
クラスタリングと回帰分析を組み合わせたら来客数予測がいい感じになったので学会で発表しました

こんにちは。
株式会社Goals AIチームマネージャーの山口です。
本記事は前回の記事でもお伝えしたとおり、予測精度改善の実証実験の結果を学会で発表してきたので、その内容について記載します。
概要はプレスリリースの方にまとまっていますが、本記事はもう一歩踏み込んで、学会当日の様子や、発表資料を元にした実験手法の説明など、詳細をお伝えしていきたいと思います。
以下のような方に向けた記事になっています。
回帰モデルを扱っているAIエンジニアの方
特に、特定の条件下のデータが少なくて精度が上がらず困っている方
学会を通じて社会貢献することに関心が高いAIエンジニアの方
社会実装に興味があるAIエンジニアの方
上記に該当しないAIエンジニアの方や、AIよく分からないって方でも、単に読み物としても面白いものになるように執筆したつもりですので、ぜひお付き合いいただければ幸いです。
学会について
学会の概要
学会名 : 第17回行動変容と社会システム研究会 (in WSSIT2023)
開催日時 : 2023年3月10日(金) 14:00-15:45
開催場所 : ルスツリゾートホテル&コンベンション
会場 : コンベンションホール 18番
当日の様子
会場は披露宴とかパーティーとかやれる感じのホールでした。
写真は開始前の会場です。

席がいっぱいあって、どのくらい人が来るのかドキドキしてましたが、発表者含め全部で20人に満たない程度、プラス、オンライン参加の数名といった規模感でした。
手違い(メールのサイズ?)で当日の説明資料が添付されたメールが届かなかったので、どういった形で発表するのか分からず、HDMIケーブルで自分のPCを繋ぐのか、USBメモリにファイル入れて使うのか、なんてあれこれ考えていたのですが、Zoomに入って画面共有するだけと聞いて「イマドキ!」と感じてしまった41歳(厄年)です。
学会の発表なんて20年近く前に1回やっただけ。
さらにトップバッター。
なので、なんかもうガチガチに緊張してましたが、これでお給料もらってるんだ!という使命感を胸に、いざ登壇!!


これは1枚目のスライドです。
「これは何の数字か分かりますか?」
という質問を投げかけて、会場の心をキャッチするという戦略でしたが、見事に反応が薄くて、冷や汗をかき始めてる様子です。
ちなみに正解は、食品産業で廃棄している食材の量です。
この後も、フードロスは社会問題になっていて、この削減に取り組んでいるのが弊社Goalsなんです、という自己紹介をしていくわけですが、最初でスベってるので空気が固く、話しづらくて仕方なかったです。
しかし!
そこで私を助けてくれた人がいます!
そう!私が恋をしたHANZOくんです!

HANZOの紹介(宣伝)をしていたときに、「今日Tシャツで着てきたこれです!」とアピールしたところ、小笑いが起きて会場の空気が和らいだ感じがしました。
ここでようやく平常心を取り戻せた気がします。
後は練習通り話すだけ、ということで、問題なくやれたのではないかと思います。(内容については、次の章で説明します)



