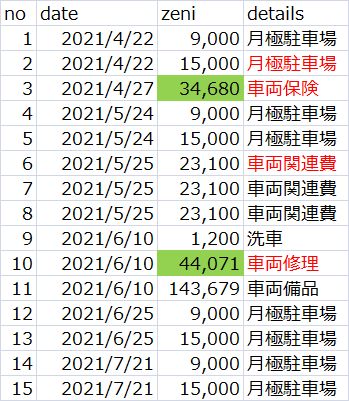
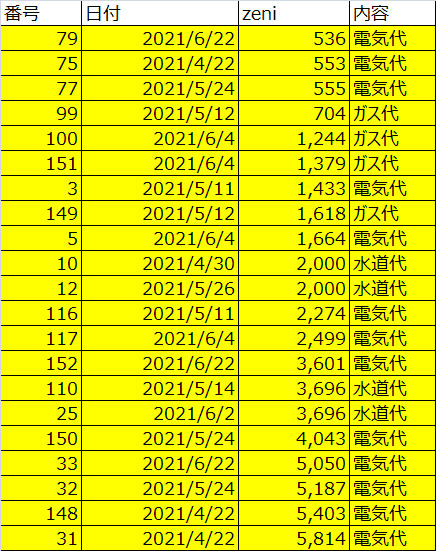
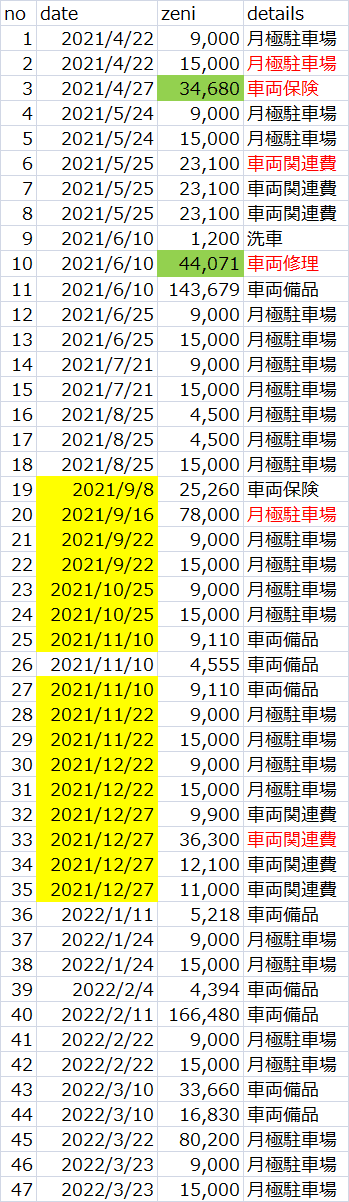
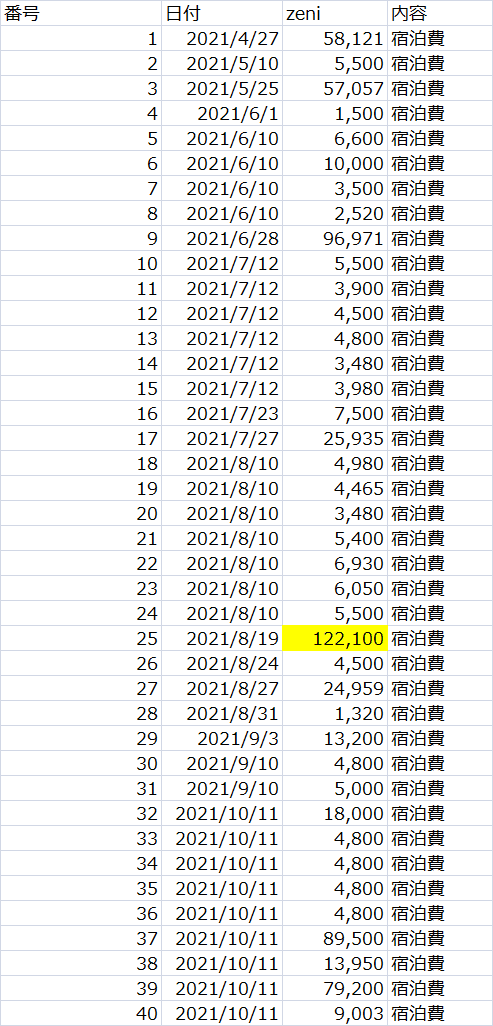
特定数値になる組み合わせ全抽出(部分和問題)を行う手順等

作成目的:
住民訴訟で提出された証拠に関して、実績報告値(総額)と支出明細の証拠との関係性を明らかにし、整合性を明確にする。
概要:[無償+Python+Excelで出来る範囲]
画像にされた表(直接テキスト抽出不可)をExcelファイル(データ)として扱える状態から組み合わせ分析という流れをまとめたもの。
対象となる範囲と処理特性:
データの状態および個数に依存して処理時間が掛かります。
逆に言うと、如何にして処理対象を減らすか、処理リソースを増やすか、その両方を追求することで処理時間を短縮できる特性があります。
なお、一覧表化した後の処理スクリプトとしては車両関係費程度であれば問題なく動きます。
STEP1 :エクセル起こしの手順
PDF画像から文字列へ変換する方法
Googleアプリからドライブを選択
PDFをドライブにドラッグアンドドロップ
リストされたPDFの上にカーソルを置いて右クリック
アプリで開く⇒Googleドキュメント
ワード形式なのでテキストに吐き出し
テキストエディタ(noteなど)で体裁が壊れているので整える
(手入力よりは楽だがそれなりに工数がかかる)【目的範囲を限定して】Excelにコピーして再修正
(桁ズレがあったり中国語になっていたりするので、全部一括でやるとやる気が無くなります)合計金額等で検算
簡易フィルタで「支出分類など」が壊れていないかチェック
STEP2 :目的の整理・確認
(組み合わせで調べる金額を「調査金額」と定義する)
選別した対象の合計額が、組み合わせを調べたい調査金額を下回っていないか
(そもそも確認する必要もなく、解なしという解が出ている)抽出したい組み合わせと調査金額はどのような期間を対象としているか、ソートして分類する必要はないか
(四半期などの区切りにあっているか)その組み合わせの対象費目(内容・適用)に不要なデータは無いか
(ガソリン代の確認に駐車場代は含めない)特定期間における毎月定額発生など固定的なものを調査金額と組み合わせ対象に含める意味はなく最初から組み合わせの中に存在するとして除外できるのではないか
調査金額を構成する要素として絶対に入らないことが分かる項目は無いか
(調査金額を超える項目や最大と最小を合算すると調査金額を超える場合に最大の方は組み合わせには絶対に入らないと言える)調査金額を構成する要素として絶対に入ることが分かる項目は無いか
STEP3 :データ特性の確認と適用するスクリプトの選択
(総当たり方式を除外できる要因があるか)
絞り込まれた対象データ数が小さい場合には全件総当たりでも問題なし
