競馬予想モデルを実装してみた

はじめに
はじめまして。ハルと申します。自己紹介の時に自分の趣味の一つとして競馬を挙げるくらい、競馬が好きです。
私の推しは「オースミハルカ」です。下の名前が同じです。黄色いメンコがかわいいです。

G1勝利はなかったものの、重賞で名だたるG1馬をぶっちぎっていた姿は圧巻でした。
私、かれこれ競馬歴○年になりますが、回収率はイマイチ。いつもJRAにまきあげられています(笑)どうやったらJRAからまきあげてやれるだろうか、というのが長年のテーマでしたが、丁度Aidemyのデータ分析講座(6カ月)を受講しておりましたので、最終課題で競馬予想モデルを実装してみよう!と思いました。
ということで、本Noteは2023.10月より受講しているAidemyデータ分析コース(6カ月)の最終成果物になります。
初学者の初実装ということで、拙い部分が多々あるかと思いますが温かい目で見て頂けると嬉しいです。
実行環境について
Python
Google Colaboratory
分析のステップ
以下のようなステップで分析を行いました。それぞれ見ていきたいと思います。
1. 目標設定
2. データ収集(スクレイピング)
3. データ加工・準備
4. モデル作成
5. 評価
1. 目標設定
1~3着また4着以降を予測するモデルを構築します。
なぜこの分け方にしたかと言うと、自分の馬券購入のスタイルとして穴馬の複勝を狙うことが多く、1~3着を予想できればそこから複勝のオッズが高い馬を選び馬券購入し、効率的にかつ高配当で気持ちよく回収することができると考えたからです。1-3着を予想できれば、ワイドや三連複等にも活用できそうです。
1~3着、4着以降の2パターンの分類(二値分類)ということで、今回は講座で習った決定木ベースの分類モデルを一通り試し、最終的にはKaggleでよく使われているLight GBMでハイパーパラメータを調整し予測、精度を比較してみたいと思います。
今回、無料では複勝のオッズデータが取得できず回収率まで出すことができないので、モデル間の精度比較までにとどめたいと思います。
2.データ収集(スクレイピング)
今回使用させて頂くデータについては、netkeibaさん(https://www.netkeiba.com/)よりスクレイピングの上、収集させて頂きました。
スクレイピングに取り掛かる前に、まずは利用規約を一読しました。
スクレイピングNGという表現はなく、またデータも私的利用であれば大丈夫そうです。サイトによっては明確にスクレイピングNGとしているサイトもありますので、この点要注意です。
では、スクレイピングしたコードを記載していきます。
本記事では、2015-2023年のデータを取得し、2015-2022年を訓練データ、2023年をテストデータとしていますが、一気にデータ取得するとかなりの時間を要しGoogle Colaboratoryのランタイム内に終わらなかったので、以下コード内では3年分(2015-2017年)のデータをひとまず取得しました。年のリストを変更し、3回実施致ました。3年分のデータ取得で4時間半ほどかかりました。
#Netkeibaからスクレイピングを行う
#必要なモジュールのインポートを行う
import requests
from bs4 import BeautifulSoup
import urllib
import pandas as pd
import csv
import re
#2015-2017年のデータを取る
#解析するURLを入れるリストを作成し、URLを保存していく
urls = []
for y in ["2015","2016","2017"]:#年の指定
for l in ["01","02","03","04","05","06","07","08","09","10"]:#競馬場番号
for h in ["01","02","03","04","05","06"]:#開催回数
for d in ["01","02","03","04","05","06","07","08","09","10","11","12"]:#開催日
for r in ["01","02","03","04","05","06","07","08","09","10","11","12"]:#レース番号
urls.append(f"https://db.netkeiba.com/race/{y}{l}{h}{d}{r}/")
#スクレイピングしたデータを格納するための空のデータフレームを作っておく
result_df = pd.DataFrame()
#中にはデータが存在しないURLもあるため、try/exceptにてエラーが出た場合処理を飛ばすようにする
for url in urls:
try:
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser") #textだと文字化けするので、html.contentに変更する
#テーブル以外の要素の抽出を行う
race_title = soup.find(class_="racedata fc").find("h1")#レース名
ground = soup.find(class_="racedata fc").find("span").contents[0][0]#芝/ダ/障 障害は分析することはないので、後々の分析からははずす
turn = soup.find(class_="racedata fc").find("span").contents[0][1]#左/右/芝 障害の場合は芝と表示されるが、障害は分析対象外にするので問題ない
distance = re.findall(r'\d{4}', soup.find(class_="racedata fc").find("span").contents[0])[0]#距離 正規表現で数字4桁を探す
weather = re.findall(r'天候\s*:\s*([^\/]+)', soup.find(class_="racedata fc").find("span").contents[0].replace("\xa0",""))[0]#天候
ground_condition = re.findall(r'良|稍重|重|不良', soup.find(class_="racedata fc").find("span").contents[0])[0]#馬場状況
year = re.findall(r'(\d{4})',soup.find(class_="smalltxt").contents[0])[0]#開催年
date = re.findall(r'(\d{1,2}月\d{1,2}日)',soup.find(class_="smalltxt").contents[0])[0]#開催日
location = re.findall(r'\d+回(..)',soup.find(class_="smalltxt").contents[0])[0]#場所
#テーブル要素の抽出を行う
table = soup.find("table")
#テーブルデータの保存先を作る
#テーブルデータの最初のtr(ヘッダー)を除く行をすべて解析、その中にあるtd要素を全てテキストで抽出し、かつテーブル以外の要素と組み合わせ、保存先に保存
table_data =[]
for row in table.find_all("tr")[1:]:
new_row_data = [year] + [date] + [location] + [race_title.text] + [ground] + [turn] + [distance] + [weather] + [ground_condition] + [cell.get_text(strip=True) for cell in row.find_all(['td'])]
table_data.append(new_row_data)
df = pd.DataFrame(table_data)
result_df = pd.concat([result_df, df], ignore_index=True)
except Exception as e:
pass
# CSVファイルとして保存
result_df.to_csv("horse_db_2015_2017.csv", encoding="utf-8-sig")
#作成したCSVファイルをダウンロードする
from google.colab import files
files.download("horse_db_2015_2017.csv")コードの解説も書いておきます。
#Netkeibaからスクレイピングを行う
#必要なモジュールのスクレイピング
import requests
from bs4 import BeautifulSoup
import urllib
import pandas as pd
import csv
import re
#2015-2017年のデータを取る
#解析するURLを入れるリストを作成し、URLを保存していく
urls = []
for y in ["2015","2016","2017"]:#年の指定
for l in ["01","02","03","04","05","06","07","08","09","10"]:#競馬場番号
for h in ["01","02","03","04","05","06"]:#開催回数
for d in ["01","02","03","04","05","06","07","08","09","10","11","12"]:#開催日
for r in ["01","02","03","04","05","06","07","08","09","10","11","12"]:#レース番号
urls.append(f"https://db.netkeiba.com/race/{y}{l}{h}{d}{r}/")まず、必要なライブラリをインポートし、その後解析するURLを取得してappendでリスト(urls)に保存していきます。
netkeibaのURLのロジックについては、こちらのサイトを大いに参考にさせて頂きました。ありがとうございます!
#スクレイピングしたデータを格納するための空のデータフレームを作っておく
result_df = pd.DataFrame()
#中にはデータが存在しないURLもあるため、try/exceptにてエラーが出た場合処理を飛ばすようにする
for url in urls:
try:
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser") #textだと文字化けするので、html.contentに変更する抽出した情報を保存するために、まずは空のデータフレームを準備しておきます。
次に、urlsの中に格納したURLを解析してHTMLの情報を読み込んで行きますが、中にはurl内にデータが存在しないものもあり、その場合エラーで実行が止まってしまいます。try/Exceptを入れてエラーがでた時の処理を飛ばします。
上記で読み込んだHTMLから該当する情報を抽出していきます。
黄色の部分、赤枠のtable部分に分けて抽出していきました。
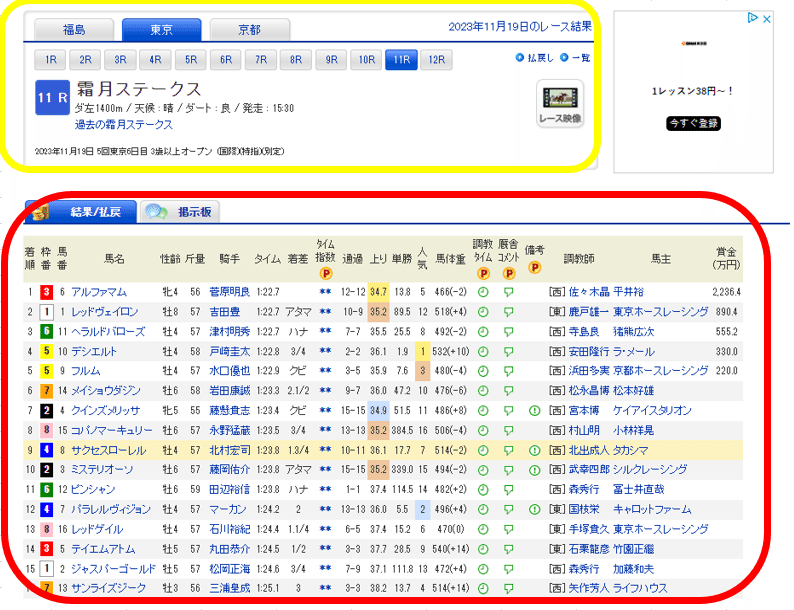
まず、黄色枠部分の情報で分析に使うであろう情報を抽出していきます。
久しぶりの正規表現にだいぶ苦労しました。
#テーブル以外の要素の抽出を行う
race_title = soup.find(class_="racedata fc").find("h1")#レース名
ground = soup.find(class_="racedata fc").find("span").contents[0][0]#芝/ダ/障 障害は分析することはないので、後々の分析からははずす
turn = soup.find(class_="racedata fc").find("span").contents[0][1]#左/右/芝 障害の場合は芝と表示されるが、障害は分析対象外にするので問題ない
distance = re.findall(r'\d{4}', soup.find(class_="racedata fc").find("span").contents[0])[0]#距離 正規表現で数字4桁を探す
weather = re.findall(r'天候\s*:\s*([^\/]+)', soup.find(class_="racedata fc").find("span").contents[0].replace("\xa0",""))[0]#天候
ground_condition = re.findall(r'良|稍重|重|不良', soup.find(class_="racedata fc").find("span").contents[0])[0]#馬場状況
year = re.findall(r'(\d{4})',soup.find(class_="smalltxt").contents[0])[0]#開催年
date = re.findall(r'(\d{1,2}月\d{1,2}日)',soup.find(class_="smalltxt").contents[0])[0]#開催日
location = re.findall(r'\d+回(..)',soup.find(class_="smalltxt").contents[0])[0]#場所
次に、赤枠のtable部分の情報を抽出していきます。for row in table.find_all("tr")[1:]:とすることにより、カラム名を除外することができます。
かつ上述で抽出した黄色枠部分の情報を加えて、データフレームを作ります。
#テーブルデータの保存先を作る
#テーブルデータの最初のtr(ヘッダー)を除く行をすべて解析、その中にあるtd要素を全てテキストで抽出し、かつテーブル以外の要素と組み合わせ、保存先に保存
table_data =[]
for row in table.find_all("tr")[1:]:
new_row_data = [year] + [date] + [location] + [race_title.text] + [ground] + [turn] + [distance] + [weather] + [ground_condition] + [cell.get_text(strip=True) for cell in row.find_all(['td'])]
table_data.append(new_row_data)
df = pd.DataFrame(table_data)
result_df = pd.concat([result_df, df], ignore_index=True)
except Exception as e:
pass最後に抽出した情報をcsvに保存し、試しにダウンロードして中身を確認!
# CSVファイルとして保存
result_df.to_csv("horse_db_2015_2017.csv", encoding="utf-8-sig")
#作成したCSVファイルをダウンロードする
from google.colab import files
files.download("horse_db_2015_2017.csv")この作業を、2015-2017/2018-2020/2021-2023の3回に分けて実行し、できたファイルが以下になります。