感想
一言でいうと、とても素晴らしい経験ができた、に尽きます。
質疑応答でハッとさせられる質問を頂いたり、他の方の発表を聞いて得られた情報があったり、優秀な学生さんと会話できたり、とても刺激的な1日になりました。
内にこもって黙々と精度改善に励むのも悪くはありませんが、こういった外部のコミュニティとの繋がりはとても有意義だと実感しましたので、今後はもっと社交的に活動していきたいと強く思いました。
論文(発表内容)について
概要
タイトル : 飲食店における人員配置と食材発注の最適化に向けた確率的潜在意味解析と回帰分析の組み合わせによる来客数予測方法の評価
著者 :
株式会社Goals 山口 真吾、井上 慎太郎、及川 伸
株式会社クリアタクト 石田 和宏
産業技術総合研究所 人工知能研究センター 豊田 俊文、本村 陽一
要旨 : レストランなどのサービス業において、来客数の予測精度が重要であるが、年末年始やGWなど過去のデータが少ない特殊な日付の場合に精度が低下する。本実験では、クラスタリングと線形回帰を組み合わせた予測手法を提案し、精度向上を実現した。
掲載先 : 情報処理学会電子図書館
(ダウンロードにはユーザー登録が必要です。)
実験の動機
飲食店では予測した来客数を元に発注する食材の量や従業員のシフト作成を行っているので、その来客数予測の精度が重要になります。
来客数を多く予測してしまうと・・・
必要以上に食材を発注してしまう → フードロスの発生リスク
過剰に店舗人員を配置 → 人件費上昇
来客数を少なく予測してしまうと・・・
発注量を少なくしすぎて食材が足りなくなる → 販売機会損失
配置人数が不足 → サービスレベル低下
なので、多すぎず少なすぎない来客数予測が必要なのですが、人手で行うのは考える要素(天気、曜日、祝日、店舗周辺イベント等)が多くて大分シンドイ作業であり、経験も必要になります。
そこで機械学習の出番になるわけですが、機械学習にも苦手なケースがあります。
それは年末年始やGW、お盆といった、通常時とは明らかに来客数が変化する期間です。
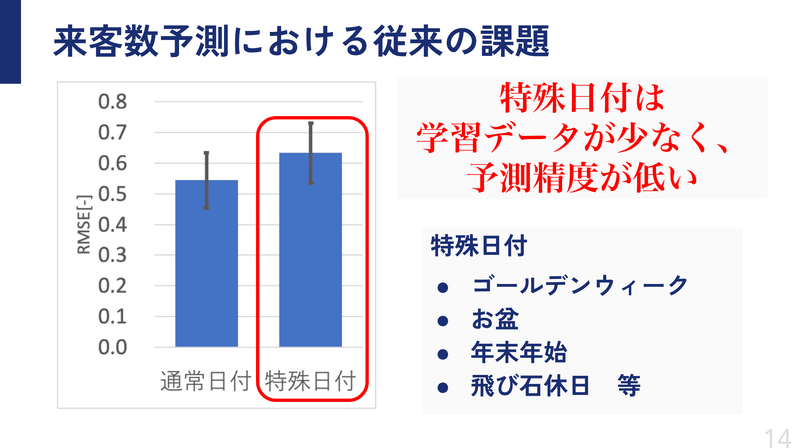
機械学習はデータが命なわけですが、このような特殊な日付はそもそもデータ数が少ないので、どうしても予測精度が悪化してしまう傾向にあります。
そこを何とかしたい、というのが実験のモチベーションになっています。
提案手法
『データが少ないんなら、似たような店舗を集めて、まとめて学習させれば精度上がるんじゃない?』
という仮説から、クラスタリングと線形回帰を組み合わせる手法でアプローチしました。
(この手法には名前がまだ無いので、かっこいい名前募集中です)
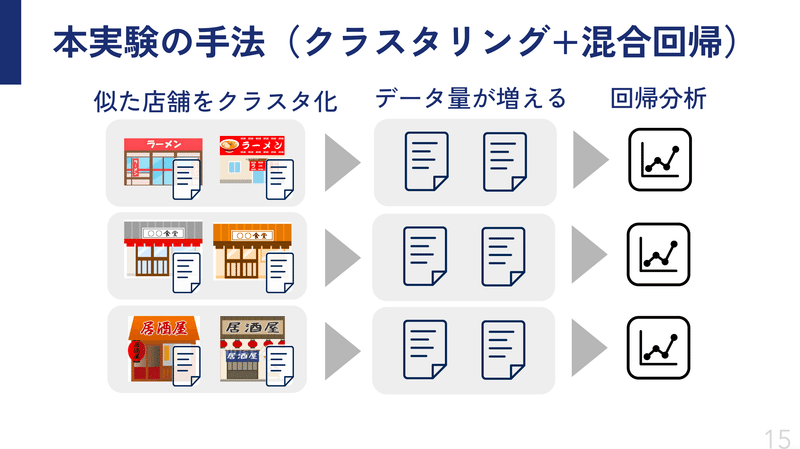
クラスタリングにも色々な手法があるので、何を用いるかが大事なわけですが、今回は確率的潜在意味解析(PLSA)を採用しました。
確率的潜在意味解析(PLSA)によるクラスタリング
あまり馴染みがない方が多いのではないかと思いますが(私も本実験を行う前は知りませんでした)、行xと列yの2つの軸でクラスタリングできる手法です。今回はxに日付、yに店舗を置き、ディナー来客数をクロス集計して作成した共起行列を用いました。