(データが20件程度なら総当たりで問題なし)重複データは多いか
(ホテル代など固定的な金額が複数ある場合、期間内に調査金額になる組み合わせにおいて何件含まれるパターンが存在するのかを把握することで100%なのかを検証することができるため、例えば50%や90%で個別発生の取捨選択を反映する価値は低い
100%でなければ何かが不足しているという問題が明確になるので最初から除外する方法もあるし、組み合わせの異常を見つけることもできる)下3桁に000が多いか
(高速化の一環で【スクリプト aa.py】では最初に下3桁の組み合わせ抽出を行って、残りの数字を探索するパターンとしている、固定的に使われるものを特定することで処理対象を限定する)多量の少額支出が並ぶ場合、組み合わせの数は必然的に増大することを念頭に置く
データ特性と入力データを削減する方法を考える。
(調査金額Aと要素X(i)の金額Bの合計が近い場合、C=B-Aを超える要素X(i)(X(i) >C)は必ず構成要素の中に入る。
調査金額AからX(i)を引いたものを新規の目標値A’として扱う
X(i)をリストから確定要素として除外する)
STEP4:特定組み合わせの存在(部分和問題)の確認
組み合わせ存在の有無を確認するものではありません。
存在確認のみの場合、全件総当たりfscd.pyを実行しコマンドプロンプトでリストが表示されたら処理途中で停止してください。結果表示1個以上=存在確認完了です。
様々なスクリプトをScript以下に並べています。
現状の最速はdfs-cut.pyでしょう。
処理スクリプトを選択
調査金額の設定(部分和の定義)
入力ファイルの設定(調整および指定等)
dfs-cut.pyの実行 (全件抽出)
出力先をgogobt.txtにリダイレクトbb2bt.pyの実行 (圧縮データ再展開)
cc2bt.pyの実行 (データ体裁調整)
出力先を任意にリダイレクト(拡張子 .csvに設定すればExcelで開けます)
Scripts
処理高速化スクリプト
入力
INPUT: sortBook2s.xlsx サンプル TARGET_SUM = 30879 調査金額
出力
アウトプットはgogobt.txtでリダイレクト設定して受けて下さい
バックトラッキング(高速化タイプ1)
それなりの速度だが一部データ補完が未完
36 unique INPUTS ⇒2時間以上
深さ優先探索(Depth-First Search) + 枝刈り(高速化タイプ2)
BackTrackよりも高速、データの網羅性はほぼ完全
36 unique INPUTS ⇒1.0分
Uniqueを1増やす毎に2倍程度の時間増加
動的計画法とソート足切り組み合わせ
単純処理では入力要素数が増えるとメモリーオーバーになる
以下、データ構造修正スクリプト(INPUTはgogobt.txt)
入力データを圧縮しているのでその構造の逆展開をするためのスクリプト
不要な文字列等の削除と体裁の修正
これらのスクリプトの基本形参照元は以下
全件総当たりスクリプト
すべてを処理しますが、時間が掛かります。