上述の通り、3年分抽出で4時間半ほどかかりましたので、9年分で14時間弱。これだけの量のスクレイピングは初めてだったので、結構時間かかるんだなぁと思いつつも、ファイルができあがった時はPythonのすごさを改めて感じました。
3.データ加工・準備
スクレイピングで収集したデータを加工し、分析の準備をしていきます。
以下、データ加工の際のコードになります。
#必要なモジュールのインポート
import pandas as pd
import csv
import re
#Google Driveに保存したファイルを読み込むために、マウントさせる
from google.colab import drive
drive.mount('/content/drive')
#csvファイルを読み込み、連結させる
horse_db = pd.DataFrame()
file_paths =["/content/drive/MyDrive/Colab Notebooks/Aidemy最終課題用/horse_db_2015_2017.csv",
"/content/drive/MyDrive/Colab Notebooks/Aidemy最終課題用/horse_db_2018_2020.csv",
"/content/drive/MyDrive/Colab Notebooks/Aidemy最終課題用/horse_db_2021_2023.csv"]
for file_path in file_paths:
df = pd.read_csv(file_path)
horse_db = pd.concat([horse_db, df], axis=0)
#カラムの移動、削除を行う
#13列目の情報をgenderとageに分割する
#23列目の情報をhorse_weightとhorse_weight_changeに分割する
#27列目の情報をeast_westとtrainer_nameに分割する
horse_db[["gender", "age"]] = horse_db["13"].str.extract(r'([^\d]+)(\d+)')
horse_db[["horse_weight", "horse_weight_change"]] = horse_db["23"].str.extract(r'(\d+)\s*\(([-+]?\d+)\)')
horse_db[["east_west", "trainer_name"]] = horse_db["27"].str.extract(r'\[([^]]+)\](.+)$')
#genderカラムを馬名の隣に移動
gender_column = horse_db.pop("gender")
horse_db.insert(14, "gender", gender_column)
#ageカラムを馬名の隣に移動、かつ分割前のカラム(牝4等)を削除する
age_column = horse_db.pop("age")
horse_db.insert(15, "age", age_column)
horse_db = horse_db.drop("13", axis=1)
#horse_weightカラムを馬名の隣に移動
horse_weight_column = horse_db.pop("horse_weight")
horse_db.insert(28, "horse_weight", horse_weight_column)
# #horse_weight_changeカラムを馬名の隣に移動、かつ分割前のカラム(牝4等)を削除する
horse_weight_change_column = horse_db.pop("horse_weight_change")
horse_db.insert(29, "horse_weight_change", horse_weight_change_column)
horse_db = horse_db.drop("23", axis=1)
#east_westカラムを移動
east_west_column = horse_db.pop("east_west")
horse_db.insert(31, "east_west", east_west_column)
#trainer_nameカラムを移動、かつ分割前のカラム([西]佐々木晶 等)を削除する
trainer_name_column = horse_db.pop("trainer_name")
horse_db.insert(32, "trainer_name", trainer_name_column)
horse_db = horse_db.drop("27", axis=1)
#分析に使用しないカラムUnnamed: 0,17,18,24,25,26,29 を落とす
horse_db = horse_db.drop(columns=["Unnamed: 0","17","18","24","25","26","29"])
# run_timeを秒に変換する関数
def time_to_seconds(time_str):
if isinstance(time_str, str): # time_strが文字列型かどうかをチェック
minutes, seconds = map(float, time_str.split(':')) # 文字列を分と秒に分割してfloat型に変換
return minutes * 60 + seconds # 秒に変換して返す
else:
return 0 # time_strが文字列でない場合、つまり欠損値の場合は0を返す
# run_timeカラムのデータを秒に変換
horse_db['run_time_seconds'] = horse_db['16'].apply(time_to_seconds)
#run_time_secondsカラムを移動、かつrun_timeカラムを削除する
run_time_seconds_column = horse_db.pop("run_time_seconds")
horse_db.insert(18, "run_time_seconds", run_time_seconds_column)
horse_db = horse_db.drop("16", axis=1)
#カラムに名前をつけていく
new_column_names = {
"0" : "year",#開催年
"1" : "date",#開催日
"2" : "location",#開催場所
"3" : "race_title",#レース名
"4" : "ground",#芝/ダ/障 障害は分析することはないので、後々の分析からははずす
"5" : "turn",#左/右/芝 障害の場合は芝と表示されるが、障害は分析対象外にするので問題ない
"6" : "distance",#距離
"7" : "weather",#天気
"8" : "ground_condition",#馬場状況
"9" : "rank",#着順
"10" : "post_number",#枠
"11" : "horse_number", #馬番
"12" : "horse_name",#馬名
"14" : "jockey_weight", #斤量
"15" : "jockey",#騎手
"19" : "order_process", #通過順
"20" : "time3Fs", #あがり3ハロン
"21" : "single_win", #単勝倍率
"22" : "popularity", #人気
"28" : "owner"
}
horse_db.rename(columns=new_column_names, inplace=True)
#分析に使用しない行をおとしていく
#障害レースを取り除く
horse_db = horse_db[horse_db["ground"] != "障"]
#着順に、失、取、除、中、降の文字列を含むものを取り除く
horse_db = horse_db[~horse_db['rank'].str.contains('失')]
horse_db = horse_db[~horse_db['rank'].str.contains('取')]
horse_db = horse_db[~horse_db['rank'].str.contains('除')]
horse_db = horse_db[~horse_db['rank'].str.contains('中')]
horse_db = horse_db[~horse_db['rank'].str.contains('降')]
#欠損値を確認する
print(horse_db.isnull().sum())
#time3Fに含まれる欠損値を含む行を削除する(3件だけのため)
horse_db = horse_db.dropna()
#使用する説明変数についてラベリングを行う
# LabelEncoder : 3値以上のラベル分類
from sklearn.preprocessing import LabelEncoder
horse_db_enc = horse_db.copy()
lbl = LabelEncoder()
horse_db_enc["location_enc"] = lbl.fit_transform(horse_db_enc["location"])
horse_db_enc["ground_enc"] = lbl.fit_transform(horse_db_enc["ground"])
horse_db_enc["turn_enc"] = lbl.fit_transform(horse_db_enc["turn"])
horse_db_enc["weather_enc"] = lbl.fit_transform(horse_db_enc["weather"])
horse_db_enc["ground_condition_enc"] = lbl.fit_transform(horse_db_enc["ground_condition"])
horse_db_enc["horse_name_enc"] = lbl.fit_transform(horse_db_enc["horse_name"])
horse_db_enc["gender_enc"] = lbl.fit_transform(horse_db_enc["gender"])
horse_db_enc["jockey_enc"] = lbl.fit_transform(horse_db_enc["jockey"])
horse_db_enc["trainer_name_enc"] = lbl.fit_transform(horse_db_enc["trainer_name"])
#horse_weight_change、age、rankを数値に変換する
horse_db_enc['horse_weight_change'] = horse_db_enc['horse_weight_change'].astype(int)
horse_db_enc['age'] = horse_db_enc['age'].astype(int)
horse_db_enc['rank'] = horse_db_enc['rank'].astype(int)
#目的変数rankを二値に変換する関数を定義する
#1-3着を0に、4着以降を1に置きかえる
def convert_to_binaryl_label(x):
if x<=3:
return 0
else:
return 1
horse_db_enc["rank_enc"] = horse_db_enc["rank"].apply(convert_to_binaryl_label)
#データ型の確認
horse_db.dtypes
#CSVファイルに保存する
horse_db_enc.to_csv("horse_db_enc.csv", encoding="utf-8-sig")簡単ですが、コードの各パートに解説をつけます。
#必要なモジュールのインポート
import pandas as pd
import csv
import re
#Googl Driveに保存したファイルを読み込むために、マウントさせる
from google.colab import drive
drive.mount('/content/drive')
#csvファイルを読み込み、連結させる
horse_db = pd.DataFrame()
file_paths =["/content/drive/MyDrive/Colab Notebooks/Aidemy最終課題用/horse_db_2015_2017.csv",
"/content/drive/MyDrive/Colab Notebooks/Aidemy最終課題用/horse_db_2018_2020.csv",
"/content/drive/MyDrive/Colab Notebooks/Aidemy最終課題用/horse_db_2021_2023.csv"]
for file_path in file_paths:
df = pd.read_csv(file_path)
horse_db = pd.concat([horse_db, df], axis=0)スクレピイングにて抽出した3つのcsvファイルを縦方向に結合します。
縦方向に結合させるには、pd.concat()で、axis=0を指定します。
#カラムの移動、削除を行う
#13列目の情報をgenderとageに分割する
#23列目の情報をhorse_weightとhorse_weight_changeに分割する
#27列目の情報をeast_westとtrainer_nameに分割する
horse_db[["gender", "age"]] = horse_db["13"].str.extract(r'([^\d]+)(\d+)')
horse_db[["horse_weight", "horse_weight_change"]] = horse_db["23"].str.extract(r'(\d+)\s*\(([-+]?\d+)\)')
horse_db[["east_west", "trainer_name"]] = horse_db["27"].str.extract(r'\[([^]]+)\](.+)$')
#genderカラムを馬名の隣に移動
gender_column = horse_db.pop("gender")
horse_db.insert(14, "gender", gender_column)
#ageカラムを馬名の隣に移動、かつ分割前のカラム(牝4等)を削除する
age_column = horse_db.pop("age")
horse_db.insert(15, "age", age_column)
horse_db = horse_db.drop("13", axis=1)
#horse_weightカラムを馬名の隣に移動
horse_weight_column = horse_db.pop("horse_weight")
horse_db.insert(28, "horse_weight", horse_weight_column)
# #horse_weight_changeカラムを馬名の隣に移動、かつ分割前のカラム(牝4等)を削除する
horse_weight_change_column = horse_db.pop("horse_weight_change")
horse_db.insert(29, "horse_weight_change", horse_weight_change_column)
horse_db = horse_db.drop("23", axis=1)
#east_westカラムを移動
east_west_column = horse_db.pop("east_west")
horse_db.insert(31, "east_west", east_west_column)
#trainer_nameカラムを移動、かつ分割前のカラム([西]佐々木晶 等)を削除する
trainer_name_column = horse_db.pop("trainer_name")
horse_db.insert(32, "trainer_name", trainer_name_column)
horse_db = horse_db.drop("27", axis=1)
#分析に使用しないカラムUnnamed: 0,17,18,24,25,26,29 を落とす
horse_db = horse_db.drop(columns=["Unnamed: 0","17","18","24","25","26","29"])情報を分割したいカラム、分析に使わないカラムのドロップ、カラムの移動等、加工を行います。

