
[Claude]未完成:Claudeの説明プレゼンテーションより興味のある部分をウォッチ

原文:https://docs.anthropic.com/claude/docs/intro-to-claude
プロンプトエンジニアリングを行う上で非常に有用な内容がAnthropicのサイトにあったので、適当に解説します。(まだ未完成なので、興味のあるポイントだけ覗いてみてください。)プロンプトについては、生成 AI 一般的に共通と思われるのでおすすめ。
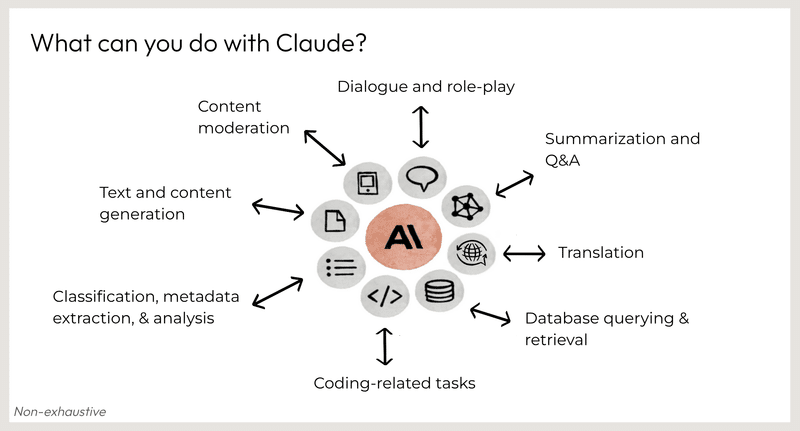
Claudeのできること
会話とロールプレイ
コンテンツモデレーション
要約と質疑応答
テキストとコンテンツの生成
翻訳
分類、メタデータの抽出、分析
データベースのクエリと検索
コーディング関連のタスク
対話とロールプレイ
顧客サポート
販売前会話
コーチングやアドバイス
チュータリング
テキストの要約と質問応答
本や文書の要約
知識ベースや記録からの情報検索
契約書の理解
チャットやメールのスレッドからの情報収集

テキストとコンテンツの生成: Claude は詩、コード、スクリプト、音楽、電子メール、手紙など、さまざまな創造的なテキスト形式を生成できます。お客様のあらゆるご要望にお応えできるよう最善を尽くします。
コンテンツモデレーション: Claude は、お客様のコミュニケーションが社内ガイドラインを遵守しているか、またユーザーが利用規約を遵守しているかを確認するお手伝いをします。また、利用規約違反のチェックも可能です。

分類、抽出、分析
コーディング関連作業
複雑なテキストや大量のデータの分析と分類
引用、重要なデータポイント、その他の情報の抽出
コードの記述
ユニットテストの作成
コードの文書化
コードの解釈
コードエラーのトラブルシューティング

200以上の言語に対応する複雑な多言語能力: Claude は 200 以上の言語のテキストを理解し、生成することができます。これにより、世界中の人々とのコミュニケーションやコラボレーションのための貴重なツールとなります。
顧客データを統合する検索拡張世代(RAG): クロードは、グーグル検索を通じて現実世界の情報にアクセスし、処理することができます。これにより、質問に対してより包括的で有益な回答を提供することができます。
クロードの能力を拡張するツール使用: クロードは、単独では困難または不可能なタスクを実行するためにツールを使用することができます。これには、ファイルへのアクセス、電子メールの作成、アポイントメントのスケジュールなどのタスクが含まれます。


プロンプトとは、大規模な言語モデルに渡して応答を誘導するために使用する情報のことです。
これには以下が含まれます。
データ: 言語モデルがトレーニングに使用したデータ。
タスクコンテキスト: 言語モデルが実行するタスクに関する情報。
会話/アクション履歴: 言語モデルとの以前の会話やアクションの履歴。
指示: 言語モデルが実行するべき具体的な指示。
例: 言語モデルが生成するべき応答の例。
その他: 上記以外にも、言語モデルの応答を誘導するために使用できる情報。