処理速度上昇版スクリプト
網羅性は高いがデータ量の上限はあまり上がっていない
25 unique INPUTS 程度
ETL設定を増やして処理しているため、特定条件下では他のものよりも早くなる可能性はあるもの(早いとは限らない)
データ調整および組み合わせ抽出ルーチン(INPUT: sortBook2.xlsx)
アウトプットはgogo.txtでリダイレクト設定して受けて下さい
過去のものを維持したい場合には名前を変更するなどして下さい
データ調整ルーチン(INPUT: gogo.txt)
出力ルーチン
(print出力を任意のファイル名でリダイレクト設定してください)
使用条件
コードは勝手にコピーして使用しないでください。以下の条件を設けています。
住民訴訟において東京都の支出承認内容に疑念を持ち、被告東京都の債務不足や不存在を明らかにするための確認作業をする場合に限って無償での使用を許諾し、処理速度対策上の制約の存在およびバグに対する補償がないことを合意の上で利用できるものとします。
Python環境の構築は自己責任で実行してください。レベルについては動かない場合には合わせてください。
高速化がされるかはデータ依存であることを理解できること。
手作業とデータ確認が必要で、ETLの基本を理解しているか盲目的に信用することが前提です。
スクリプト内のTARGET_SUMを調査金額(目標値)に設定する必要があります。
最初のシート目のzeni列を処理対象として固定化しています。Excelファイルを修正することが必要です。作成者の趣味です。
ファイル名を変えたい人はスクリプトを適宜修正できることが前提です。
エラー処理は個々に対応できることが前提です。
前方一致方式で突合結果を元データに反映するなどは設定していません。入力ファイルはRead onlyを想定しています。
Sample0 総当たりでも充分
特性:INPUT数が少ない
Sample1 高速化が有効なパターン
総当たりを使用すると18時間くらい掛かる(と思う)
各種高速化で1分~3分程度
特性:Uniqueデータ数が少ない。下3桁が000が多いなどのデータ特性が寄与する。
Sample2 高速化仕様の適用限界確認に使用したデータ
総当たりを使用すると15時間くらい掛かる(と思う)
各種高速化で1分~2時間程度
特性:Uniqueデータ数が多い、重複データが少ない。下3桁が000などの計算除外が有意に機能しない。
総データ個数:40
データ重複状況:6⇒3、3⇒2
accumulated: 4800.0, count: 6
extend: [4800.0, 9600.0, 19200.0]
accumulated: 5500.0, count: 3
extend: [5500.0, 11000.0]
調整後、総データ個数:36
Python環境の整備
以下のリンク先などを見て構築してみてください。
PC等の素人でも難しくないとは思います。
ライブラリの不足などにはご注意ください。
データ処理のお話
組み合わせ抽出そのものではない事前・事後処理のお話