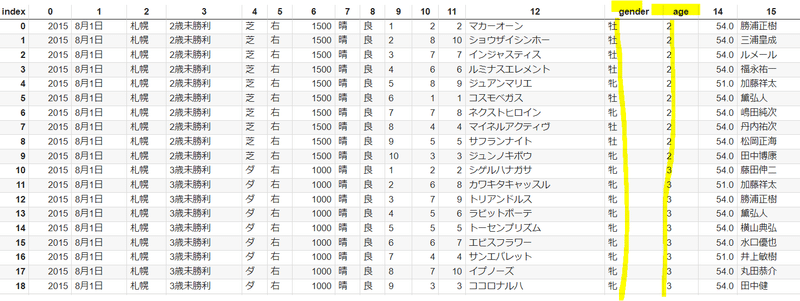
具体的に言うと、上図黄色部分で牝2になっているものを牝と2に分割、馬体重466(-2)を466と-2に分割、[東]古賀史生になっているものを[東]と古賀史生に分割し、分割後のカラムの移動や不要なカラムをドロップしました。
以下、牝と2を分割した例です。他のカラムもちゃんと分割できました。
# run_timeカラムのデータを秒に変換
horse_db['run_time_seconds'] = horse_db['16'].apply(time_to_seconds)
#run_time_secondsカラムを移動、かつrun_timeカラムを削除する
run_time_seconds_column = horse_db.pop("run_time_seconds")
horse_db.insert(18, "run_time_seconds", run_time_seconds_column)
horse_db = horse_db.drop("16", axis=1)タイムは分析で使う予定なので、処理しやすいように全て秒単位に揃えました。

