
Hadoopのインストール手順 #Granvalley

1.はじめに
皆様こんにちは。
グランバレイ社員兼釣りビギナーのJim2@GVです。
業務でHadoopを導入する機会があったのですが、ネットで調べると数年前の古い記事ばかり・・・
そこで、本記事ではHadoop3.3ラインにおける現時点(2020/12)での最新バージョンのインストール手順について書いていこうと思います。
気になった方はぜひ見ていってくださいね!
~ 導入環境 ~
Centos7(64bit)
rpm 4.14.2
JDK 14.0.1
Hadoop 3.3.0
2.Hadoopとは
インストール手順の前に、まずはHadoopとは何なのかを簡単に説明したいと思います。
Hadoopとは、大規模データの分散処理を支えるJavaソフトウェアフレームワークです。
大まかに言うと、
・データを分散させるための「HDFS」
・分散させたデータを効率よく処理するための「MapReduce」
という2つの機能が組み合わされたものです。
主な特徴としては、
・データ入力時のスキーマ定義が不要
・非構造化データ(画像データなど)も扱うことができる
・サーバを追加することで容量および処理性能を向上させることができる
・サーバの故障や通信障害等をシステムが検出しリカバリすることができる
などが挙げられますね。
ただ、Hadoopにも欠点があります。
同じ処理を複数回行ったり、同じデータに何度もアクセスする場合にはその都度ストレージへのアクセスを行うので、処理が遅くリアルタイム処理には向いていません。
現在では頻繁にアクセスが発生しないような大量データの処理に使用されることが多いようですね。
3.まずはJDK(Java SE Development Kit)のインストール
Hadoopのインストールは?と思われた方もいるかもしれません。
前の項でHadoopはJavaソフトウェアフレームワークと書きましたが、HadoopはJavaで作られています。
そのため、Hadoopを操作するにはJavaが必要となります。
公式HPのリンクから飛べるこちらのサイトにおいて「Apache Hadoopコミュニティはビルド/テスト/リリース環境にOpenJDKを使用している」との記載があるので、今回はOpenJDKをインストールしていこうと思います!
また、同サイトによるとHadoop3.3以降はJava8およびJava11をサポートしているようです。
インストール時にはJavaのバージョンにも注意が必要ですね!
※既にインストール済みの方はHadoopのインストールへ!
① OpenJDKをインストール
OpenJDKはyumでインストールすることができます。
> yum install java-1.8.0-openjdk
> yum install java-1.8.0-openjdk-develインストール後はjavaコマンドでバージョンを表示して、きちんとインストールができているか確認を行いましょう!
> java -version② インストール先の確認
Hadoopのインストール時にインストールしたOpenJDKの保存先を設定する必要があるので、確認をしておきましょう!
私の環境では【/usr/lib/jvm/java-1.8.0-openjdk】でした!
4.Hadoopのインストール
それではいよいよHadoopのインストールを行っていきます。
① Hadoopインストール用のファイルをダウンロード
まずはApache HadoopプロジェクトのサイトからHadoopをダウンロードします。
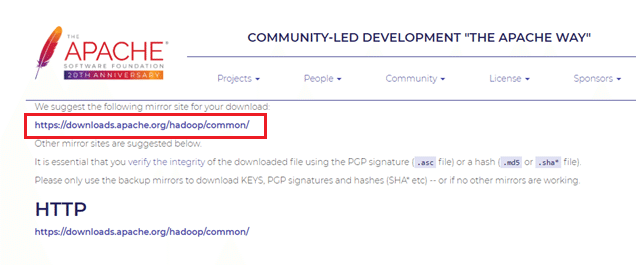
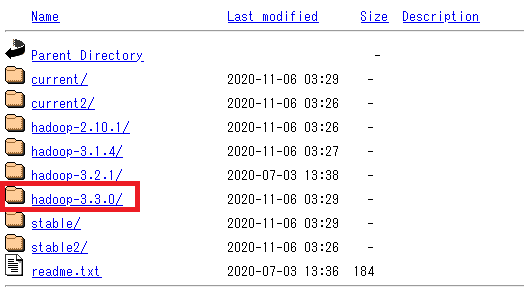
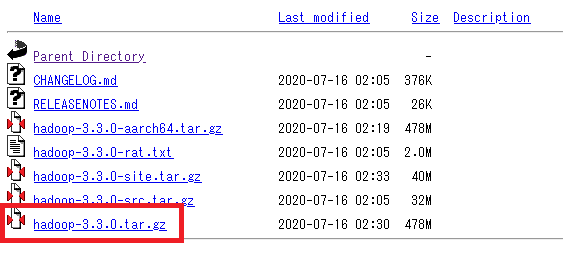
ダウンロードするファイルは【hadoop-3.3.0.tar.gz】です。
以下のコマンドでファイルをダウンロードします。
> wget https://ftp.kddi-research.jp/infosystems/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz ② ダウンロードしたファイルの解凍
JDKインストール時と同様に、ターミナルからスーパーユーザーでログインし、ファイルを操作します。
操作するのは【hadoop-3.3.0.tar.gz】です。
Hadoopのインストール用ファイルは圧縮されているのでまずは解凍します。
> tar zxvf hadoop-3.3.0.tar.gz解凍すると、圧縮ファイルと同じ場所に【hadoop-3.3.0】というディレクトリが作成されるので、このディレクトリは扱いやすい場所へ移動させておきます。
※今回は【/usr/local】へ移動させました。
③ PATHの設定
続いてPATHを通していきます。
Hadoopを使用するためには、HadoopとJavaの2種類のPATHを設定する必要があります。
設定のため、root配下の【.bashrc】を編集します。
> vi ~/.bashrc以下の情報を【.bashrc】の末尾に追加します。
JAVA_HOME=/usr/java/jdk-14.0.1
HADOOP_INSTALL=/usr/local/hadoop-3.3.0
PATH=$HADOOP_INSTALL/bin:$JAVA_HOME/bin:$PATH変更を保存したら、コマンドを実行して変更を反映させます。
> source ~/.bashrc
④ インストールの確認
最後に、きちんとインストールされているかコマンドを実行して確認します。
> hadoop versionバージョンが表示されたなら、インストール完了です!
Hadoopはインストール時点ではスタンドアロンモードとなり、ローカルファイルの操作ができます。
色々操作を試してみるのも面白いですね!
5.まとめ
今回はHadoopのインストール手順を説明してみましたが、いかがでしたでしょうか?
今回の記事が皆さんのお役にたてればうれしいです。
最後までお読みいただきありがとうございました!
※グランバレイにご興味のある方はこちらをご覧ください!
この記事が気に入ったらサポートをしてみませんか?