データ処理の組合せ爆発問題
会計上のデータを確認する場合には、特定の金額が繰り返し出現することがあります。
全件抽出においては、例えば10円を1件と90円が1件と100円が100件含むデータがある場合に300円になる独立した組み合わせは
ケース① 10円+90円+100円+100円
ケース② 100円+100円+100円
の2件に見えますが、実際には100円には100円1番~100円100番があり、これを入れ替えた組み合わせが存在します。
これを全件検索すると、すべての要素を利用することになり、組み合わせ抽出工数が巨大化してしまいます。
100個の要素数の場合には
2の100乗=126穣7650𥝱6002垓2822京9401兆4967億0320万5376回の試行が最大値になります。読めない人の方が多そうな桁数です。
効率化する方法
入れ替わりを厳密に捉えようとすると100円の1番なのか2番なのかを把握する必要が出ますが、そんなものは後で出来ることと割り切ると以下の方法が取れます。
2のn乗倍の代替表現による組み合わせ抽出対象の削減
100件の同一データ(100円)がある場合には
100円と200円と400円と800円と1600円と3200円と6400円に置き換えることで抽出対象となるデータ(要素数)を削減することができます。
300円は100+200で表現できます。5000円は3200+1600+200です。
5000円のケースでは2の5乗(32)と2の4乗(16)と2の1乗(2)を100円に掛け算した値であることが分かります。
組み合わせに使用される要素数ではなく合計値を基準として計算することで、100円100個を表現するには要素数がn=0,1,2,3,4,5,6の7個(2のn乗)で良いことが分かります。
これにより処理対象となる要素数を93個削減できます。
具体的には合計値300円を調べるケースでは
100円+200円
10円+90円+200円
の2個が解として抽出されます。
後は、この200円をどの100円の2個に逆展開するかということになりますが、具体的な違い(属性)は人が判断しても足りるレベルのことです。
今回のケースではひとつの対処法としてデータ処理を追加しています。
3個以上の重複から効果があります。
なお、数値の独立性維持を考慮した完全なプログラム処理に落とし込むには1次元的な処理ではなく複数次元に合わせ任意回数のループでデータ圧縮(削減)と逆展開する必要がありますが、そこはひとまず放置しています。
参考:入力PDFの状態
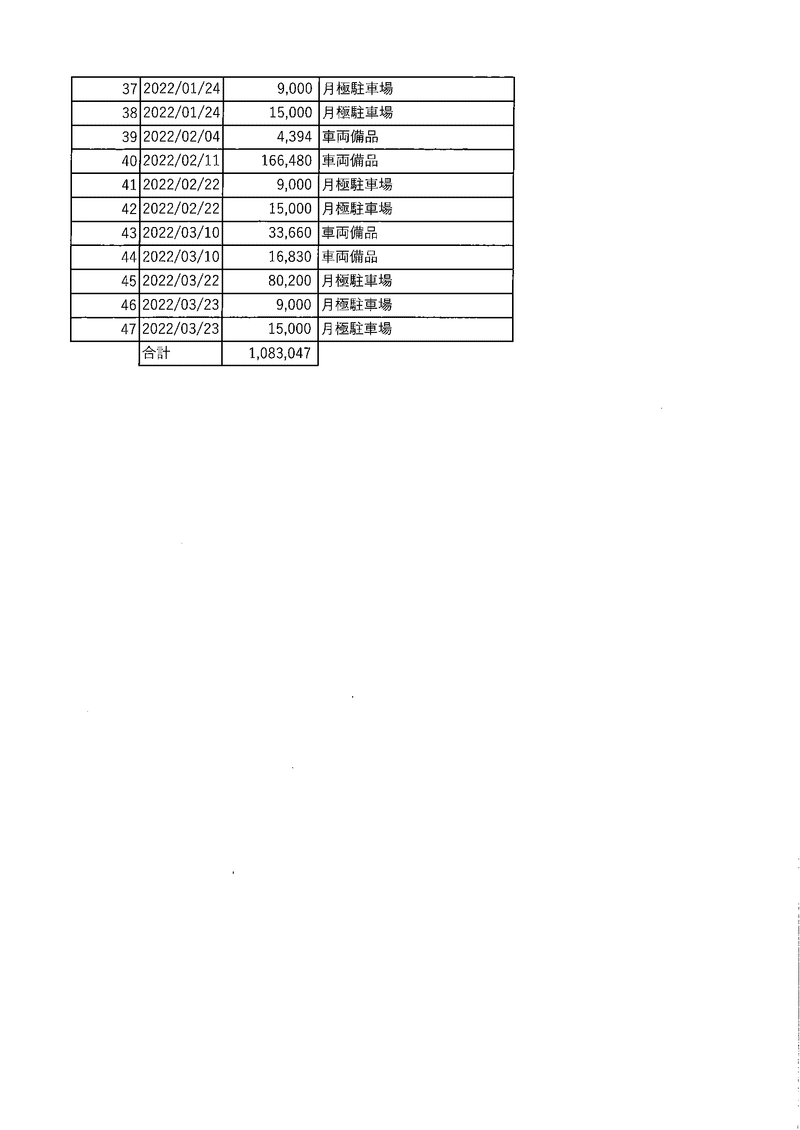
暇な空白 noteの有料部分にある書面(別表)より一部抜粋引用
あとがき
Pythonか、触ったことがないプログラミング言語だ、という状態から作って直してしているのですべてのライブラリやメソッドを駆使するところまでは行ってない。と思う(必要がない可能性の方が高い)。
ライブラリもメソッドも検索で知ることができるし、今は言語を覚えるハードルは低いと思う。