
Photo by
task_akimoto
音声生成モデルAudioLDM2を試す

AudioLDM2というText-to-Audio/Music 生成AIが公開されていたので試してみました。リンク先にはいろいろな音声生成サンプルが紹介されており、どれも高品質でいい感じです。Githubリポジトリはこちら。
概要
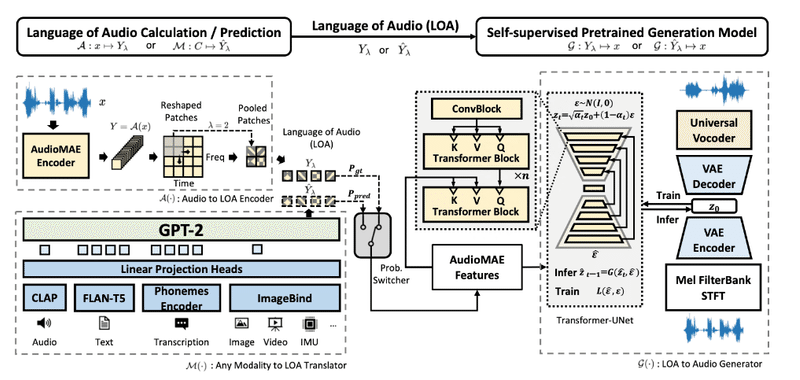
テキストから、効果音生成: text-to-audio (TTA), 音楽生成: text-to-music (TTM), および 音声生成: text-to-speech (TTS)の共通フレームワーク
フレームワークは「オーディオ言語: Language of Audio(LOA)」と呼ぶ汎用的なオーディオ表現を導入
条件付き入力は「オーディオ言語」に変換され、その後音声合成モデルで処理される
テキスト効果音合成 (TTA)、テキスト音楽合成 (TTM)、テキスト音声合成 (TTS) での実験結果はSoTAを達成している
とのこと
ともかく試食
さっそく試してみます。README.mdにそってローカルPCにインストールして試してみました。
Gradioのwebuiも用意されているのですが、自分の設定がうまくいかなかったのか、なぜか自分の環境ではうまく起動できなかったので、今回はコマンドラインから試してみました。なお、text-to-speechのチェックポイントは今のところ公開されていないようです。
$ audioldm2 -t "Craft a 90's EDM track at 130 BPM, using a TB-303 for acid bass, TR-909 for kicks and snares, and classic house piano stabs. Include a euphoric chorus with trance-like strings, and apply side-chain compression for a pumping feel."テキスト音楽合成(TTM)
プロンプトはChatGPTで適当に生成😊
テキスト効果音合成 (TTA)
ドアがゆっくり閉まる音
小川が流れる音
いかがでしょうか。
まとめ
Language of Audio(LOA)という、おそらくテキストに変換してから音声を合成するということでLLMと親和性が高そうなアイデアだと思います。音楽分野のモデルも研究が進んでいるようで今後の発展が楽しみです。
この記事が気に入ったらサポートをしてみませんか?