↑こうだったものが、↓こうなりました。

#カラムに名前をつけていく
new_column_names = {
"0" : "year",#開催年
"1" : "date",#開催日
"2" : "location",#開催場所
"3" : "race_title",#レース名
"4" : "ground",#芝/ダ/障 障害は分析することはないので、後々の分析からははずす
"5" : "turn",#左/右/芝 障害の場合は芝と表示されるが、障害は分析対象外にするので問題ない
"6" : "distance",#距離
"7" : "weather",#天気
"8" : "ground_condition",#馬場状況
"9" : "rank",#着順
"10" : "post_number",#枠
"11" : "horse_number", #馬番
"12" : "horse_name",#馬名
"14" : "jockey_weight", #斤量
"15" : "jockey",#騎手
"19" : "order_process", #通過順
"20" : "time3Fs", #あがり3ハロン
"21" : "single_win", #単勝倍率
"22" : "popularity", #人気
"28" : "owner"
}
horse_db.rename(columns=new_column_names, inplace=True)カラムに名前をつけていきます。バッチリです!
この時点で、436355 rows × 27 columnsとなっています。
次のコードでは不要な行を落としていくので、後々の検算用として行数を確認しました。
#分析に使用しない行をおとしていく
#障害レースを取り除く
horse_db = horse_db[horse_db["ground"] != "障"]
#着順に、失、取、除、中、降の文字列を含むものを取り除く
horse_db = horse_db[~horse_db['rank'].str.contains('失')]
horse_db = horse_db[~horse_db['rank'].str.contains('取')]
horse_db = horse_db[~horse_db['rank'].str.contains('除')]
horse_db = horse_db[~horse_db['rank'].str.contains('中')]
horse_db = horse_db[~horse_db['rank'].str.contains('降')]今回、障害レースは分析除外したいのでground(芝/ダ/障)から"障"を含むものを省きます。障害は馬のケガも多く個人的に苦手で、基本的に馬券は買いません!また、rank(着順)に降格、取消、除外、中止、降格が含むものも取り除きます。
行削除後は、419729 rows × 27 columnsとなりました。
除外した行数を計算し、きちんと行削除できていることを念のため検算で確認しました。
#欠損値を確認する
print(horse_db.isnull().sum())
#time3Fに含まれる欠損値を含む行を削除する(3件だけのため)
horse_db = horse_db.dropna()欠損値を確認すると、time3F(あがり3ハロン)に3件欠損値がありました。
が、3件だけなのでdropna()で削除しました。

#使用する説明変数についてラベリングを行う
# LabelEncoder : 3値以上のラベル分類
from sklearn.preprocessing import LabelEncoder
horse_db_enc = horse_db.copy()
lbl = LabelEncoder()
horse_db_enc["location_enc"] = lbl.fit_transform(horse_db_enc["location"])
horse_db_enc["ground_enc"] = lbl.fit_transform(horse_db_enc["ground"])
horse_db_enc["turn_enc"] = lbl.fit_transform(horse_db_enc["turn"])
horse_db_enc["weather_enc"] = lbl.fit_transform(horse_db_enc["weather"])
horse_db_enc["ground_condition_enc"] = lbl.fit_transform(horse_db_enc["ground_condition"])
horse_db_enc["horse_name_enc"] = lbl.fit_transform(horse_db_enc["horse_name"])
horse_db_enc["gender_enc"] = lbl.fit_transform(horse_db_enc["gender"])
horse_db_enc["jockey_enc"] = lbl.fit_transform(horse_db_enc["jockey"])
horse_db_enc["trainer_name_enc"] = lbl.fit_transform(horse_db_enc["trainer_name"])今回は決定木、ランダムフォレスト、LightGBMなど、決定木ベースのモデルで予測をしていきます。決定木ベースのモデルの場合はLabel Encodingとの相性がよいとのことなので、全てLabel Encodingにてラベリングをしてみました。