こうすることで、日付と店舗を同時に、似たディナー来客数の動きをするグループに分けることができます。

ただ、PLSAは潜在クラス数(グループの数)を事前に決定しておく必要があります。
最適な潜在クラス数を求めるため、AICが最小になるグループ数を探索するのですが、PLSAは初期値依存性があり、初期値の設定で結果が変わってしまうため、グループ数を変えながら異なる初期値で何度か試行しました。
今回の実験では3業態110店舗で行いましたが、得られた結果からAICが最小、かつ、値のバラツキが小さい安定した潜在クラス数24を採用することにしました。
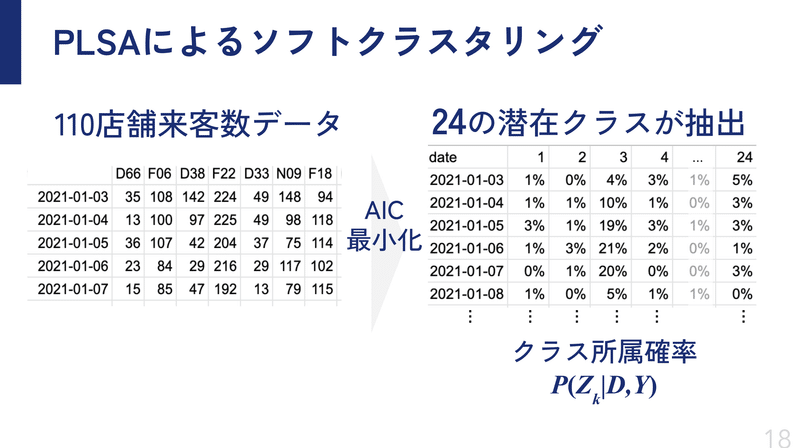
なぜPLSAを採用したかといいますと、次のようなメリットがあると考えたからです。
より適切に潜在クラスのデータ数を増やすことができる
店舗と日付の2つを同時にクラスタリングできるため、例えばお盆とゴールデンウィークで同じような来客数の動きをする店舗があった場合、どちらも同じ潜在クラスに所属する確率が高くなります。
同じ潜在クラスになるということは、そのクラスのデータ数が多いということになります(厳密には、ソフトクラスタリングなのでデータ数が多いというのは違うのですが、簡単のため、こういった表現を使用します)。
他のクラスタリング手法では、店舗と日付を同時にクラスタリングはできず、片方をベースにもう片方をクラスタリングすることになるため、似た店舗でクラスタリングしようとすると、お盆のデータとGWのデータは別クラスにするしかありません。
別クラスなので、1クラスあたりのデータ数は減ってしまいます。
PLSAの方が、元々の目的である、データ数を増やすことで予測精度を向上させる狙いに合致していると言えます。
今回の手法で高い解釈性を得られる
潜在クラスを分析するときに、PLSAでは店舗と日付の2軸で見ることができるため、何のクラスなのかを解釈しやすくなります。
さらに今回の手法では、日付の属性と結びつけて、より細かい特徴を捉えることに成功しています(詳しくは後述の[余談]潜在クラスの特徴をご参照ください)。
ビジネスにおいて、解釈しやすい=説明がつくというのはとても大事です。
「なんかよく分からないけど、明日は100人来ます」より、「こういった理由で明日の来客数は100人来ます」と言えたほうが、安心感や信頼性がずっと高いですよね。
分析から得られた知見から、コンサルティングや新たなビジネスに繋げることも考えられるので、解釈性が高いのは大きなポイントです。
ソフトクラスタリングなので全情報を活用できる
ハードクラスタリングでは、最もそれらしいクラスに分類されたら、他のクラスの要素を活用することができません。
例えば、オフィス街の店舗と住宅街の店舗、2つのクラスがあった場合、オフィス街と住宅街の中間に位置する店舗はどちらに入るのが正しいでしょうか?
本当に中間なら半分ずつにしたいし、オフィス寄りなら6:4にしたいなど、1か0かでなく、比率でどちらにも所属したいケースは多いのではないかと思います。
ハードクラスタリングでは、どちらかに所属するしかなくなるので、特定の店舗ではひどく精度が悪化する恐れがあると考え、ソフトクラスタリングを採用しました。
多項ロジスティック回帰による新規日付の所属確率計算
PLSAによって過去の店舗と日付のクラスタリングはできました。
なので、学習はこれでOKなのですが、予測にあたっては未来日付の潜在クラス所属確率が必要になります。
今回は多項ロジスティック回帰で、未来日付のクラス所属確率を推定するモデルを作成しました。
つまり、日付の属性を渡すと、各潜在クラスへの所属確率を予測してくれる回帰モデルです。
PLSAで得られたクラス所属確率を目的変数、過去データの日付属性を説明変数として係数行列Aと切片Bを求めました。

