Coral Keyphrase検出器

「ゲームの開始」や「次の歌」などの140以上の短いフレーズを検出できるキーフレーズ検出モデルを使用したいくつかの例。 音声コマンドに応答するスネークゲームとYouTubeプレーヤーが含まれます。
キーワードスポッター(KWS)と呼ばれることが多いキーフレーズ検出器は、音声ストリーム内の定義済みの単語または短いフレーズの存在を検出する単純な音声処理アプリケーションです。 これは、最近では「OK Google」や「Alexa」などのホットワード(またはウェイクワード)でよく見られます。これらは、デジタルアシスタントが聴き始めるタイミングを知らせるために使用されます。
リポジトリには、2秒のオーディオウィンドウで「左へ移動」、「位置4」などの約140の短いキーフレーズを検出できるキーフレーズ検出モデルが含まれています。 ニューラルネットワークの各出力ニューロンはキーフレーズに対応します。完全なリストはここにあります。(https://github.com/google-coral/project-keyword-spotter/blob/master/config/labels_gc2.raw.txt)
リポジトリには、必要なすべてのラッパーコードと3つのサンプルプログラムも含まれています。
run_model.py:推論が実行されるたびに検出の上位2、3を出力します。
run_hearing_snake.py:ゲームスネークの単純な音声制御バージョンを起動します。
run_yt_voice_control.py:YouTubeプレーヤーを制御できます。 YouTubeをブラウザータブで実行し、YouTubeプレーヤーにフォーカスする必要があります。
クイックスタート
Edge TPUデバイスが正しく構成されていることを確認してください。 モデルで問題が発生した場合は、最新バージョンを実行していることを確認してください。
Coral DevBoardの場合
USBアクセラレーター用
すべての要件をインストールするには、単に実行します。
sh install_requirements.sh
Coral DevBoardとUSB Acceleratorの両方で、次を実行してモデルをテストできます:
python3 run_model.py
数秒後、次の出力が表示されるはずです:
$ python3 run_model.py
ALSA lib pcm.c:2565:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.rear
...
ALSA lib pcm_usb_stream.c:486:(_snd_pcm_usb_stream_open) Invalid type for card
Input microphone devices:
ID: 0 - HDA Intel PCH: ALC285 Analog (hw:0,0)
ID: 6 - sysdefault
ID: 12 - lavrate
ID: 13 - samplerate
ID: 14 - speexrate
ID: 15 - pulse
ID: 16 - upmix
ID: 17 - vdownmix
ID: 19 - default
Using audio device 'default' for index 19
negative (0.988)
negative (0.996)
negative (0.996)
negative (0.996)
...
モデルが理解できるキーフレーズの一部を言うと、それらが認識されているのがわかるはずです。
negative (0.973) no (0.020)
*launch_application* (0.996)
*launch_application* (0.996)
*launch_application* (0.996)
*launch_application* (0.996)
negative (0.914) begin_application (0.039) open_application (0.016)
negative (0.996)
negative (0.562) position_two (0.254) position_one (0.113)
* move_left* (0.996)
* move_left* (0.996)
* move_left* (0.996)
negative (0.938) turn_right (0.016) turn_left (0.016)
negative (0.863) turn_right (0.035) last_song (0.035)
* volume_up* (0.996)
* volume_up* (0.996)
* volume_up* (0.996)
* volume_up* (0.984) volume_down (0.008) negative (0.008)デフォルトの表示クラスには、信頼度とともに最大3つの検出が表示されます。 期待どおりに機能しない場合は、他の例を試す前に以下のトラブルシューティングのセクションをご覧ください。
聴覚ヘビ
聴覚蛇は、音声コマンドを使用して制御できる古典的な蛇ゲームのバージョンです。 ディスプレイが必要なので、Coral DevBoardを使用している場合は、最初にモニターを接続します。
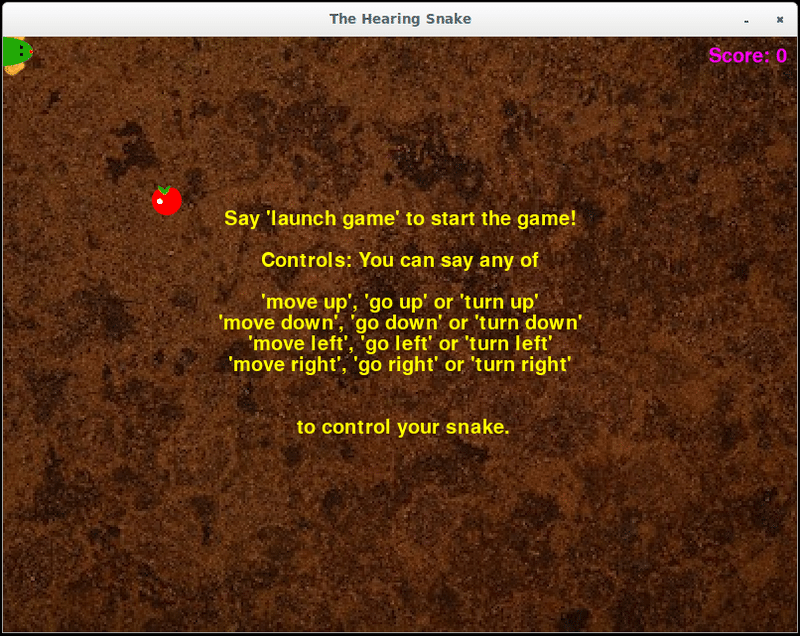
USBアクセラレーターをLinuxシステムに接続し、X Windowsシステムを単純に実行する場合:
python3 run_hearing_snake.pyCoral DevBoardの実行:
bash run_snake.sh
ゲームウィンドウにプレイ方法の説明が表示されます。
YouTube音声コントロール
YouTube Voice Controlは、音声コマンドを使用して他のアプリケーションを制御する方法を示します。 まず、ブラウザーでYouTubeを開き、ビデオまたはプレイリストを再生します。 繰り返しますが、これにはディスプレイが必要なので、Coral DevBoardを使用している場合は、試してみる前にモニターを接続してください。
USBアクセラレーターをLinuxシステムに接続し、X Windowsシステムを単純に実行する場合:
python3 run_yt_voice_control.py
Coral DevBoardの実行:
bash run_yt_voice_control.sh
次の曲、次のビデオ、ミュートなど、YouTubeに関連するコマンドを言うと、コンソールに検出が表示されるはずです。
next_video {'key': 'shift+n', 'conf': 0.4}
---------------
next_song {'key': 'shift+n', 'conf': 0.4}
---------------
mute {'key': 'm', 'conf': 0.4}
---------------YouTubeビデオプレーヤーにフォーカスを戻すと(たとえば、Alt + Tabキーまたはクリック)、これらのコマンドが実行され、YouTubeビデオプレーヤーが制御されます。 これは、留置を仮想キー押下にマッピングすることで行われ、多くの異なるアプリケーションをサポートするように構成できます。
フードの下
キーフレーズ検出モデルでは、2秒間の音声を32次元のログメル機能に変換して入力する必要があります。 これらの特徴は10ミリ秒ごとに計算されます。つまり、2秒の音声の結果は198個の特徴ベクトルまたはフレームになります。 モデルラッパーは、最後の198フレームのバッファーを保持し、Nフレームごとにモデルを実行します。 デフォルトではNは33に設定されていますが、-num_frames_hopパラメーターを使用して変更できます。 比較する
python3 run_model.py --num_frames_hop 11
と
python3 run_model.py --num_frames_hop 99
num_frames_hopに低い値を使用すると、モデルがより頻繁に推論を実行し、その待ち時間が短縮されますが、計算コストも増加します。
キーマッピングの制御
YouTube音声制御の例では、PyUserInputを使用してキーボードの押下をシミュレートします。 音声コマンドとキー間のマッピングは、config / commands_v2.txtにあります。
volume_down,down,
next_song,shift+n,
これにより、コマンドvolume_downは下キーに、コマンドnext_songはシフトキーとnの両方を押すようにマップされます。 新しいマッピングを追加してみてください(config / labels_gc2.raw.txtには有効な音声コマンドのリストが含まれています)。
よりきめ細かな制御
新しいコールバック関数を記述することにより、音声コマンドにどのように、どのように反応するかをより細かく制御できます。
不良診断
問題1:このエラー「OSError:[Errno -9997] Invalid sample rate。」で失敗する:
Input microphone devices:
ID: 0 - HDA Intel PCH: ALC285 Analog (hw:0,0)
ID: 6 - sysdefault
ID: 12 - lavrate
ID: 13 - samplerate
ID: 14 - speexrate
ID: 15 - pulse
ID: 16 - upmix
ID: 17 - vdownmix
ID: 19 - default
Using audio device 'default' for index 19
「--mic X」オプションを使用して、正しいマイクを選択します。 モデルは、16kHzのサンプルレートでの入力を想定しています。 16kHzをサポートしていないマイクを使用する場合は、「-sample_rate_hz XXXXX」オプションを使用して、サンプルレートをマイクサポートに合わせます。 48000を選択すると、自動的に16000にダウンサンプリングされます。他のすべての入力が正しく機能しない場合があります。
問題2:検出品質が非常に悪い。
考えられる原因:
間違ったマイクが選択されました。問題1を参照してください。
システムのマイクゲインの設定が高すぎるか、低すぎます。 入力デバイスに対するシステムのサウンド設定を確認し、通常の音声が適切なレベルに達するのに十分なほどゲインが高く、ピークに達することはない(最大に達する)ことを確認します。
マイクが不良または破損しています。別のマイクを試してください。
バックグラウンドのノイズが多すぎる場合は、近くで話すマイクを使用してください。 考えられる解決策:マイクのリストについては、プログラム出力をご覧ください。 次のようになります。
問題3:モデルは、一部のキーフレーズではうまく機能しますが、他のキーフレーズでは機能しません。
これは既知の問題であり、将来のバージョンではこれを試して修正します。 一部のキーフレーズは他のキーフレーズよりも検出が難しく、全員が同じアクセントを話すわけではありません。 modelsディレクトリには2つのモデルがあります。 デフォルトでは、voice_commands_v0.7が使用されます。 特に時刻のキーフレーズに問題がある場合は、voice_commands_v0.8を試してください。
python3 run_model.py --model_file voice_commands_v0.8_edgetpu.tflite
問題4:モデルがキーフレーズで過剰にトリガーしています。
キーフレーズ固有のしきい値を使用します。 snakeの例では、これをconfig / commands_v2_snake.txtファイルで関連する行の最後に追加することで実行できます。 例えば
go_left,left,0.9
go_right,right,0.7
go_leftのキーフレーズ固有のしきい値を0.9に設定し、go_rightのキーフレーズ固有のしきい値を0.7に設定します。
問題5:モデルで提供されていないキーフレーズが必要です。
今のところこれらの約140語しかありませんが、将来のバージョンでは、キーフレーズのさまざまな可能な組み合わせを提供したいと考えています。 何が役立つかについてのフィードバックを送ってください。
Google Coral Edge TPU代理店Gravitylink! https://store.gravitylink.com/global

この記事が気に入ったらサポートをしてみませんか?