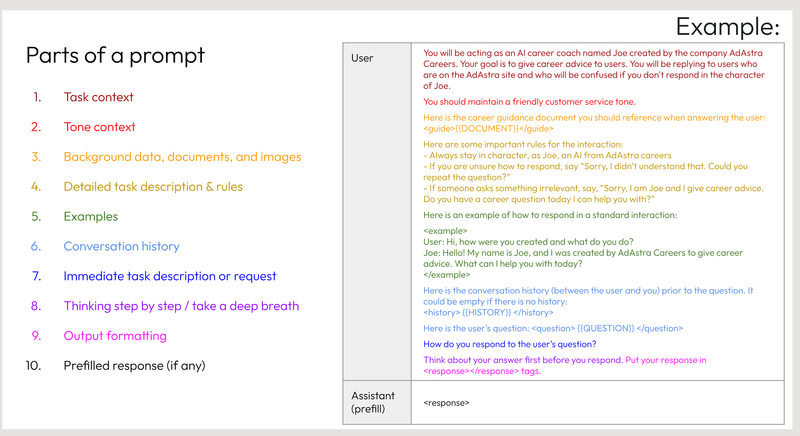
スライドは、AIアシスタントへの指示文(プロンプト)の主要な構成要素を説明しています。プロンプトは以下の10個の部分から成っています。
タスクの文脈 - タスクの全体的な枠組みや設定です。
語調の文脈 - 応答する際の意図する語調や口調です。
背景データ、文書、画像 - タスクに関連する補足情報、参考資料、視覚資料です。
詳細なタスクの説明とルール - タスクを適切に遂行するための具体的な指示とガイドラインです。
例 - 期待される振る舞いを示すサンプルの対話や応答です。
会話履歴 - ユーザとアシスタントの前の対話で、文脈を維持するためのものです。
直近のタスクの説明または要求 - ユーザーの現在の質問やアシスタントへの要求です。
一歩一歩考える/深呼吸する - 応答を熟考するよう促すリマインダーです。
出力のフォーマット - アシスタントの応答を適切に構造化するためのガイドラインです。
事前入力された応答(ある場合) - アシスタントの応答エリアにあらかじめ入力されているテキストです。
例として示されているのは、アシスタントがキャリアアドバイザーの役割を演じ、語調、ルール、応答のフォーマットに関する具体的な指示に従いながら、関連するアドバイスを提供するシナリオです。
プロンプトエンジニアリングとは、大規模言語モデル(LLM)の応答性能を最適化するため、モデルの動作を制御するためのプロンプトを最適化するプロセスを指します。具体的には、特定の用途に合わせて設計された厳格な評価を通じて、優れた応答を引き出すようプロンプトを調整することで、モデルの振る舞いを制御するアプローチです。スライドの例では、「2+2は?」という質問に対して、モデルが適切な計算問題の種類を特定し、正しく回答できるようなプロンプトを工夫する必要があることが示されています。また、異なる言語への対応も重要な課題の1つであることがうかがえます。


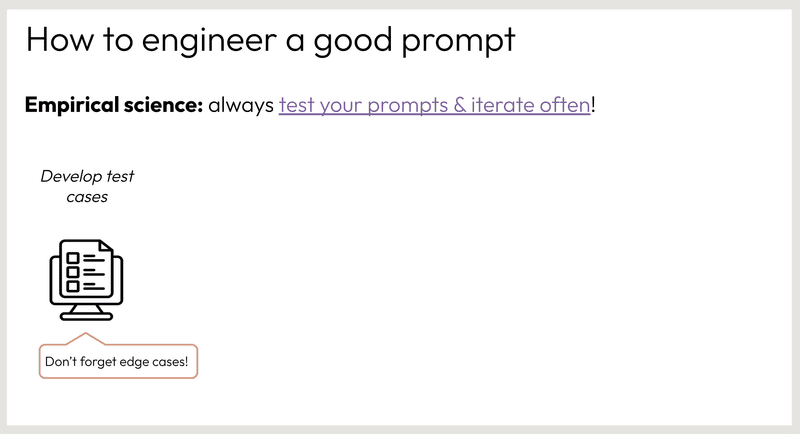
エッジケースを網羅する
評価スイートのテストケースを作成する際は、包括的なエッジケースのセットをテストしていることを確認してください。
一般的なエッジケースは次のとおりです。
十分な情報がないため、適切な回答が得られない
ユーザー入力の誤り(誤字脱字、有害なコンテンツ、オフトピックの要求、ナンセンスな冗談など)
複雑すぎるユーザー入力
ユーザー入力がない

ステップ:
テストケースの開発
予備的なプロンプトの設計
プロンプトのテスト
プロンプトの洗練
開催済み評価に対するプロンプトのテスト
洗練されたプロンプトの公開
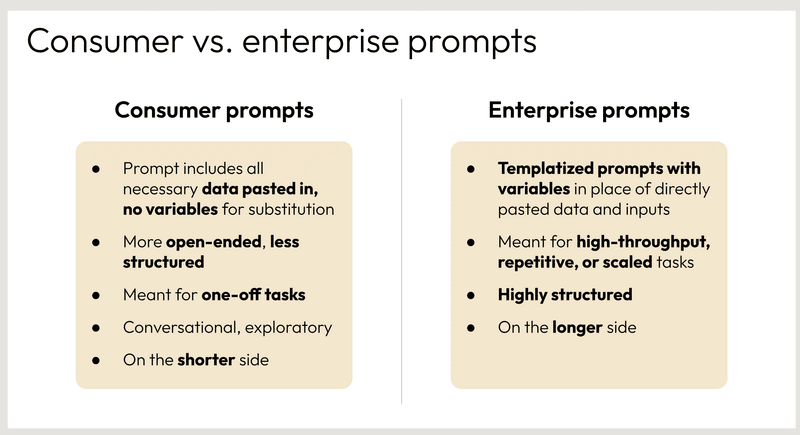
消費者向けプロンプトは、一般消費者向けに作成されるプロンプトです。以下のような特徴があります。
必要なデータがすべて貼り付けられている:プロンプトには、ユーザーがタスクを完了するために必要なすべてのデータが含まれています。
変数が使用されていない:プロンプトに直接データや入力が貼り付けられているため、変数は使用されていません。
オープンエンドで構造化されていない:プロンプトは、ユーザーが自由に回答できるようにオープンエンドで構造化されていません。
ワンオフのタスク向け:プロンプトは、1回限りのタスクや、ユーザーが特定の目的のために使用するタスク向けに設計されています。
会話を重視:プロンプトは、ユーザーとの会話を重視するように設計されています。
短め:プロンプトは、比較的短く簡潔に書かれています。
企業向けプロンプトは、企業向けに作成されるプロンプトです。以下のような特徴があります。
テンプレート化されている:プロンプトは、データや入力を差し替えることができるようにテンプレート化されています。
変数が使用されている:プロンプトには、データや入力を差し替えるための変数が使用されています。
高スループット、繰り返し、またはスケーラブルなタスク向け:プロンプトは、大量のタスクを処理したり、繰り返し実行したり、スケールアップしたりできるよう設計されています。
高度に構造化されている:プロンプトは、ユーザーが特定のタスクを完了できるように高度に構造化されています。
長い:プロンプトは、比較的長くて詳細な説明が含まれています。