ディープラーニングを扱っている方には、「隠れ層が無いニューラルネットワークの活性化関数にソフトマックス関数を適用したもの」と言った方が分かりやすいかもしれませんね。
日付の属性は下図の通りです。該当すれば1、しなければ0を設定しました。

[余談]潜在クラスの特徴
実際に求めた係数行列と切片を見ると面白いことがわかるので、ちょっと紹介します。
日付の属性と各潜在クラスの関係を見ることができ、潜在クラスの特徴を推定することができます。
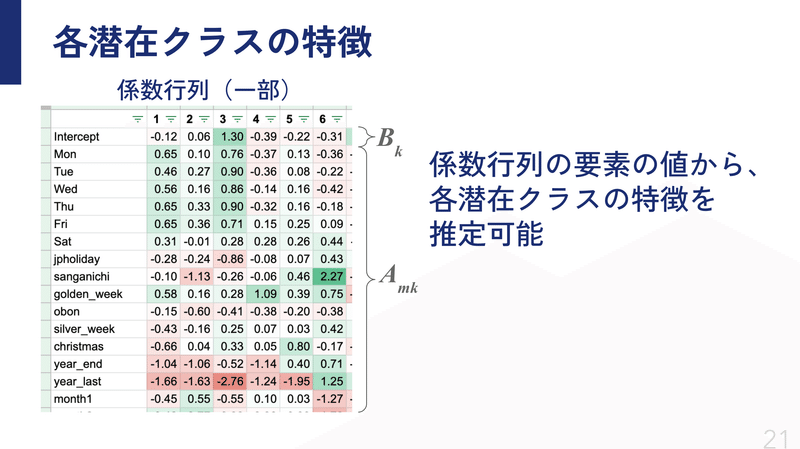
例えばクラス3ですが、切片と平日の係数が高いので、平常時を表すクラスではないか?であったり、

クラス6は三ヶ日や年末の係数が高いので、年末年始に来客数が増えるクラスっぽいぞ、といった具合です。
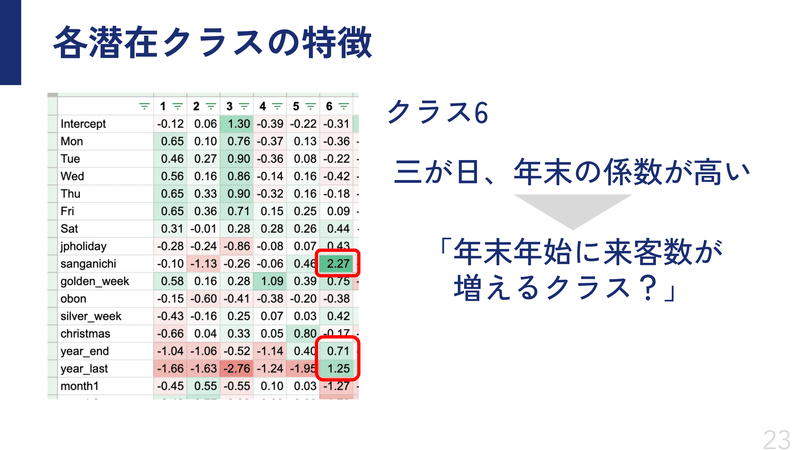
このように分析することができるのも、今回の手法の利点です。
混合回帰で来客数予測
ここまでで得られた結果を元に、混合回帰で最終的な来客数を予測します。
潜在クラスごとに過去データを学習させ、回帰モデルを作成します。
この時、学習に使うデータは全データ(全店舗・全日付)で、PLSAで得られた所属確率で重み付けして学習させます。
そして、それぞれの予測値を多項ロジスティック回帰で得られた未来日付の所属確率で按分して、最終的な来客数を計算します。
下の図は、実際は24クラスありますが、ここでは簡単のため3クラスにしています。