#horse_weight_change、age、rankを数値に変換する
horse_db_enc['horse_weight_change'] = horse_db_enc['horse_weight_change'].astype(int)
horse_db_enc['age'] = horse_db_enc['age'].astype(int)
horse_db_enc['rank'] = horse_db_enc['rank'].astype(int)一部データがobjectになっていたので、数値に変更します。
#目的変数rankを二値に変換する関数を定義する
#1-3着を0に、4着以降を1に置きかえる
def convert_to_binaryl_label(x):
if x<=3:
return 0
else:
return 1
horse_db_enc["rank_enc"] = horse_db_enc["rank"].apply(convert_to_binaryl_label)目的変数であるrankを二値に変更していきます。今回は1-3着を0に、4着以降を1にしています。これでデータ加工は終わりました。

今回、モデルに使用するカラムのデータ型と内容について以下のようにメモをしておきます。

#CSVファイルに保存する
horse_db_enc.to_csv("horse_db_enc.csv", encoding="utf-8-sig")最後にCSVに保存しておきます。
4.モデル作成
#必要なモジュールのインポート
import pandas as pd
import csv
#Googl Driveに保存したファイルを読み込むために、マウントさせる
from google.colab import drive
drive.mount('/content/drive')
#csvファイルを読見込む
df = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/Aidemy最終課題用/horse_db_enc.csv")
df.head()保存したCSVを読み込み、念のため中身を確認↓

#2015-2022年のデータを訓練データ、2023年のデータをテストデータとする
train_X = df[(df['year'] >= 2013) & (df['year'] <= 2022)][['distance','post_number','horse_number','age','jockey_weight','run_time_seconds','time3Fs','horse_weight_change',
'location_enc', 'ground_enc', 'turn_enc', 'weather_enc',
'ground_condition_enc', 'horse_name_enc', 'gender_enc', 'jockey_enc',
'trainer_name_enc']]
test_X = df[(df['year'] == 2023)][['distance','post_number','horse_number','age','jockey_weight','run_time_seconds','time3Fs','horse_weight_change',
'location_enc', 'ground_enc', 'turn_enc', 'weather_enc',
'ground_condition_enc', 'horse_name_enc', 'gender_enc', 'jockey_enc',
'trainer_name_enc']]
train_y = df[(df['year'] >= 2013) & (df['year'] <= 2022)][["rank_enc"]]
test_y = df[(df['year'] == 2023)][["rank_enc"]]
print(f"train_X:{train_X.shape}")
print(f"test_X:{test_X.shape}")
print(f"train_y:{train_y.shape}")
print(f"test_y:{test_y.shape}")
今回、開催年で訓練データとテストデータに分けました。
2015-2022年開催分を訓練データ、2023年開催分をテストデータにしています。念のためshapeでサイズを確認しておきます。
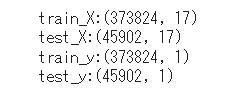
さて、ここからモデルを実際に構築していってみます。
まず、決定木で構築をしてみます。
#決定木モデルを構築する
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
from sklearn.tree import export_graphviz
import graphviz
#決定木でmax_depthハイパーパラメータの違いによる正解率をグラフで表してみる
#max_depthの値の範囲を指定する
depth_list = [i for i in range(1,20)]
#正解率を格納する空リストを作成
accuracy_DTC = []
#max_depthを変えながらモデルを学習
for max_depth in depth_list:
model_test_DTC = DecisionTreeClassifier(max_depth = max_depth, random_state=42)
model_test_DTC.fit(train_X, train_y)
accuracy_DTC.append(model_test_DTC.score(test_X, test_y))
print(accuracy_DTC)
#正解率を可視化する
plt.plot(depth_list, accuracy_DTC)
plt.xlabel("max_depth")
plt.ylabel("DecisionTreeClassifier accuracy")
plt.xticks([2,4,6,8,10,12,14,16,18,20])
plt.title("DecisionTreeClassifier accuracy by changing max_depth")
plt.show()
#max_depth=12でモデルを構築する
model_DTC = DecisionTreeClassifier(max_depth = 12)
#モデルに学習させる
model_DTC.fit(train_X, train_y)
#test_xに対するモデルの評価を行う
y_pred_DTC = model_DTC.predict(test_X)
#算出したy_predとtest_yの正答率を出す
DecisionTreeClassifierScore = metrics.accuracy_score(test_y,y_pred_DTC)
print(f"DecisionTreeClassifierScore: {DecisionTreeClassifierScore}")
#予測モデルの説明変数の重要度の可視化を行う
feature = model_DTC.feature_importances_
indices = np.argsort(feature)
# yearを除くデータフレームのカラム名を取得
column_names = X.columns.drop("year")
# 特徴量の重要度の棒グラフを描画する
plt.barh(range(len(feature)), feature[indices])
plt.yticks(range(len(feature)), [column_names[i] for i in indices], fontsize=14)
plt.xticks(fontsize=14)
plt.ylabel("Feature", fontsize=18)
plt.xlabel("Feature Importance", fontsize=18)
plt.show()
#決定木の可視化を行う
from sklearn.tree import export_graphviz
import graphviz
# feature_namesリストを作成する
feature_names = X.columns.drop("year")
# 決定木の見える化を行う
tree_data = export_graphviz(model_DTC, out_file=None, class_names=["0", "1"],
feature_names=feature_names, impurity=False, filled=True)
graphviz.Source(tree_data)簡単ですが、以下に説明をつけています。
#決定木でmax_depthハイパーパラメータの違いによる正解率をグラフで表してみる
#max_depthの値の範囲を指定する
depth_list = [i for i in range(1,20)]
#正解率を格納する空リストを作成
accuracy_DTC = []
#max_depthを変えながらモデルを学習
for max_depth in depth_list:
model_test_DTC = DecisionTreeClassifier(max_depth = max_depth, random_state=42)
model_test_DTC.fit(train_X, train_y)
accuracy_DTC.append(model_test_DTC.score(test_X, test_y))
print(accuracy_DTC)決定木の中でも重要なハイパーパラメータの値を調整すべく、1~20の範囲内で正解率を算出し、matplotlibで描画してみました。以下を見るとmax_depth=12辺りが精度がよさそうです。
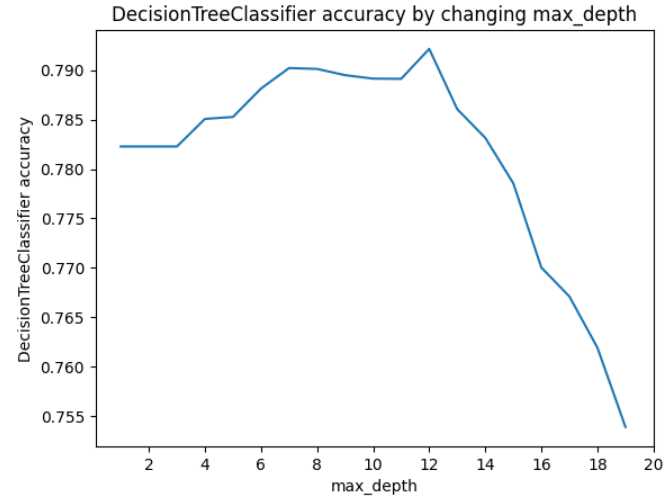
#max_depth=12でモデルを構築する
model_DTC = DecisionTreeClassifier(max_depth = 12)
#モデルに学習させる
model_DTC.fit(train_X, train_y)
#test_xに対するモデルの評価を行う
y_pred_DTC = model_DTC.predict(test_X)
#算出したy_predとtest_yの正答率を出す
DecisionTreeClassifierScore = metrics.accuracy_score(test_y,y_pred_DTC)
print(f"DecisionTreeClassifierScore: {DecisionTreeClassifierScore}")max_depth=12で改めてモデルを構築し、スコアを出しました。0.7919…まずまずのスコアなのでしょうか?

