
Style-Bert-VITS2 のAPIで複数話者の会話【台本はChatGPTに書いてもらおう】AITuber制作の備忘録2

前回の記事の続きになります
前回、台本を作成し、それを「Style-Bert-VITS2」のAPIを使用して複数話者で読み上げるところまで実現しました。今回は、発話に合わせてLive2Dモデルのリップシンクを実装してみました。
今回の成果物はこちらです。
いつも前提を書き忘れがちなので、ここに記しておきます。
AITuberプログラム(Python)
音声合成には「Style-Bert-VITS2」のAPIを使用
キャラクターはVTube Studio(Live2Dモデル)
OBS Studioに出力
配信に関して「OBS Studio」が出力をまとめる役割を果たしています。
話者が1人の場合、プログラムの音声は無料の「VB-Cable」を使用してそのまま流し込めば良いのですが、複数話者の場合、キャラ毎に1人1人の音声の出力を分けなければなりません。
OBSに音声を流す際、多くの人が無料の仮想オーディオケーブル「VB-Cable」を利用していると思いますが、今回は音声出力の分岐の為に有料版の「VB-Cable A+B」を使うことにしました。
「VB-Cable A+B」は公式サイトの中ほどにあり、5~25ユーロで自分に合った金額で寄付による購入ができます。購入後、インストール。
ここで場合によっては再起動が必要です。サウンドデバイスに「VB-Cable A」と「VB-Cable B」が追加されていれば、準備完了です。
Pythonプログラムでは、まず以下のコードで自分のサウンドデバイスを確認します。
import sounddevice as sd
with open('sound_device.txt', 'w', encoding='utf-8') as f:
f.write(str(sd.query_devices()))これにより出力される「sound_device.txt」を確認し、
「CABLE-A Input (VB-Audio Cable A), Windows DirectSound (0 in, 2 out)」「CABLE-B Input (VB-Audio Cable B), Windows DirectSound (0 in, 2 out)」
という部分を探します。この表記の冒頭には番号がありますので、それを使用して話者への出力を分けることで、音声を分岐させることができます。
自分でわかるようにAかBか好きな方を使えばよいと思います。
「OBS Studio」の設定では、音声部分の「グローバル音声デバイス」において、「VB-Cable A+B」の自分の設定した音声が出るようにしておきましょう。
次に「VTube Studio」の設定内にある「VTube Studioを複数起動」へ。
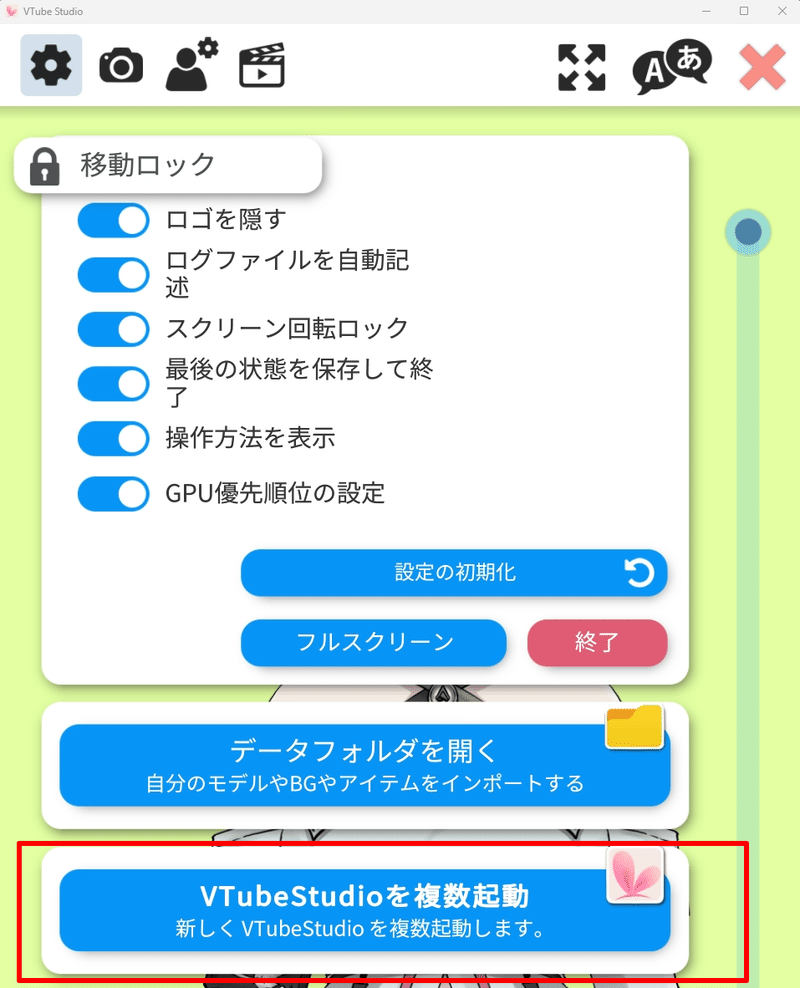
VTube Studioの設定では、リップシンク設定のマイクの部分で、話者とキャラクターを合わせて「VB-Cable」の無料版、またはAまたはBを選択することで、出力音声を分けることができます。私は現在、無料版とAを使用しています。話者が増えた場合は、「VB-Cable C+D」も購入すれば、最大5人までの出力がすぐにできそうです。

マイク設定を済ませたら、プログラムを動かせば、「ゆっくり解説」のような2人の話者が会話をするようになりました。
コメントを拾ってリアルタイム性と合わせてアイデアを考えるのも面白いですね。台本に基づいた内容と、視聴者のリアルタイム参加を組み合わせることで、AIを活用した新しいタイプのコンテンツを作ることができるかもしれません。AI活用のコンテンツについても引き続き楽しみながら、考えていきたいと思います。
今回もお読みいただき、ありがとうございます。
この記事が気に入ったらサポートをしてみませんか?