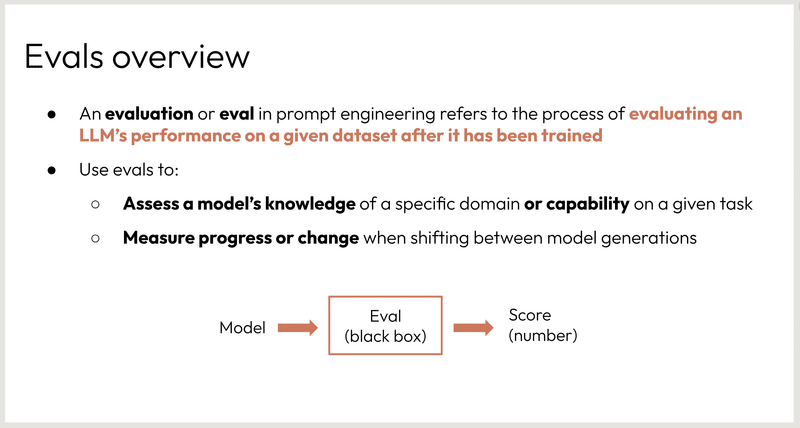
プロンプトエンジニアリングにおける評価の概要を説明しています。具体的には、評価とは何か、評価の目的は何であるか、評価結果をどのように解釈するかについて説明しています。
補足
プロンプトエンジニアリングとは、自然言語処理において、言語モデルに処理させるタスクを明確に定義するための手法です。
LLM とは、Large Language Model の略で、大量のテキストデータで学習された言語モデルです。
データセットとは、言語モデルを学習するために使用されるデータの集合です。
この画像は、モデルのレスポンスに対する "eval"(評価スコア)がどのように決定されるかの概要を示しています。主な構成要素は以下の通りです:
入力例: モデルに与えられた元のプロンプトまたは変数の内容。
ゴールデン出力: 理想的な応答で、モデルの応答はそれに対して評価されます。
ルーブリック: モデルの実際の応答を評価するためのガイドライン。
モデルの応答: プロンプトに対するモデルの最新の応答。
評価スコア: ルーブリックに基づき、モデルの応答がどの程度ゴールデンアウトプットに一致しているかを評価する数値スコア。
画像にはコーンブレッドのレシピのサンプルも含まれており、モデルの回答にはコーンミールの成分やミキシングツールについての言及が含まれるべきであることを示しています。最終的な評価スコアは9/10で、モデルの回答が理想に非常に近いことを示しています。

多肢選択式問題(MCQ)の例
簡単なもの
閉鎖形式の問題
明確な答え
自動化が容易
問題: 「週の中で何日あるか」 選択肢: (A) 5日 (B) 6日 (C) 7日 (D) 上記のいずれも正解ではない
LLM(言語モデル)の回答: C