#予測モデルの説明変数の重要度の可視化を行う
feature = model_DTC.feature_importances_
indices = np.argsort(feature)
# yearを除くデータフレームのカラム名を取得
column_names = X.columns.drop("year")
# 特徴量の重要度の棒グラフを描画する
plt.barh(range(len(feature)), feature[indices])
plt.yticks(range(len(feature)), [column_names[i] for i in indices], fontsize=14)
plt.xticks(fontsize=14)
plt.ylabel("Feature", fontsize=18)
plt.xlabel("Feature Importance", fontsize=18)
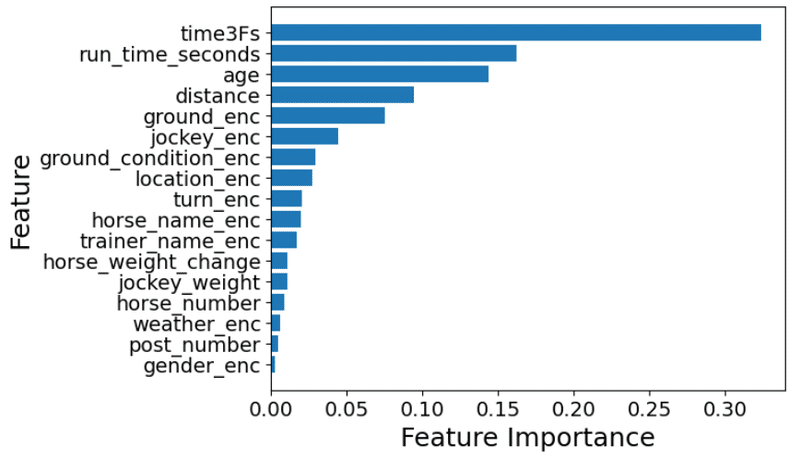
plt.show()決定木モデルのメリットは、予測モデルの精度に寄与している説明変数の重要度を定量化できる点です。ということで、こちらも描画してみます。
上がり3ハロン、タイムが影響力ありそうです。
#決定木の可視化を行う
from sklearn.tree import export_graphviz
import graphviz
# feature_namesリストを作成する
feature_names = X.columns.drop("year")
# 決定木の見える化を行う
tree_data = export_graphviz(model_DTC, out_file=None, class_names=["0", "1"],
feature_names=feature_names, impurity=False, filled=True)
graphviz.Source(tree_data)今回データがかなり多く壮大なツリーとなってしまいましたので、代わりにirsのデータセットでためしてみた時のツリーを以下に乗せます。決定木の分割の可視化を行うとすごくわかりやすいです。

次は、ランダムフォレストを試してみます。
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
#ランダムフォレストでmax_depthハイパーパラメータの違いによる正解率をグラフで表してみる
#max_depthの値の範囲を指定する
depth_list = [i for i in range(1,20)]
#正解率を格納する空リストを作成
accuracy_RFC = []
#max_depthを変えながらモデルを学習
for max_depth in depth_list:
model_test_RFC = RandomForestClassifier(max_depth = max_depth, random_state=42)
model_test_RFC.fit(train_X, np.ravel(train_y))
accuracy_RFC.append(model_test_RFC.score(test_X, test_y))
print(accuracy_RFC)
#正解率を可視化する
plt.plot(depth_list, accuracy_RFC)
plt.xlabel("max_depth")
plt.ylabel("RandomForestClassifier accuracy")
plt.xticks([2,4,6,8,10,12,14,16,18,20])
plt.title("RandomForestClassifier accuracy by changing max_depth")
plt.show()
#深さ18でランダムフォストでモデルを構築する
model_RFC = RandomForestClassifier(max_depth = 18)
#モデルに学習させる
model_RFC.fit(train_X, np.ravel(train_y))
#test_xに対するモデルの評価を行う
y_pred_RFC = model_RFC.predict(test_X)
#算出したy_predとtest_yの正答率を出す
RandomForestClassifierScore = metrics.accuracy_score(test_y,y_pred_RFC)
print(f"RandomForestClassifierScore: {RandomForestClassifierScore}")
#予測モデルの説明変数の重要度の可視化を行う
#決定木モデルの最も有益な点として、予測モデルの精度に寄与している説明変数の重要度を定量化できる点が挙げられる
#今回構築したモデルの説明変数の重要度を確認してみる
feature = model_RFC.feature_importances_
indices = np.argsort(feature)
# yearを除くデータフレームのカラム名を取得
column_names = X.columns.drop("year")
# 特徴量の重要度の棒グラフを描画する
plt.barh(range(len(feature)), feature[indices])
plt.yticks(range(len(feature)), [column_names[i] for i in indices], fontsize=14)
plt.xticks(fontsize=14)
plt.ylabel("Feature", fontsize=18)
plt.xlabel("Feature Importance", fontsize=18)
plt.show()簡単ですが、こちらも何をしているか説明をつけています。
#ランダムフォレストでmax_depthハイパーパラメータの違いによる正解率をグラフで表してみる
#max_depthの値の範囲を指定する
depth_list = [i for i in range(1,20)]
#正解率を格納する空リストを作成
accuracy_RFC = []
#max_depthを変えながらモデルを学習
for max_depth in depth_list:
model_test_RFC = RandomForestClassifier(max_depth = max_depth, random_state=42)
model_test_RFC.fit(train_X, np.ravel(train_y))
accuracy_RFC.append(model_test_RFC.score(test_X, test_y))
print(accuracy_RFC)
#正解率を可視化する
plt.plot(depth_list, accuracy_RFC)
plt.xlabel("max_depth")
plt.ylabel("RandomForestClassifier accuracy")
plt.xticks([2,4,6,8,10,12,14,16,18,20])
plt.title("RandomForestClassifier accuracy by changing max_depth")
plt.show()こちらも、決定木同様、ある範囲でmax_depthを動かしそれぞれの値での正答率を可視化しています。以下のようになりました。max_depth=18が精度がよさそうです。

