彙のバリエーションは大学ごとに大きな差はないが、内容の詳しさ(文書ごとの単語の量)には大きな差がある。
教員向けと学生向けを分けた上で活用事例を上げつつ詳細な注意喚起をおこなう大学(たとえば東北大学は教員向けの本文だけで5千字を超える)もあれば、神戸大学(本文376文字)のように簡潔で総合的(抽象的)な注意喚起に留めている大学もある。

2023年には国立大学の多くの大学でChatGPTへの初期対応の文書が提示されたが、2024年度以降は、より具体的な生成AIの活用方針、注意事項の周知が行われるものと思われる。
この記事では2024年から2025年にむけて、各大学が教職員および学生に対して周知するべき内容のうち、特に情報セキュリティとリテラシー教育(FDを含む)について講ずるべき対策を提言したい。
提言の動機は、
第一に神戸大学の指針のように、抽象的な指示では大学の情報資産を十分に守ることができず、学生の個人情報が意図せず漏洩するリスクが高いという危惧である。
第二に、多様な社会的、情報的背景を抱えた学生が一様の、高いリテラシーを持っていることが期待できない現状において、UNESCOや文科省などの求めている、大学がリテラシーとして周知すべき内容が十分に構成員に提示されていないことにある。
意図しない流出への注意喚起
文科省が2023年3月に公表した「教育情報セキュリティポリシーに関するガイドライン」では、情報セキュリティの脅威は表 3のように示されている。ここでは人為による脅威は「悪意のある他者」「悪意のある関係者」「関係者の過失」に分類されている。本ガイドラインは時期的に生成AIを前提としていないため、「情報の意図しない流出」については脅威に含まれていない。

生成AIは学生を含む関係者の、悪意の「ない」入力によって情報が外部に流出することがある。あるいは、あるアプリケーションの内部で生成AIが用いられていた場合、関係者本人は生成AIに入力したとすら思っておらず、結果的に入力されていたこともあるだろう。
この場合、どこまで「関係者の過失」となるか、そもそも過失なのかは難しい問題である。さらに、そのときには問題ないと思っていても(問題ないとされていても)、あとになって結果的に避けるべきでした、ということも有りうる。
生成AIによる情報流出で対策が難しいのは、「悪意のない他者(生成AI系サービスの提供元)」のサービスを「悪意のない関係者」が利用することによって情報資産が外部に流出することにある。
LLMに学習されてしまったデータが、直接的に何かの質問の出力結果として提示されることは稀かもしれないが、特定の操作によって個人情報を吐き出させることに成功した事例も報告されている。
情報セキュリティに関して国立大指針DBでは、重要な情報の「意図しない流出」への言及が51件見られた。
しかし内容としては個人情報や機密情報を入力しないように、という文言で注意喚起する文章がほとんどであり、具体的にどのようなデータが大学にとって機密情報なのかを例示している大学はごく少数である。
しかし、大学1年生にとって何が機密情報なのかを判断することは容易だろうか。非母語話者の新入生は、入学時ガイダンス資料を生成AI系の翻訳ソフトに入力することが適切かを判断できるだろうか。
私は台湾の大学で2年間勤務したが、国によって個人情報の常識や社会通念のレベルは大きく異なる。大学の構成員が一様な情報リテラシー、生成AIリテラシーの基準を具えていると期待することは難しい。
したがって、各大学は第一に、情報セキュリティ上の脅威として「意図しない流出」「悪意のない流出」を認識すること、そして第二に、意図しない流出を前提として、学内の情報資産のセキュリティレベルを定義し、各ドキュメントにセキュリティレベルを(もし流出した場合には悪意のある流出だと認定できるくらい)明示することが求められるだろう。