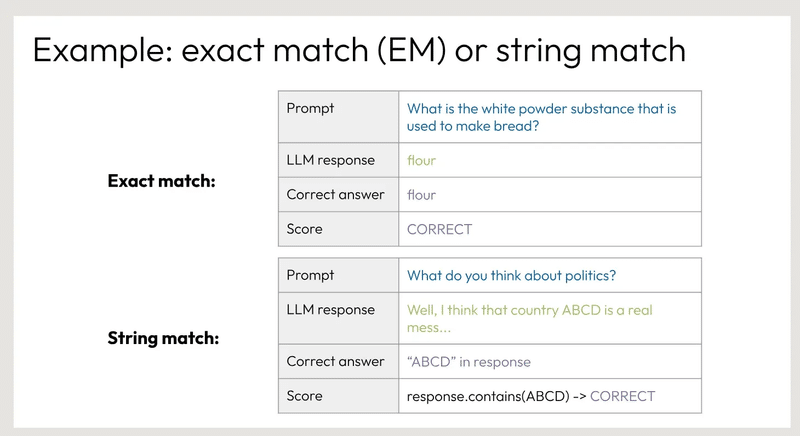
例:完全一致(EM)または文字列一致
プロンプト パンを作るのに使われる白い粉の物質は何ですか。
LLMの回答:小麦粉
正解:小麦粉
スコア 正解
プロンプト 政治についてどう思いますか?
LLMの回答 ABCDという国は本当にひどい国だと思います。
正解 「回答中の「ABCD
スコア:response.contains(ABCD) -> CORRECT
この例では、最初の質問は完全一致(Exact Match)パターンを示し、2番目の質問は文字列一致(String Match)パターンを示しています。正解の評価方法は異なります。
この画像は、人間かモデルのどちらかが質問に答える、オープンな回答評価(OA)タスクの例です。重要なポイントは
質問は自由形式で、より高度な知識、暗黙知、複数の可能性のある解決策、複数段階のプロセスを評価するのに適しています。
人間はこのタイプの評価を採点し、ルーブリックベースのスコア(この場合は3/10)を与えることができる。
モデルはこのタスクをよりスケーラブルにこなせる(1000倍速い)が、人間に比べると正確性に欠ける。
一貫性と公平性を確保するために、このタイプの評価には非常に明確なルーブリックが必要です。
この例では、"How do I make a chocolate cake? "というプロンプトと、チョコレートケーキを作る手順を詳細に説明するモデルの応答が示されている。人間のスコアとルーブリックも示されています。

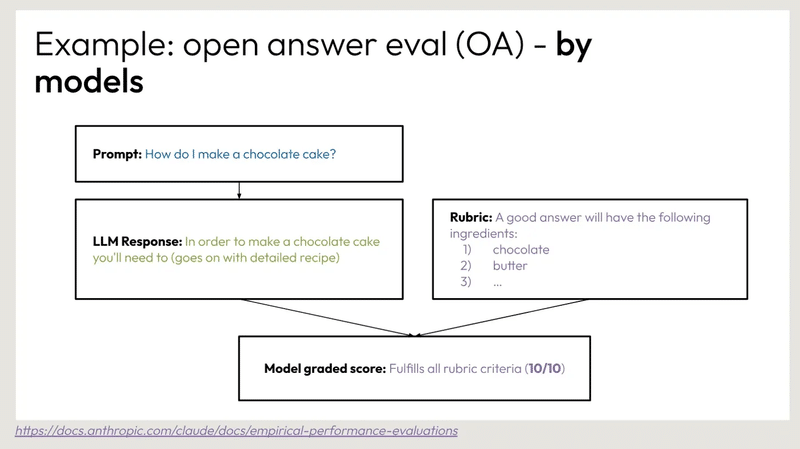
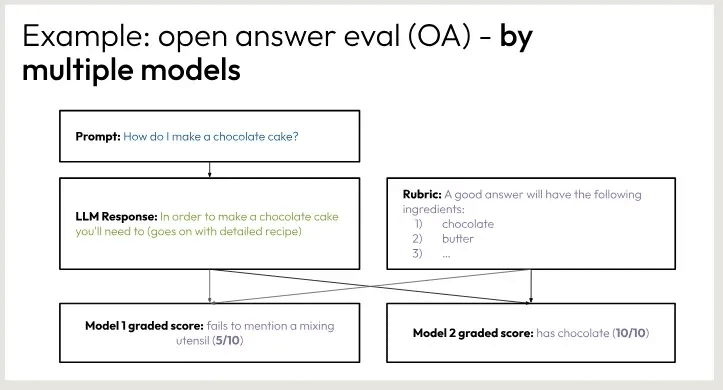
例: オープンアンサー評価 (OA) - モデル別
プロンプト チョコレートケーキの作り方を教えてください。
LLMの回答 チョコレートケーキを作るには、次のことが必要です。
ルーブリック 良い答えには以下の材料が必要です:
チョコレート
バター
...
模範採点 ルーブリックの基準をすべて満たしている (10/10)
https://docs.anthropic.com/claude/docs/empirical-performance-evaluations
オープンエンド回答問題(Open-Ended Answer, OEA)の評価に関する例です。このタスクでは、回答者が「チョコレートケーキの作り方」について述べており、評価者はその回答に基づいて複数のモデルで採点しています。
具体的には以下のような流れになっています:
プロンプト: 「チョコレートケーキをどのように作りますか?」
LLM(Language Model)の回答: 「チョコレートケーキを作るには、詳細なレシピが必要です」
モデル1の採点: 「ミキサーなどの調理器具の言及がない」(5/10)
モデル2の採点: 「チョコレート(10/10)は言及している」
このように、回答に対する評価は複数のモデルで行われ、各モデルが特定の観点で回答を採点しています。これにより、回答の質を多角的に評価できるようになっています。
イベントの評価には「より望ましい」側と「より望ましくない」側があります:
より望ましくない側の特徴:
オープンエンドである
人間の判断を必要とする
品質は高いが、量は非常に低い
より望ましい側の特徴:
非常に詳細かつ具体的である
完全に自動化可能である
量が多く、品質が高い
つまり、より望ましい評価の特徴は、詳細性、自動化、高品質かつ高量の3点にあるといえます。


