
ビジョン認識マルチモーダルLM: Qwen-VLを試す

Alibaba Cloudが公開したLLMに画像認識を加えたマルチモーダルで、かつ英語と中国語のマルチリンガルLVLM(large Vision Language Model)、Qwen-VL(Qwen Large Vision Language Model)を簡単に試してみました。
お試し環境
Windows11(WSL2)
ローカルPC RTX3090(24GB)
私は試していませんが、int4量子化モデルもリリースされておりGoogle Colabの無料枠でも動くかもしれません。
さっそく試してみます
このモデルは英語の中国のマルチリンガルなモデルなのですが、残念ながら私は両方明るくないので翻訳パイプラインを定義します。
import pysbd
from transformers import pipeline
def en_to_ja(en_text):
seg_en = pysbd.Segmenter(language="en", clean=False)
ja = pipeline('translation', model='staka/fugumt-en-ja')
extracted_texts = [d['translation_text'] for d in ja(seg_en.segment(en_text))]
return '\n'.join(extracted_texts)
def ja_to_en(ja_text):
seg_ja = pysbd.Segmenter(language="ja", clean=False)
ja = pipeline('translation', model='staka/fugumt-ja-en')
extracted_texts = [d['translation_text'] for d in ja(seg_en.segment(ja_text))]
return '\n'.join(extracted_texts)必要なライブラリーをインストール。
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)トークナイザーとモデルを読み込みます。VRAM容量に応じてオプションを設定してください。
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cpu", trust_remote_code=True).eval()
# use cuda device
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True).eval()
実行!
url = 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'
text = 'これは何?'
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
# 1st dialogue turn
query = tokenizer.from_list_format([
{'image': url}, # Either a local path or an url
{'text': ja_to_en(text)},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(en_to_ja(response))女性と彼女の犬がビーチで遊んでいます。
response, history = model.chat(tokenizer, ja_to_en("ハイタッチの手の位置を囲んでください。"), history=history)
print(response)
image = tokenizer.draw_bbox_on_latest_picture(response, history)
if image:
image.save('1.jpg')
else:
print("no box")

>>画像は、木製の小屋の隣に駐車された緑の自転車を特徴としています。 自転車は小屋にもたれかかっています。小屋は古くて木でできているようです。 小屋の左側にはドアがあり、自転車はその近くに配置されています。 このシーンは懐かしさを感じさせ、よりシンプルな時間を視聴者に思い出させます。

ここまで試したあとに気づいたのですが、githubページのREADMEの後にシンプルなWeb UIデモも公開されていました。こっちを改造したほうが速かったかも😝
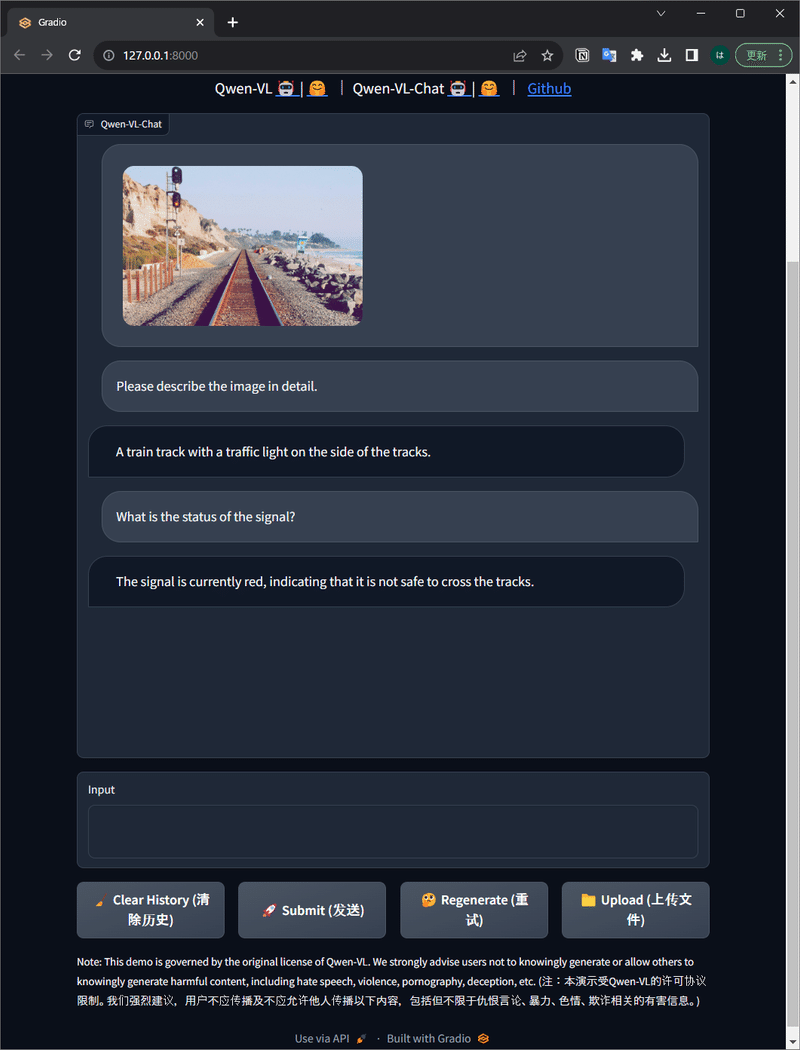
ローカル環境でもマルチモーダルLLMが試せると、色々遊べそうですね。
お読みいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?