
Kaggle|American Express - Default Prediction の評価指標を理解したい(ROC曲線/AUC/正規化ジニ係数)

最近Kaggleに入門しまして、知らないことも多くて日々わくわくしています。最近は『American Express - Default Prediction』というクレジットカードのデフォルト(貸し倒れ)率を予測するコンペティションに参加していました。クレジットカードの支払いが極度に滞ったような状態になりそうかどうかを予測しましょうという内容です。
コンペティションごとにうまく予測ができているかを測るための評価指標が与えられているのですが、自分にとってわかりづらい箇所が何点かあったので備忘のためにもここにまとめておこうと思います( こちらのDiscussion の原文です)。各要素はよく見るものだと思うのでコンペティションに参加されてない方の参考にもなるとうれしいです 😄
コンペティション内容と与えられている評価指標
今回取り組んだ課題の要点は以下になります。
・ 予測デフォルト率を算出するモデルを作成する(「デフォルト顧客である/ではない」という出力ではない)
・ 評価指標内で予測デフォルト率が上位4%の顧客はデフォルトすると判別される
そして、機械学習で予測する際にうまく予測できているかを測る指標として以下の計算式が与えられています。
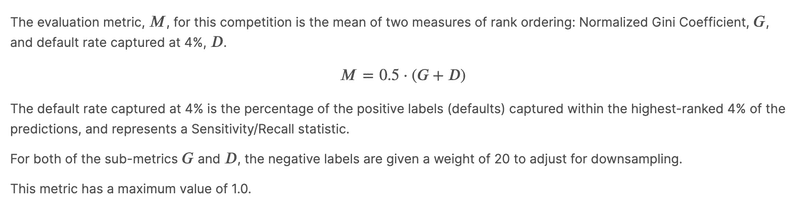
$${M = 0.5 \cdot (G + D)}$$ という式が与えられています。$${G}$$と$${D}$$の平均でパッと見た感じはシンプルですが、肝心の$${G}$$と$${D}$$という部分がよくわかりません。これをひとつずつ見ていきたいと思います。
G: Normalized Gini Coefficient (正規化ジニ係数)
前提知識(ROC曲線とAUC)
まずはジニ係数を計算 & 理解するためにROC(receiver operating characteristic)曲線とその下側面積のAUC(area under the curve)について確認します。
① ROC曲線の作成
ROC曲線は予測デフォルト率を順に並べたときに実際デフォルト・非デフォルトしたかどうかを視覚的に捉えることができる曲線です。デフォルトした 4 顧客、デフォルトしてない 8 顧客がいるとします。やっていくのは大まかに書くと以下のことです。
・ 縦に 4 分割、横に 8 分割した図を描く
・ デフォルトした顧客であれば真上に、デフォルトしてない顧客であれば真横に線を伸ばしていく