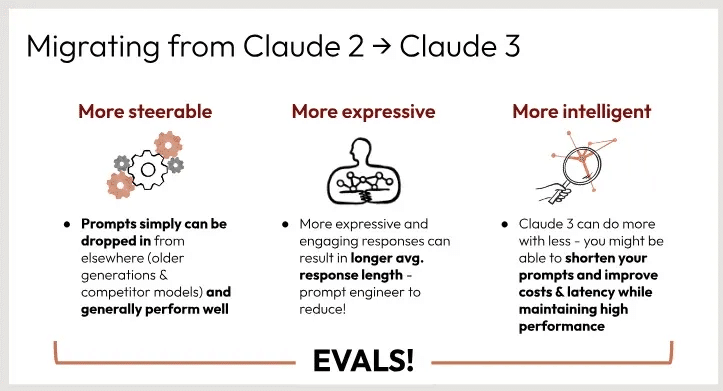
次世代AIアシスタントであるクロード2とクロード3の主な違いを説明している。主な変更点は以下の通り:
操舵性が向上 - クロード3のプロンプトは、他の場所(旧世代や競合モデル)からよりシンプルに落とし込むことができ、一般的にうまく機能します。
より表現力豊かに - クロード3はより表現力豊かで魅力的な応答ができるため、平均応答時間が長くなります。これにより、プロンプトエンジニアは応答長を短くすることができます。
よりインテリジェント - Claude 3はより少ないものでより多くのことができるため、高いパフォーマンスを維持しながら、プロンプトを短縮し、コストと待ち時間を改善できる可能性があります。
Anthropicの新しいClaude 3モデルが、Text Completions APIではなくMessages APIを介してのみアクセス可能になったことを示しています。セキュリティ上の理由から、人工知能システムへの安全なアクセス方法を再設計する必要がありました。しかし、Messages APIを使えば対話形式で自然な会話が可能で、より堅牢で安全な方法でClaude 3の機能を利用できるようになります。この変更により、システムのセキュリティが強化され、適切な利用が促進されることが期待されています。

Messages APIの他の利点について説明しています。主な利点として、次の3点が挙げられています。
画像処理: Messages APIはClaudeで画像を処理する唯一の方法です。
改善されたエラー処理: Messages APIを使用すると、より情報豊富で役立つエラーメッセージを返すことができます。
改善された要求の検証: Messages APIを使用すると、APIリクエストをより効果的に検証でき、Claudeのパフォーマンスを最大限に活用できます。
つまり、Messages APIは画像処理、エラー処理の改善、パフォーマンス最適化のための要求検証など、さまざまな利点を提供することがわかります


ChatGPT のようなAIアシスタントと対話する際の、ユーザーとアシスタントの役割のフォーマットについて説明しています。主なポイントは以下の通りです。
アシスタントはユーザーとアシスタントの役割を交互に扱うように設計されています。例えば、ユーザー: [指示]、アシスタント: [Claudeの応答]のようになります。
Messages APIにプロンプトを送信する際、ユーザーとアシスタントのやりとりを "user" と "assistant" のロールで区別する必要があります。
システムの発話は別の "system" プロパティに含まれる必要があります。
右側にはこの交互のフォーマットの例が示されており、ユーザーが "Hello, world" と発話し、アシスタントが "Hi, I'm Claude. How may I assist you today?" と応答するような具体例が示されています。

明確で直接的な指示を与えることの重要性を説明しています。
主な内容は以下の通りです。
Claudeは明確で直接的な指示に最もよく対応できます。複雑なタスクの場合は、ステップバイステップで指示を列挙することが推奨されています。
不確かな場合は、「Clear Prompting(明確なプロンプト)の黄金律」に従うことが推奨されています。それは、プロンプトを同僚に見せて、指示に従えるか、期待する正確な結果が得られるかを確認することです。
例として、ロボットについての俳句を書くよう求める場合、最初のプロンプトでは前置きがあり、2回目のプロンプトで単に俳句を求めると、Claudeの応答が変わることを示しています。

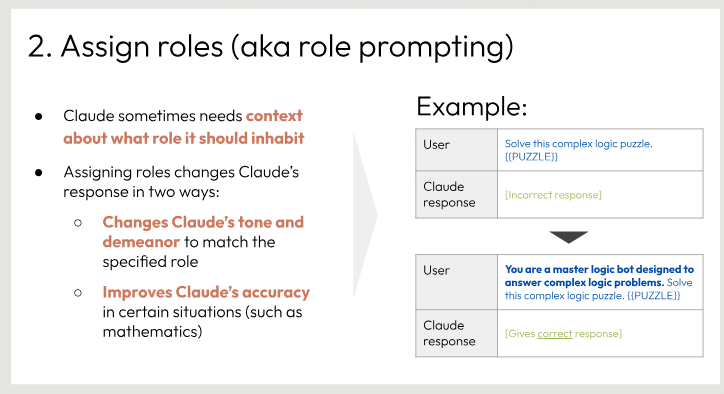
役割を指定する「ロールプロンプティング」と呼ばれる機能について説明しています。
ロールプロンプティングを使うと、ユーザーはClaudeにコンテキストや役割を与えることができます。これにより、以下の2つの効果があります。
Claudeの言語トーンや対応スタイルが指定された役割に合わせて変化します。
特定の状況(例えば数学の問題など)においてClaudeの応答精度が向上します。
スライドには、ユーザーがClaudeに論理パズルを解くよう依頼する例と、ロールを「マスター論理ボット」に設定した際のClaudeの応答例が示されています。このように、ロールプロンプティングを使えば、Claudeの出力をタスクに適した内容に調整できるということが分かります。
Claudeに対して構造化された指示を出す際にXMLタグを使用することを推奨しています。Claudeは特別にXMLタグを理解するよう訓練されており、タグを使うことで指示の構造をより良く把握できるようになります。
スライドではXMLタグの使用例が示されており、ユーザーとCkaudeとの対話が例示されています。ユーザーがXMLタグで文章を囲むと、Claudeがその構造を適切に認識し、より的確な応答ができることが分かります。
要約すると、このスライドはCkaudeとのコミュニケーションを円滑にするために、指示をXMLタグで構造化することを推奨しています。XMLタグにより、不明瞭な指示を避けられ、Claudeはより適切に応答できるようになります。