次項では大学の情報資産とセキュリティレベルを検討し、続いて学内のドキュメントに明示する具体的な方法を検討する。
機密性定義の事例
デジタル庁「ChatGPT 等の生成 AI の業務利用に関する申合せ(第2版)」において、現在のChatGPTが含まれる約款型クラウドサービスでは、省庁の業務において「要機密情報を取り扱うことはできない」(p. 2)とされている。
この要機密情報とは具体的にどのような文書を指すだろうか。
東京都は生成AIの導入にあたり、個人情報等、機密性の高い情報は入力しないことを基本ルールとしている。
東京都では機密性のランクを示したうえで、機密性Aは入力不可とし、安全性が確保された利用環境であれば、機密性Bまでの情報を入力可能としている。

大学において生成AIを用いる際にも、教職員、学生が日々扱うデータの中で、生成AIに入力してはならない情報を各大学が具体的に定める必要がある。
情報資産の機密性ランクについては大学間である程度共有できる部分があるだろう。
しかし学内システムに生成AIを組み込んでいるか、データポリシー、オプトアウト(AIへの学習拒否)がどのような契約になっているかなどは大学によって異なるため、どのレベルの機密性ランクを、どのシステムに入力してよいかについては、大学ごとに独自の基準を定める必要がある。
大学の情報資産はどのようなものか
セキュリティレベルの定義にあたっては、学内にどのような情報資産があり、どの情報資産を生成AIに対する管理項目とするかをリストアップする必要がある。
大学における情報資産について、『大学IR標準ガイドブック』には以下の分類が示されている。

管理項目のリストアップは、まずは「組織情報」から行うこととなるだろう。非構造化データであっても保守・保管の規則等が定められており、全容の把握は困難な課題ではない。一方で「個別情報」、なかでも「非構造化データ」は構成員個人のPCやサーバ、クラウド上などにあるため全容の把握が困難で、整理・管理が困難である。
問題は、大学では個別情報については構成員一人ひとりがデータごとに判断しなければならないことであり、この構成員向けのガイドラインの策定は2024年度前半の各大学の急務である。
「大学・高専における生成 AI の教学面の取扱いについて(周知)」においても、機密情報の具体的な内容は示されていません。各大学・高専において指針を出すようにという勧告にとどまっています。
生成 AI への入力を通じ、機密情報や個人情報等が意図せず流出・漏洩する可能性等があるため、一般的なセキュリティ上の留意点として、機密情報や個人情報等を安易に生成 AI に入力することは避けることが必要と考えられること。なお、特に教職員が生成 AI を利活用する際には、各大学・高専における情報セキュリティに関する指針や、個人情報保護法を踏まえた対応が必要となることに留意すること。また、生成AI の種類によっては、入力の内容を生成 AI の学習に使用させない(オプトアウト)ことができること。
(文科省, 2023年7月13日)
個人的な考えとしては、各大学は、この周知文書を構成員個人にそのままパスすること、つまり具体的な基準、指針を示さずに「機密情報を入力するな」と指示することは避けるべきだと思います。
構成員(学生・教職員)に適切に判断させるのは無理なので、セキュリティレベルの定義と文書への標示を行うべきだと思います。
情報資産のセキュリティレベルをどう定義するか
それでは、各大学は情報資産のセキュリティレベルをどのように定義していけばよいだろうか。情報資産を機密性等によって分類する方法として、文科省による「教育情報セキュリティポリシーに関するガイドライン(令和4年3月)」の1章3項(p.32)以降が参考になる。このガイドラインは教育機関を管轄する地方自治体向けのガイドラインであるが、一般企業向けの各種ガイドラインよりは大学と親和性が高い。