試しに今回以下のように予測デフォルト率を出したとします。Dが実際デフォルトの顧客、NDが非デフォルトの顧客です。

それでは上(↑)の例を元に実際にグラフを描いてみましょう。
(0, 0) から始め、デフォルト予測のスコアが高い順にROC曲線を描いていきます(下の画像の青い線に当たります)。
1. 最もスコアが高い顧客はデフォルトしているので真上に 1/4 進む
2. 次いでスコアが高い顧客はデフォルトしてないので真横に 1/8 に進む
3. 次にスコアが高い顧客はデフォルトしているので真上に1/4進む
…
というように全ての顧客に対して原点 (0, 0) と (1, 1) を結んだ折れ線グラフを描くことができます。
完全にデフォルトしたかどうかを判別できるモデルであれば赤い線で描かれたROC曲線が得られます。
② AUCを計算する
AUCはROC曲線の下側面積そのものです。試しに作成したモデルのAUC(青い部分の面積)を求めてみましょう。1マス 1/4 × 1/8 の長方形が 26 個あるので以下のように求められます。
$${AUC = \frac{1}{4} \cdot \frac{1}{8} \cdot 26 = \frac{13}{16}}$$
この例ではAUCが $${\frac{13}{16}}$$ であることがわかります。
・ AUCのとる範囲は 0 ~ 1
・ 完全判別モデルのときは 1、ランダムモデルのときは 0.5
the Normalized Gini Coefficient(正規化ジニ係数)
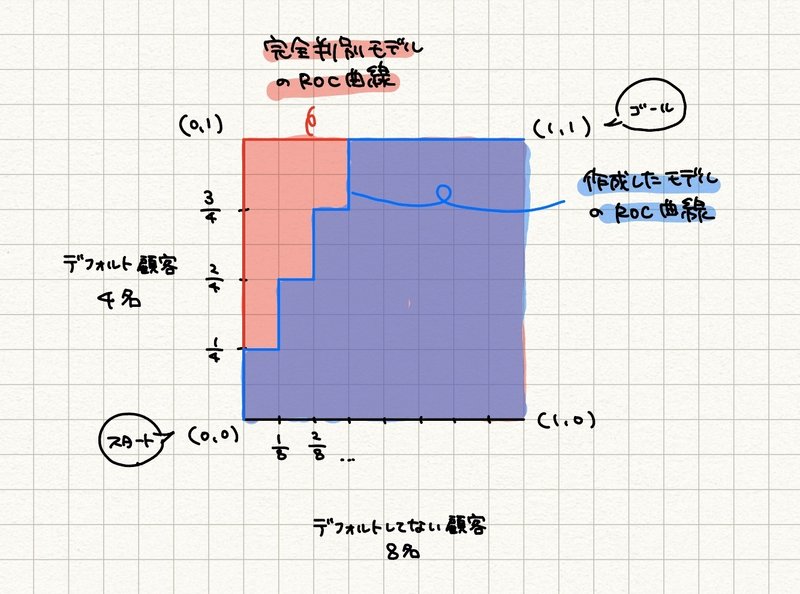
さて、今回必要なジニ係数について見ていきます。AUCと同じく面積について考えます。よく知られるもので、所得の不平等さを測る指標としてローレンツ曲線と対角線の間の面積の2倍の値で求められるジニ係数があります。しかしモデル評価時にROC曲線を用いて算出されるジニ係数は「ROC曲線と対角線の間の面積」と定義されます(今回はこちら)。また正規化ジニ係数は完全判別モデルに対する作成モデルの割合になります。
$${Gini = A}$$
$${Normalized \: Gini = \frac{Gini_{作成したモデル}}{Gini_{完全判別モデル}} = \frac{A}{A+B} = 2A}$$
・ ジニ係数の範囲は -0.5 ~ 0.5、正規化ジニ係数の範囲は -1 ~ 1
・ 正規化ジニ係数の目的はAUCをスケールすること(= ランダムモデルは 0、完全判別モデルは 1 になる)
AUCは完全判別モデルの面積の何割にいたるのか、(正規)ジニ係数は対角線(ランダムモデル)を基準として何割にいたるのかを表しています。