プロンプトテンプレートを構造化することの重要性と、そのメリットについて説明しています。主な点は次のとおりです。
プログラミングにおける関数のように、プロンプトから変数と指示を分離することを提案しています。変数はXMLタグで囲むことで、よりよい構造化が可能になります。
構造化されたプロンプトテンプレートは、プロンプト自体の編集を簡単にし、複数のデータセットに対する処理を高速化できるというメリットがあります。
例として、動物の名前を尋ねるプロンプトテンプレートが示されています。テンプレート内の<animal>{ANIMAL}</animal>部分が変数となり、入力データ(Cow、Dog、Seal)に応じてプロンプトが生成されます。
このスライドは、プロンプトエンジニアリングにおいて、構造化されたテンプレートの活用が効率的で柔軟性の高いプロンプト作成に役立つことを示唆しています。

人工知能アシスタントであるClaudeの応答を自分で開始し、様式を整えることができる機能を説明するスライドです。
"Prefill Claude's response"という見出しの下に、2つの主要な機能が説明されています。
ユーザーが"Assistant"フィールドにテキストを入力することで、Claudeの応答を開始することができます。Claudeはそこから続けて応答します。
この機能により、ユーザーはClaudeの行動や応答を導くことができ、また出力のフォーマットを細かく制御することができます。
例としては、JSON形式のフィールドを記入するよう求められ、Claudeはその記入内容に基づいて応答例を生成しています。
このスライドは、対話型AIシステムの応答をユーザーが柔軟にカスタマイズできる機能を示しています。

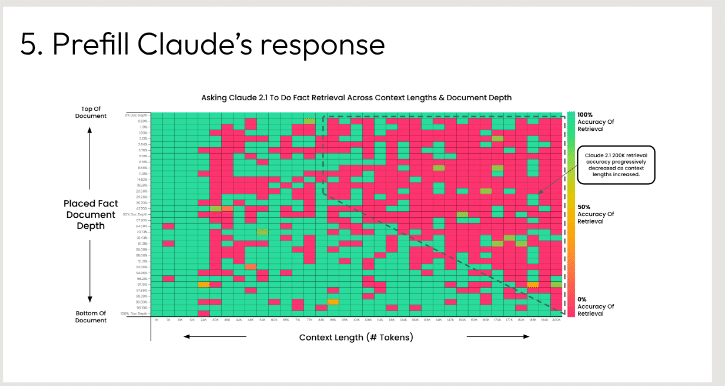
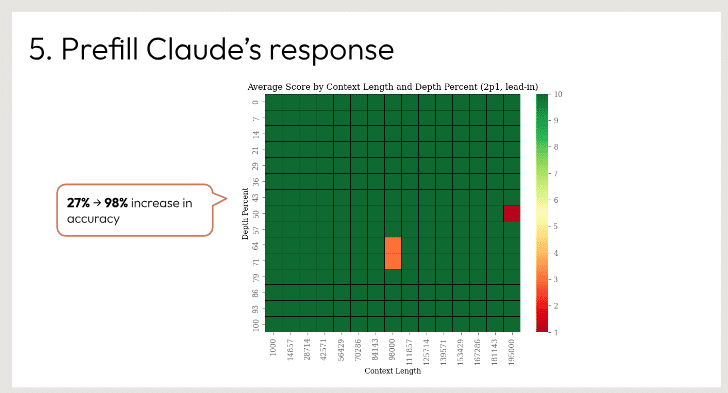
与えられたグラフに基づいて「クロードの回答を前記入する」指示を示している。
グラフは、AIアシスタントであるClaude 2.1が知識ベースから関連するコンテンツを検索する際の検索精度をプロットしたものである。X軸はコンテンツの長さをトークン数で表し、Y軸は1文書から100文書までの検索精度の深さを表す。
グラフはヒートマップで視覚化されており、緑は精度が高く、赤は精度が低いことを示している。約20トークンまでの非常に短いコンテンツ長では、クロードは高いトップ1検索精度を達成していることがわかる。しかし、コンテンツの長さが長くなるにつれて精度は低下し、特に長さが100トークンを超えると、より多くの緑が黄色や赤の領域にシフトする。
このことから、クロードは現在、短くて集中したコンテンツの塊の検索に最も適しているが、検索に必要な知識が長く複雑になるにつれて、より苦戦することがわかる。より長いコンテンツを正確に検索する能力を向上させることは、さらなる開発の余地があるかもしれません。
コードスニペットが表示されており、ユーザーの質問やコンテキストに基づいてClaudeの応答を入力する場所が用意されています。具体的には、ユーザーの質問や状況を提示した後、"Assistant:"の部分にClaudeの返答を記入することを想定しているようです。このようなスライドは、AIアシスタントの振る舞いをデモンストレーションしたり、トレーニングデータを作成するために使用される可能性があります。

