
1(.58)ビット量子化LLMs(BitNet b1.58)について

Microsoft Researchが発表した以下論文がXで話題になっていました。少々出遅れた感がありますが、さっそく眺めてみました。
BitNet b1.58
全パラメータ(重み)を三項{-1, 0, 1}で量子化。{-1, 0, 1}の3つの値を表現するために必要なビット数は$${log_2(3)}$$であるため、1パラメータあたり約1.58bitで表現できる。
同じモデルサイズとトレーニングトークンを持つ全精度(FP16またはBF16)のTransformer LLMと、パープレキシティ(混乱度)およびエンドタスクのパフォーマンスの両方で同等の性能を維持しつつ、遅延、メモリ、スループット、およびエネルギー消費の面で大幅にコスト効率が良かった。

1(.58)bit量子化による計算の簡略化
BitNet b1.58では、8bitのアクティベーションで順伝播と逆伝播を計算して、重みの更新時は{-1, 0, 1}に量子化します。
1bit量子化を行うことで、行列計算を乗算を使わずに加減算のみで実現できます。単純だけど、コロンブスの卵的なすごいアイデアだと思います。
1bit量子化された重み行列 $${W}$$ と入力ベクトル $${X}$$ の行列積を計算する場合(入力ベクトルの要素$${x}$$ は8bit精度):
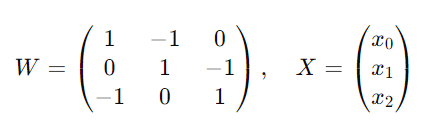
この積 $${W \cdot X}$$ は次のように計算されます:

これを加減算のみを用いて単純化すると、出力の計算は次のようになります:

どうしてFP16と精度が変わらないのか
論文では結果について言及されていますが、どうしてFP16等と精度が変わらないのか理由の考察は無いようです。ちょっと私には難しいので、ChatGPTに考えてもらいました。
スパース性の活用: 多くの場合、ニューラルネットワークのパラメータはスパース(ほとんどが0に近い値を持つ)です。このため、重要な情報を持つパラメータのみを-1, 0, 1のいずれかで表現することで、モデルは重要な情報を維持しつつ、大幅にパラメータの量を削減できます。
量子化と正則化の効果: 1ビット表現は、事実上の量子化として機能し、モデルの過学習を防ぐ正則化の効果も期待できます。量子化により、モデルがトレーニングデータのノイズに過剰に適応するのを防ぎ、汎化性能が向上することがあります。
効率的なトレーニングと推論: 1ビットのパラメータを使用することで、トレーニングと推論の際に必要な計算量とメモリ使用量が大幅に削減されます。これにより、より大きなモデルやより多くのデータでのトレーニングが可能になり、間接的にモデルの性能向上に寄与することがあります。
とのことです。なんとなく納得できるような…。詳しくは優秀な方に解説をお任せします。😅
精度を担保したままで、学習においても推論においても、劇的に計算資源を削減できるので、LLMの応用がさらに加速しそうです。
この記事が気に入ったらサポートをしてみませんか?