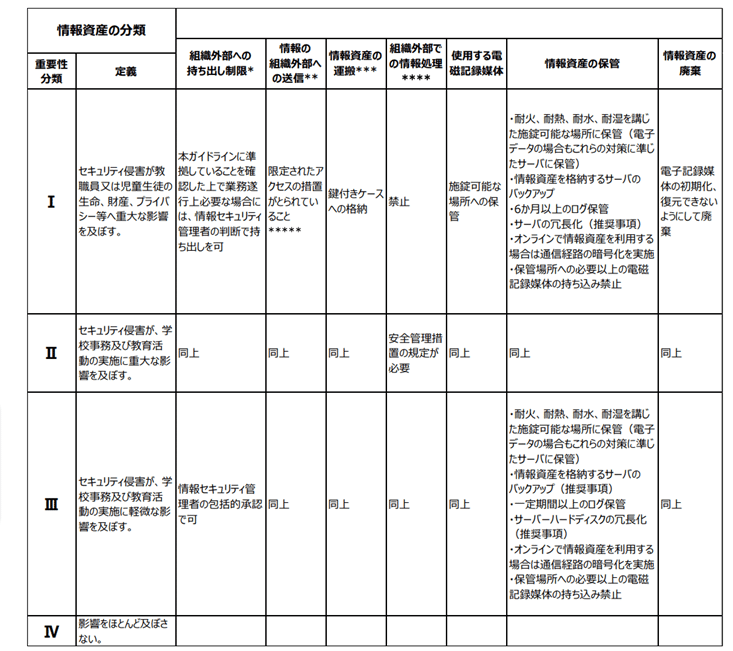
「教育情報セキュリティポリシーに関するガイドライン」では情報資産を分類し、分類ごとに管理体制を定めることとしている。情報資産の分類は、「機密性」「完全性」及び「可用性」によってなされている。紙面都合により示さないが、図表5(P.37)に例示されている。同ガイドラインでは、情報資産の分類方法について以下のように示されている。
情報資産の分類は、機密性、完全性及び可用性に基づき、分類することが望ましいが、教職員の理解度等に応じ、以下(注:図表6)のような重要性に基づき分類することもあり得る。
引用内に示されているように、大学の規模や学生への周知のしやすさは大学によって異なるため、たとえば管理部門、教職員レベルでは機密性、完全性、可用性で分類しておき、学生に周知する際には理解しやすい「重要性」による分類で示すという運用も考えられる。
セキュリティレベルによる生成AIへの入力可否の規定
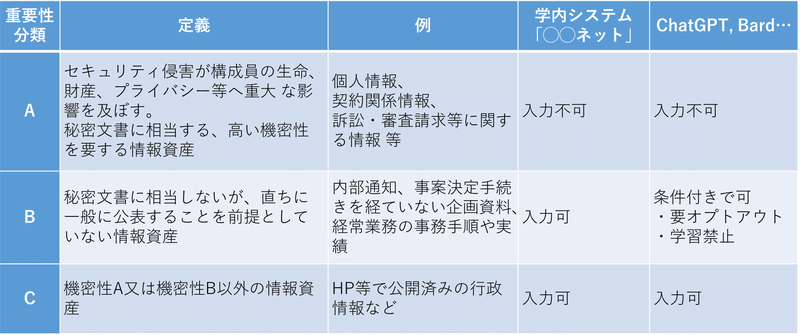
学内の情報資産のセキュリティレベルの定義が完了すれば、次にセキュリティレベルに応じた生成AIへの入力可否を規定することとなる。
入力できる情報のレベルは各大学のシステムの設計に依存するが、東京都の事例を参考にすれば表 のように提示することができる。
学内のドキュメントへの標示の具体的な方法
セキュリティレベルの定義と、レベルごとの生成AIへの入力可否を規定したからといって、その一覧表を学内に周知するだけでは情報漏洩は十分に防ぐことはできない。
学内でセキュリティレベルを明示する方法として、いくつかの暫定的なアイデアを示す。悪意のない、意図しない流出に対応するためであることを踏まえ、読者にわかりやすく表示し、高リスクのドキュメントほど多重に明示・標示することが重要と思われる。
文書のヘッダーやフッター、右肩に「レベルA」というテキストボックスを入れて明示する
ファイル名の末尾に特定の文字列(例えば”Lv-A”など)を入れる
電子ドキュメントのメタ情報としてセキュリティレベルの情報を埋め込む
ヘッダーやファイル名に特定の文字列を入れるという方法であれば、人間にも理解しやすく、また学内システムに生成AIを導入した場合に、その文字列を含むファイルはシステムに読み込ませない、というフィルタリングも容易になるだろう。
既存のファイル名に一括で文字列を加えることも簡単である。
なお些末なことではあるが、ファイル名等に展開することを考えるとローマ数字の重要性分類にするよりは、東京都の機密性分類のようにABCにするほうが良い。
こうした手法は、(多くの大学が指針で求めるように)読者、学生にセキュリティレベルを判断させ、機密情報の入力の自重を求めるのではなく、ドキュメントの作成者側が積極的にセキュリティレベルを明示することが特徴である。
例えば著作権のマーク(©)やクリエイティブ・コモンズマーク(CC)を作者自身が示すように、ドキュメントの作成者(大学や教員)が各ドキュメントにマーキングを行うことが求められる。
なお、フェイルセーフ(ミスしたときに安全なデザイン)の観点からすると、重要な書類にマーキングするよりも、「生成AIに入力してもよい書類」にマークをする(マークがないときには入力してはいけない)とするほうが望ましい。
生成AIに情報を流出させないシステムエンジニアリングと同様に、組織内の関係者にどのように機密性を提示するかという人間側の情報デザインも、今後の大きな研究課題である。
この記事が気に入ったらサポートをしてみませんか?