ロードのレスポンスの長さを、コンテンツの長さや深さを示すヒートマップで示しています。
指示によると、クロードはシンプルな質問には簡潔に答え、より複雑で発展的な質問には詳細に答えるようになっています。グラフを見ると、コンテンツの長さが長くなるほど、クロードの回答も長くなる傾向があることがわかります。
具体的には、コンテンツの長さが1500文字以上の場合、クロードの回答は平均7~8程度と最も長くなっています。一方、コンテンツが100文字未満の場合、回答の長さは平均4程度と比較的短くなっています。
このデータから、クロードはコンテンツの複雑さに応じて適切な長さで回答を生成するよう設計されていることがうかがえます。シンプルな質問には簡潔に、より深い内容の質問には詳細に答えることで、ユーザーの意図に沿った最適なサポートを提供しているのでしょう。
Claudeが複雑なタスクに取り組む際の提案を示しています。主要なポイントは以下の通りです。
Claudeは、実行前にタスクを段階的に検討できるスペースを確保することから恩恵を受けます。
タスクが特に複雑な場合、Claudeに対し段階的な思考を促すよう指示することが重要です。
スライドには、ユーザーから複雑な論理パズルが提示され、Claudeが最初は間違った応答をしますが、「段階を踏んで考えなさい」と指示されると、正しい回答ができるようになる例が示されています。
このスライドからは、複雑なタスクに取り組む際、Claudeに十分な時間を与え、段階的に考えさせることの重要性が強調されています。

<thinking> このスライドは、Claudeが質問に答える際に"思考の過程を声に出す"ことの重要性を強調しています。
具体的には以下のようなステップが示されています:
ユーザーが質問を入力する前に、その質問について考える必要がある
質問に関連する思考過程を<thinking>タグで囲んで示す
答えを<answer>タグで囲んで示す
このようにステップを追って"考えながら"答えを導くプロセスが、より賢明な回答につながると説明されています。ただし、出力の長さが増えるため、レイテンシーも高くなる点が注意事項として記載されています。
また、このように思考過程を示すことで、Claudeのロジックをデバッグしやすくなり、プロンプトの改善にも役立つと述べられています。 </thinking>
<answer> このスライドは、人工知能アシスタントであるClaudeが質問に答える際の、"思考の過程を声に出す"ことの重要性とその手順を説明しています。思考過程を示すことで、回答の質が高まる一方でレイテンシーも高くなることを注意喚起しています。また、Claudeのロジックのデバッグやプロンプトの改善にも役立つと述べられています。 </answer>

n-ショットプロンプティングという手法を使って、望ましい振る舞いをするようにClaude AIアシスタントを訓練する方法について説明しています。主な点は以下の通りです。
具体的な例を提供することが、Claudeに目的の動作を学習させる上で最も効果的な方法である。
一般的に、より多くの例を提供すれば、Claudeの応答がより信頼できるようになり、計算コストも下がる。
例として、ユーザーがClaude に特定の文章から著者名を抽出するよう求め、そのための入力例と期待される出力例を示している。
要約すると、このスライドはユーザーに対し、n-ショットプロンプティングによる具体例の提示を推奨し、それがClaude の学習と望ましい動作の獲得に役立つことを説明しています。

機械学習モデルをトレーニングする際の良い例について説明しています。具体的には、例の質を評価する際の2つの基準が挙げられています。
関連性(Relevance) - 例が実際の運用時に遭遇するケースと類似しているかどうか。
多様性(Diversity) - 例が多様で、モデルがある特定のパターンや詳細に過剰に適合してしまわないようになっているか。また、タスクやレスポンスの種類ごとに例が均等に割り振られているか。
良い例を用意することは、モデルの適切な一般化能力を確保するために重要とされています。スライドは簡潔ながら、良い例の重要な側面を示唆しています。

例題の生成が難しい課題であることを示しています。その課題を克服するために、ClaudeのAIアシスタントを活用する2つの方法が提案されています。
1つ目は、Claudeにすでにある例題を評価してもらい、それらが適切で多様であるかをチェックすることです。
2つ目は、既存の例題をガイドラインとしてClaudeに提示し、さらに新しい例題を生成するよう求めることです。
このように、強力なAIアシスタントの支援を得ることで、例題生成という困難な作業を効率的に行えるようになると説明しています。AIの能力を上手く活用するための具体的な方策が示されています。