#深さ18でランダムフォストでモデルを構築する
model_RFC = RandomForestClassifier(max_depth = 18)
#モデルに学習させる
model_RFC.fit(train_X, np.ravel(train_y))
#test_xに対するモデルの評価を行う
y_pred_RFC = model_RFC.predict(test_X)
#算出したy_predとtest_yの正答率を出す
RandomForestClassifierScore = metrics.accuracy_score(test_y,y_pred_RFC)
print(f"RandomForestClassifierScore: {RandomForestClassifierScore}")ランダムフォレスト、max_depth=18でモデルを構築し、正答率を出しておきます。

#予測モデルの説明変数の重要度の可視化を行う
feature = model_RFC.feature_importances_
indices = np.argsort(feature)
# yearを除くデータフレームのカラム名を取得
column_names = X.columns.drop("year")
# 特徴量の重要度の棒グラフを描画する
plt.barh(range(len(feature)), feature[indices])
plt.yticks(range(len(feature)), [column_names[i] for i in indices], fontsize=14)
plt.xticks(fontsize=14)
plt.ylabel("Feature", fontsize=18)
plt.xlabel("Feature Importance", fontsize=18)
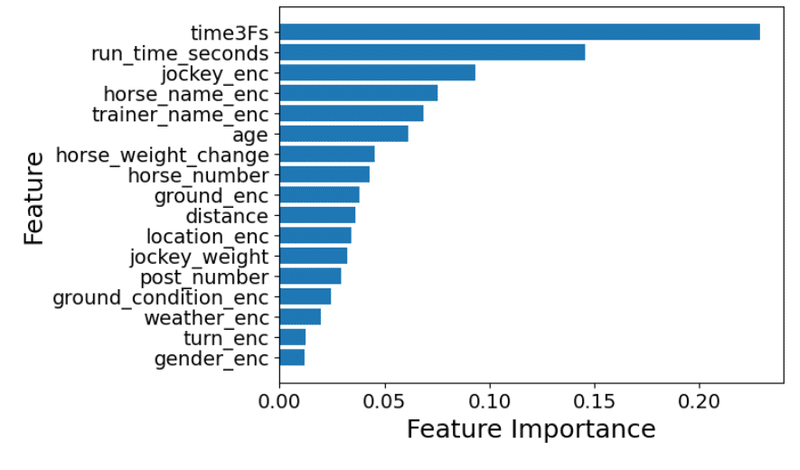
plt.show()ランダムフォレストについても、説明変数の重要度を可視化してみます。
上位2つは決定木と一緒ですが、3位以降が結構順位が違います。
では次に、LightGBMで構築をしてみます。パラメータは適当に数個設定してみます。
#LightGBMで予測を行う
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import lightgbm as lgb
import optuna
from sklearn.metrics import accuracy_score
# LightGBMで学習するためのデータ形式に変換する
lgb_train_test = lgb.Dataset(train_X, train_y)
lgb_valid_test = lgb.Dataset(test_X, test_y)
params = {
'objective': 'binary', # 二値分類
'metric': 'binary_error',# 損失関数にbinary_loglossを使用
}
# LightGBMでモデル構築を行う
model_LGB_test = lgb.train(params, lgb_train_test)
# test_xに対するモデルの評価を行う
y_pred_LGB_test = model_LGB_test.predict(test_X)
y_pred_index = (y_pred_LGB_test >= 0.5).astype(int)
# 算出したy_pred_indexとtest_yの正答率を出す
LightGBMScore_without_adjustment = metrics.accuracy_score(test_y, y_pred_index)
print(f"LightGBMScore without adjustment: {LightGBMScore_without_adjustment}")
#Light GBMの特徴量の需要度をプロットする
lgb.plot_importance(model_LGB_test, height=0.5, figsize=(4,4))こちらも簡単に説明をつけます。
# LightGBMで学習するためのデータ形式に変換する
lgb_train_test = lgb.Dataset(train_X, train_y)
lgb_valid_test = lgb.Dataset(test_X, test_y)まず、データをLightGBMで学習するための形式に変換します。
params = {
'objective': 'binary', # 二値分類
'metric': 'binary_error',# 損失関数にbinary_errorを使用
}ハイパーパラメータを二つ設定してみました。
分類、回帰によってパラメータが違いますし、二値分類か多項分類かによっても設定すべきパラメータが違いますので、この点注意です。
# LightGBMでモデル構築を行う
model_LGB_test = lgb.train(params, lgb_train_test)
# test_xに対するモデルの評価を行う
#確率をラベルに変換する。y_pred_LGB_test をしきい値0.5で二値化する、予測された確率が0.5以上であれば1となり、それ以外の場合は0とする。
y_pred_LGB_test = model_LGB_test.predict(test_X)
y_pred_index = (y_pred_LGB_test >= 0.5).astype(int)
# 算出したy_pred_indexとtest_yの正答率を出す
LightGBMScore_without_adjustment = metrics.accuracy_score(test_y, y_pred_index)
print(f"LightGBMScore without adjustment: {LightGBMScore_without_adjustment}")LightGBMでモデルを構築します。とてもトリッキーだと思ったのが、text_Xをモデルに突っ込んでy_pred_LGB_testを算出した時、この値は確率値になっているのでy_pred_indexで、0.5を閾値に二値化する部分です。0.8超えと、なかなかいいスコアのように思います。