ここまで、どのようにROC曲線を引くのか、AUCやジニ係数のがどのように計算されるのかを見てきました。ジニ係数は所得の不平等さを測る以外の使われ方を初めて見たので少し理解に苦しみましたがこうしたランク付けの能力を測るためにも使用できることがわかって面白かったです。
D: The default rate captured at 4%
予測で得られた顧客のデフォルト率を降順に並べます。各々順位$${Z}$$(上位何%地点か)が閾値 $${c}$$(今回は上位4% = 0.04)よりも高い顧客はデフォルト、閾値を下回る順位の顧客は非デフォルトと判別されます。
評価指標$${D}$$を理解するためには閾値を決めた際に定まる正しく判別される確率、誤って判別される確率が重要になってきます。


また、FPRは「どれほど非デフォルト顧客をデフォルトと誤って判別したか」、TNRは「どれほど非デフォルト顧客を非デフォルトと正しく判別したか」ということを表します。
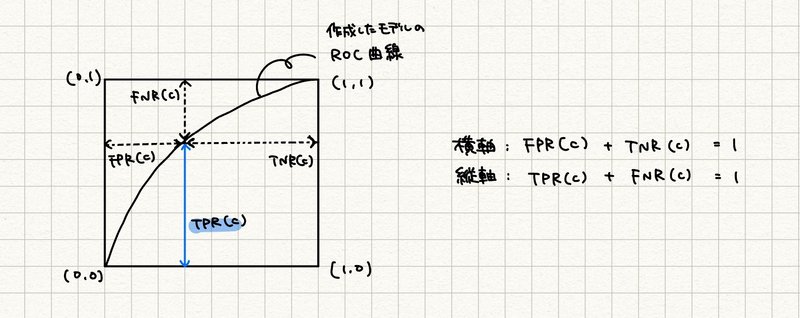
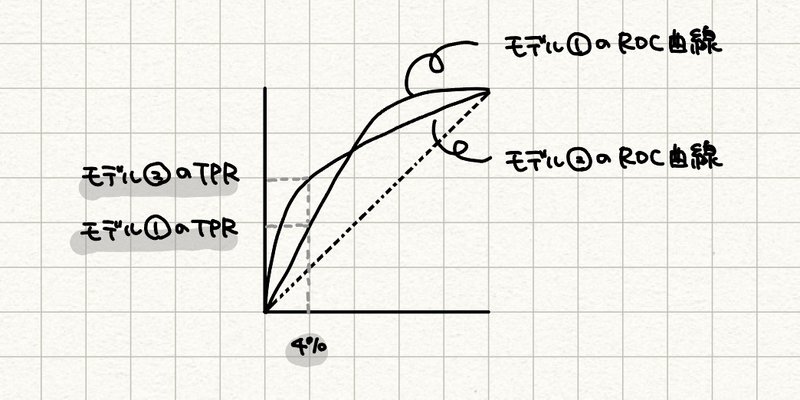
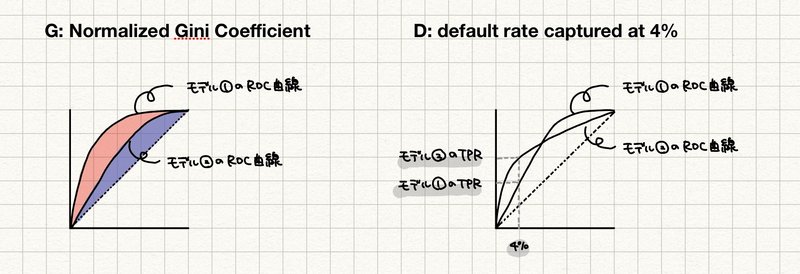
もしジニ係数が同じ2つのモデルがあっても、4%で捕捉されたデフォルト率(TPR)が変わってきます。下の2つのモデルでは $${M = 0.5 \cdot (G + D)}$$ の$${D}$$の値がモデル②のほうが高いため、最終的なスコア($${M}$$)の値もモデル②のほうが高くなります(下の図のジニ係数$${G}$$の値は同じと仮定します。)
2つの指標を合わせる意味
G: 全体的な正答率
D: TOP4%地点でデフォルト顧客をデフォルト顧客と正しく判別できる割合
$${G}$$と$${D}$$は各々上記のような意味でした。つまり全体的な正答率の高さはもちろんのこと、デフォルト率の予測順に並べたとき上位4%に多くデフォルト顧客が含まれる必要があります(= 予測デフォルト率の高い顧客はなるべく外してはいけない)。
$${G}$$と$${D}$$どっちかでええやんと思っていたのですが、各々の理屈を理解すると両方の結果を混ぜるのは非常に納得ができました。
わからないことが多すぎるけど楽しい。むしろ知らないことがたくさんあることを知れるのが楽しいのかもしれない。引き続き楽しみつつ取り組んでいければと思います 😆
参考資料
統計の本、もしくはわんこにおいしいお菓子を買うのに使わせていただきます( *ˆoˆ* )