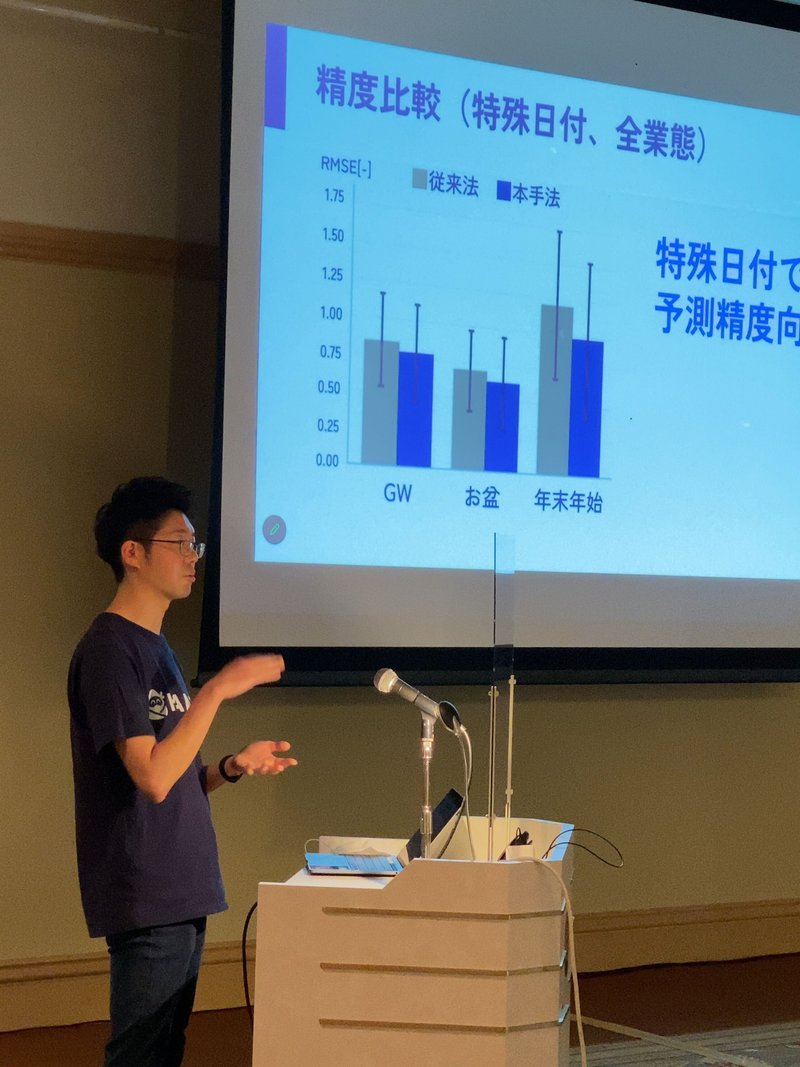
結果
まずは通常日付と特殊日付を合わせた結果がこちらになります。
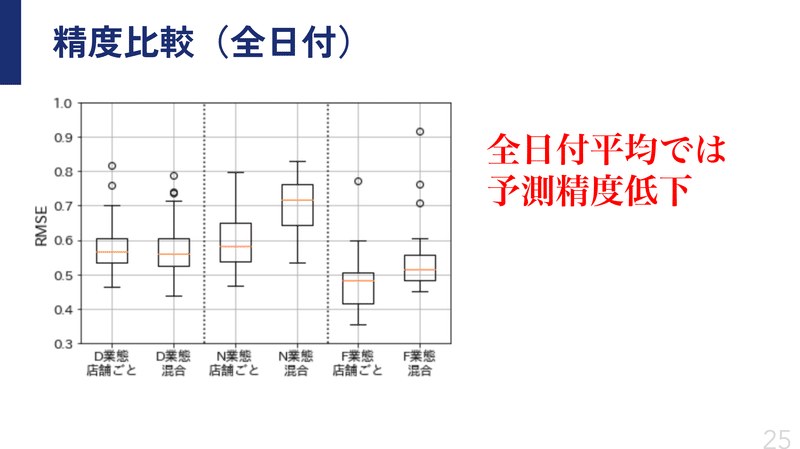
RMSEで精度比較した場合、D業態は少しだけ改善傾向が見られましたが、その他2業態は予測精度が低下してしまいました。
D業態だけ改善した点については、今回使用したサンプルデータでD業態が他の業態より店舗数が多いことが一因にありそうです。
比率でいうとデータの半分以上がD業態だったため、他2業態がD業態に引っ張られた予測となり、その分精度が悪化したと考えられます。
また、従来の店舗個別のみのデータを使用する手法よりも、今回の手法の方がどうしても平準化されてしまうので、その店舗特有の値の動きを追従しきれなかったのではないか、と考えています。
だがしかし!
それは想定内のこと。
肝心なGWや年末年始といった特殊日付では、どうだったかというと、
こちら!!
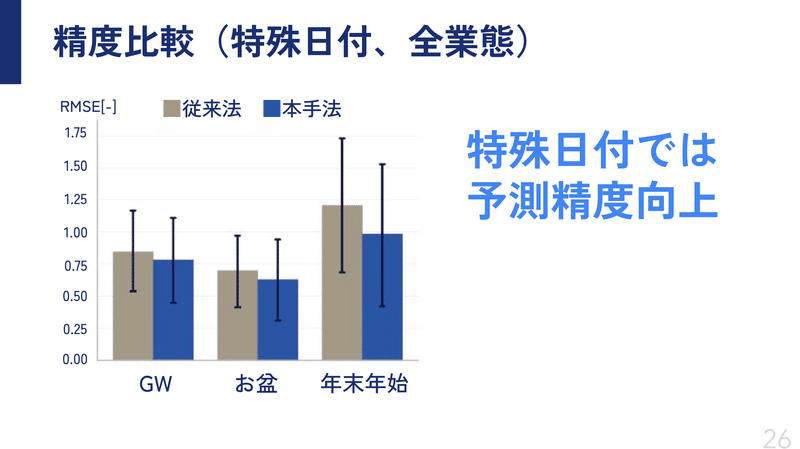
🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉
当初の狙い通り、特殊日付においては予測精度が向上しました!!
🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉
特に年末年始の改善が大きいのですが、これは他の大型連休と違って特殊な動き方をすることが多いので、今回の手法が効いたのでは無いかと思います。
まとめ
本実験では、来客数予測で従来の課題であった特殊な日付での精度低下問題に対し、PLSAによるクラスタリングと混合回帰を組み合わせた予測手法を試しました。
その結果、RMSEの比較で全店舗平均12%、一部店舗で平均63%の精度改善を確認できました。
本手法の有用性が確認できたので、この知見を今後はHANZOプロダクトに活かし、さらなる精度改善に取り組もうと思います!
おわりに
ここまでお付き合いいただき、誠にありがとうございました。
また悪いクセが出て、前回以上に長文になってしまいましたが、いかがでしたでしょうか。
この記事を読んで、「Goalsに興味が湧いた!」「自分も学会で発表したい!」「俺がもっとすごいことやってやんよ!」等々ございましたら、是非↓からカジュアル面談をお申し込みください!
弊社が誇るCTO多田があなたをお待ちしております。
募集職種一覧
https://goals.co.jp/recruit/jobs
この記事が気に入ったらサポートをしてみませんか?