機械学習勉強会を開催しました!PART3

前回に引き続き勉強会を開催しました。
引き続き、KaggleのTitanicの問題を解いていきました。
前回データの可視化までを行ったので、可視化から分かる目的変数に影響を与えているであろう要素を選択して、その要素だけのデータセットを作成しました。
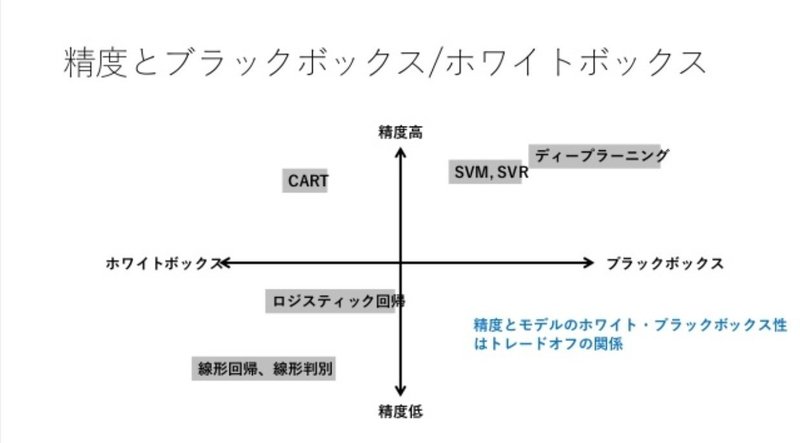
ブラックボックス・ホワイトボックス性と精度の関係をマトリックスにした下記のグラフから考えて使用するアルゴリズムを選択してもらいました。(PART1で紹介しましたね!)
さて、データセットを作ったし、アルゴリズムも選択した!じゃあアルゴリズムに適用しよう!となっても、ちょっとお待ちください!選択したデータセットを訓練データとテストデータに分割しなければなりません。
訓練データ?テストデータ?なんじゃそら・・・
機械学習を使用する時に怖いことが過学習という現象です。これは作成したデータセットに過適合してしまう際に起こる問題です。せっかく予測モデルを作ったのに、今あるデータを入れると正しく予測するけど、新しいデータを入力しても、全然正しい予測をしてくれない、となると全く意味がない予測モデルですねよね。
これを避けるために今あるデータセットを予測モデルを作る用のデータセット(訓練データ)と作成した予測モデルの精度を検証するデータセット(テストデータ)に分ける必要があるんです。
scikit-learnというPythonのライブラリには便利な関数だらけでして、train_test_split関数をimportすれば簡単にデータセットを分割してくれます。
こうして、作成した予測モデルの精度を検証して、モデルを改善しながら、Kaggleへ予測値の提出までを行いました!
こうしてデータセットの作成からアルゴリズム選択、アルゴリズムの精度確認まで一通りをお伝えしました。次回は、Kaggleに開催されている賞金のかかったコンペティションに挑戦していきたいと思います!
この記事が気に入ったらサポートをしてみませんか?