
Pythonを使って色々やってみよう!(第二回・Selenium基礎編)

こんにちは。第一回でGoogle Colabの環境を準備することはできたかと思います。できてない方は、前回の記事を読んでいただければと思います。
では環境ができている前提で話を進めたいと思います。プログラムを組んだことがある人もない人もいるかと思いますが、Pythonというのは一般的にはインタープリターと呼ばれるタイプの言語になります。インタープリターとは翻訳者という意味ですが(TOEIC900点の知識)その名の通り、人間が書いた文をコンピュータが理解する形にその場で逐一翻訳しながら実行するタイプの言語になります。
このタイプの言語は実行する都度都度翻訳するので実行速度が遅いという欠点があります。よってビデオゲームのような実行速度を0.01秒でも速くしたいタイプのプロダクトではPythonを使うことはほぼなく、あらかじめアセンブリするタイプのC言語などが使われています。用途に応じて言語を選ばれているわけです。
ですが、おそらく一般的なWebスクレイピングなどではPythonを使うことで事足りますし、私もそれで困っていることはほぼありません。
前置きが長くなりました。では早速前回の続きをやっていこうと思います。まずは以下の例を見ていただければと思います。
!pip install selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
#ここに取得するURLを入力
URL = "https://www.yahoo.co.jp/"
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--no-sandbox")
driver = webdriver.Chrome(options=options)
driver.get(URL)
title = driver.title
print(title)Pythonはインタープリター言語ですので素直に上から処理していきます。pipという機能を使ってseleniumをインストールしています。また、ブラウザと同じ動作をさせるためにwebdriverというメソッドもインポートしています。3行目のは次回以降使います。
まずは上記をGoogle Colabにコピーして実行してみましょう。URLに記載したページのタイトルを表示するものです。どうでしょうか?ずらずらとなんとかをInstallしただの出てますが、最後に"Yahoo! Japan"というタイトルが出ていますよね?

試しに他のURLを書き換えてみてください。そうやっていろいろ試すのがプログラムを作る上ではとても大事なことです。他のURLでもそれぞれTitleが表示されたかと思います。
今回はタイトルと指定しましたが他にもいろいろ指定して情報を取ることができます。それをどうやって探して指定するのかというと、デベロッパーツールというのが大抵のブラウザにはついておりまして、そちらを使います。Google ChromeやSafaliでは普通に使えます。ググったりリンク先を見てもらえればと思います。
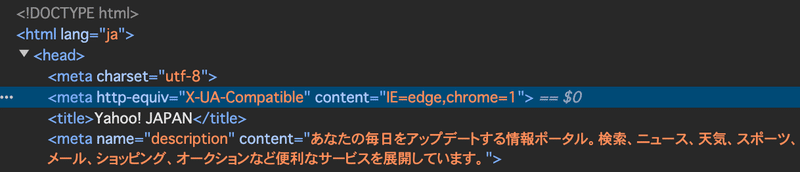
先ほどのYahoo!のWebサイトをデベロッパーツールで見ると上のように見えます。WebサイトはHTMLで書かれており、tagで囲まれた部分で情報を示すというものです。tagは<>で囲まれた部分のことです。
先ほどのスクリプトはdriver.titleというコマンドで<title> で囲まれた情報を取得したというわけですね。
というわけでここまでできればあとは正直ググりながらやればなんでもできてしまうと思いますが、それでは不親切かと思いますので次回はfind.element.byを使う方法でtitle以外の要素もサクッと取得する方法についてご紹介します。
この記事が役に立った!という方はいいね!押してもらえると嬉しいです!!
では次回をお楽しみに!(続く)
この記事が気に入ったらサポートをしてみませんか?