#Light GBMの特徴量の需要度をプロットする
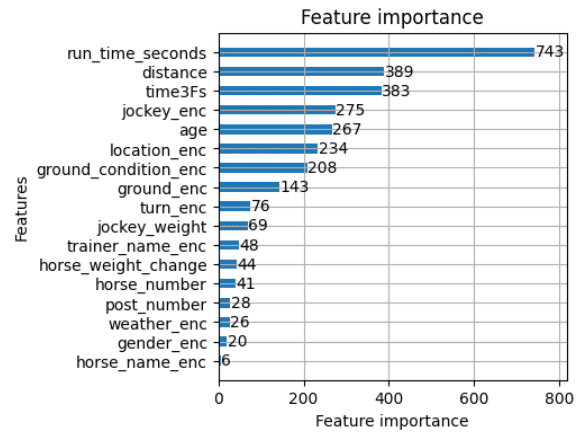
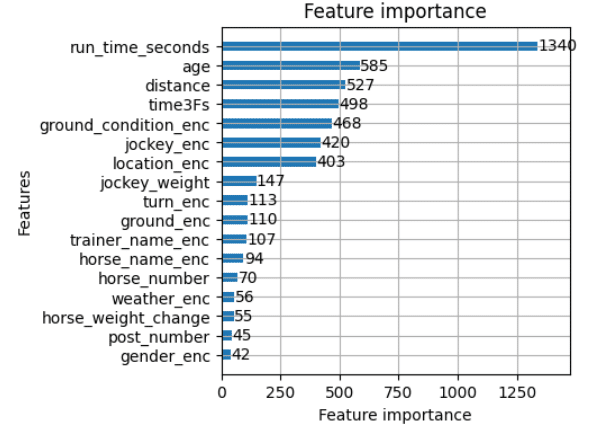
lgb.plot_importance(model_LGB_test, height=0.5, figsize=(4,4))こちらも特徴量の重要度を出してみます。タイムが圧倒的に影響ありそうです。次いで、距離・上がり3ハロンのタイムが続いています。
では、最後にLightGBMでOptunaというハイパーパラメータを最適化してくれるライブラリを用いて正答率をだしてみようと思います。
#LightGBM、optunaでハイパーパラメータを最適化してみる
#LightGBMで予測を行う
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import optuna
from sklearn.metrics import accuracy_score
import optuna.integration.lightgbm as lgb
#LightGBMで学習するためのデータ形式に変換する
lgb_train = lgb.Dataset(train_X, train_y)
lgb_valid = lgb.Dataset(test_X, test_y)
#LightGBM、optunaでハイパーパラメータを最適化してみる
params_adjust = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': {'binary_logloss', 'binary_error'},
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'num_iterations':20
}
# LightGBMでモデル構築を行い、パラメータを最適化する
model_LGB = lgb.train(params_adjust, lgb_train, valid_sets=[lgb_valid])
best_params = model_LGB.params
best_params
#最適化したパラメータでLightGBMを構築する
#LightGBMで予測を行う
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.metrics import accuracy_score
import lightgbm as lgb
##LightGBMでモデルを構築する
# XGBoostで学習するためのデータ形式に変換する
lgb_train_adjust = lgb.Dataset(train_X, train_y)
lgb_valid_adjust = lgb.Dataset(test_X, test_y)
# LightGBMでモデル構築を行う
model_LGB_adjust = lgb.train(best_params, lgb_train_adjust, valid_sets=[lgb_valid_adjust])
# test_xに対するモデルの評価を行う
#確率をラベルに変換する。y_pred_LGB_test をしきい値0.5で二値化する、予測された確率が0.5以上であれば1となり、それ以外の場合は0とする。
y_pred_LGB_adjust = model_LGB_adjust.predict(test_X)
y_pred_index_adjust = (y_pred_LGB_adjust >= 0.5).astype(int)
# 算出したy_pred_indexとtest_yの正答率を出す
LightGBMScore_with_adjustment = metrics.accuracy_score(test_y, y_pred_index_adjust)
print(f"LightGBMScore_with_adjustment: {LightGBMScore_with_adjustment}")
#Light GBMの特徴量の需要度をプロットする
lgb.plot_importance(model_LGB_adjust, height=0.5, figsize=(4,4))ハイパーパラメータを最適化してくれるなんて素敵!と思い、試してみました。
#LightGBM、optunaでハイパーパラメータを最適化してみる
#LightGBMで予測を行う
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import optuna
from sklearn.metrics import accuracy_score
import optuna.integration.lightgbm as lgb
#LightGBMで学習するためのデータ形式に変換する
lgb_train = lgb.Dataset(train_X, train_y)
lgb_valid = lgb.Dataset(test_X, test_y)
#LightGBM、optunaでハイパーパラメータを最適化してみる
params_adjust = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': {'binary_logloss', 'binary_error'},
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'num_iterations':20
}
# LightGBMでモデル構築を行い、パラメータを最適化する
model_LGB = lgb.train(params_adjust, lgb_train, valid_sets=[lgb_valid])
best_params = model_LGB.params
best_paramsimport lightgbm as lgbをimport optuna.integration.lightgbm as lgbに変更することにより、lgb.trainでパラメータを最適化してくれます。
best_paramsに返ってきたパラメータは以下です。

#最適化したパラメータでLightGBMを構築する
#LightGBMで予測を行う
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import optuna
from sklearn.metrics import accuracy_score
import lightgbm as lgb
##LightGBMでモデルを構築する
# XGBoostで学習するためのデータ形式に変換する
lgb_train_adjust = lgb.Dataset(train_X, train_y)
lgb_valid_adjust = lgb.Dataset(test_X, test_y)
# LightGBMでモデル構築を行う
model_LGB_adjust = lgb.train(best_params, lgb_train_adjust, valid_sets=[lgb_valid_adjust])
# test_xに対するモデルの評価を行う
#確率をラベルに変換する。y_pred_LGB_test をしきい値0.5で二値化する、予測された確率が0.5以上であれば1となり、それ以外の場合は0とする。
y_pred_LGB_adjust = model_LGB_adjust.predict(test_X)
y_pred_index_adjust = (y_pred_LGB_adjust >= 0.5).astype(int)
# 算出したy_pred_indexとtest_yの正答率を出す
LightGBMScore_with_adjustment = metrics.accuracy_score(test_y, y_pred_index_adjust)
print(f"LightGBMScore_with_adjustment: {LightGBMScore_with_adjustment}")最適化されたパラメータを入れて再度LightGBMモデルを構築し、正答率を出してみます。ぎょぎょ・・・パラメータ最適化前より下がっている・・・!?

#Light GBMの特徴量の需要度をプロットする
lgb.plot_importance(model_LGB_adjust, height=0.5, figsize=(4,4))こちらも説明変数の重要度を描画してみます。タイムがダントツです。
5.評価
上で試した4つの方法を比較してみます。
print(f"DecisionTreeClassifierScore: {DecisionTreeClassifierScore}")
print(f"RandomForestClassifierScore: {RandomForestClassifierScore}")
print(f"LightGBMScore without adjustment: {LightGBMScore_without_adjustment}")
print(f"LightGBMScore_with_adjustment: {LightGBMScore_with_adjustment}")以下のような結果になりました。

LightGBMはKaggleでもよく使われているということなので、決定木やランダムフォレストよりも精度は高いのかな、と思っていました。が、まさかのLightGBM+ハイパーパラメータ調整が、適当にパラメータを設定したLightGBMよりも精度が落ちるとは思っていませんでした。Optuna使ったからこれで最強!!オッケー!!というわけではなさそうです。
Optunaを使用することにより精度が向上が期待されますが、以下のような理由でそうとも限らないようです。
・ハイパーパラメータの範囲設定
・評価関数の選択
・データの特性 etc…
ということで、複勝で回収するには、現状LightGBMで予測した方が回収率がよさそうですが、また今後さらに回収率をあげるためにはLightGBMのハイパーパラメータを再度調整したり、いらない特徴量を削除して精度の高いモデルを構築して予測する必要がありそうです。
所感
Webで色々とさがしてみると、競馬や競艇のAIモデル分析をされている方がたくさんいらっしゃり、私もやってみたい!!!しかしコードを見ても何もわからない!!(汗)という状態でしたが、何とか講座を一通り終えて、なんとなーく自分でも実装できるようになり感無量です。
スクレイピングから始まり、データ加工、モデル構築と機械学習やデータ分析の基本となる要素がちりばめられており、初学者にとってはかなりハードな課題でした。。。
今回無料のデータとしては一部のデータしかとれなかったのですが、今後血統、騎手相性、コース相性等、普段自分で検討しているときに使っている特徴量も加えて予測してみたいと思います。
この記事が気に入ったらサポートをしてみませんか?