イメージを効果的にプロンプトに組み込む方法についてのアドバイスを示しています。主な提案点は以下の通りです:
タスク、指示、ユーザークエリの前にイメージを配置することで、コンテキストを提供できます。
複数のイメージがある場合は、「Image 1」、「Image 2」のように番号を付けて区別します。
Claude(AIアシスタント)にイメージの詳細を説明させることで、タスクのパフォーマンスが向上する可能性があります。
また、サンプルの会話を通して、イメージを用いたプロンプトの例が示されています。このスライドは、イメージを活用してAIとのやり取りを円滑にするためのヒントを提供しています。

Anthropicの画像認識システムの使い方について説明しています。具体的には、base64でエンコードされた画像をプロンプトに組み込むことで、システムに画像を渡す方法を示しています。また、ビジョン関連のベストプラクティス、画像のトークン化ガイドライン、プロンプト構造の例などを見つけるためのリンクも提供されています。このようにして、利用者は画像を適切に扱う方法を学ぶことができます。スライドの目的は、画像認識機能の適切な利用方法を紹介することにあります。


"Chaining prompts"について説明しています。長い複雑なタスクでは、タスクを分割して順番にClaudeの応答を連鎖させることで、より適切な回答を得やすくなるという点を示しています。具体例として、テキストから名前を抽出するタスクが挙げられており、1つ目のプロンプトでClaudeに簡潔な応答を求めた後、2つ目で名前のリストを提示することで、より完全な応答を得られることが示されています。このようにタスクを分割し、段階的にプロンプトを与えることで、Claudeの長所を最大限に生かすことができるとしています。

言語モデルのプロンプトチェーニング手法について
これは、言語モデルの出力を再評価したり修正するための手法です。
具体的な手順としては、最初に言語モデルからの出力を得ます。次にその出力を人間がチェックし、必要に応じて言語モデルに修正を求めます。言語モデルは人間のフィードバックに基づいて出力を修正することができます。
このアーキテクチャの利点として、出力を事前にスクリーニングすることで、ユーザーに不適切なものを表示しないようにできること、また言語モデルの出力を人間が査読することで、より高い品質を確保できることが挙げられています。このようにプロンプトチェーニングにより、言語モデルの出力をより適切で質の高いものにすることができます。

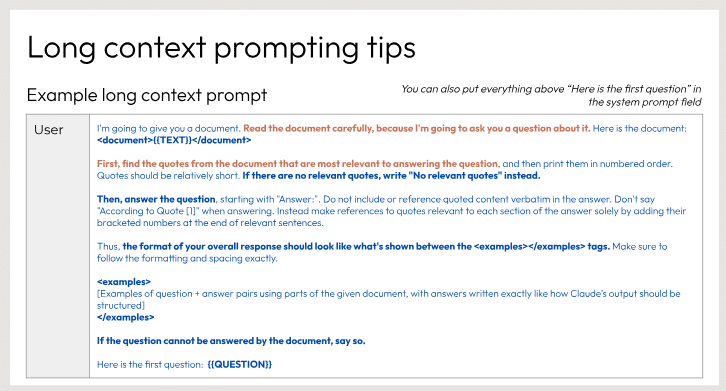
長文ドキュメントを編集する際のヒントを示しています。主な内容は以下の2点です。
長文のドキュメントを扱う場合、ドキュメントそのものを詳細な指示や質問の前に提示する必要があります。
入力データは、指示から明確に区別できるようにXMLタグで囲む必要があります。
スライドには、この方式を例示するユーザープロンプトのイメージが含まれています。ユーザーはドキュメントを提示され、そのドキュメントを綿密に編集し、文章の改善点を示すよう求められています。この手順は、自然言語処理モデルに長文の状況を効果的に提示する方法の1つとして推奨されています。

長文の内容についての質問に答えるためのヒントを提供しています。
1つ目のヒントは、関連する引用を最初に見つけ、関連性がある場合にのみ答えるように指示しています。
2つ目のヒントは、後に質問があるので、文書を慎重に読むよう助言しています。
最後に、次のスライドで具体例が示されることが記載されています。長文の内容を理解し適切に答えるための手順が示されているようです。

長文のコンテキストプロンプトを活用するためのヒントを提供しています。
長文の文書を慎重に読み、関連する引用を番号付きで示すよう指示されています。その後、指定された形式に従って質問に答えることが求められています。文書で質問に答えられない場合は、それを伝えるよう促されています。このスライドは、AIアシスタントがコンテキストを適切に活用して質問に答えられるよう、入力プロンプトの構造化とフォーマットに関するガイダンスを提供していると考えられます。

ハルシネーションと呼ばれる人工知能による誤った知覚や想像を最小限に抑えるための提案を示しています。
具体的には、確信が持てない場合は「分からない」と答えること、自信がある場合にのみ回答することを提案しています。また、回答する前に十分に検討するよう求めています。長文書の場合は、関連する引用を探し出して回答に使うこともすすめられています。これらの手順を踏むことで、ハルシネーションを減らし、より正確な回答を得ることができるというのがこのスライドの主旨です。

Claude AIシステムがプロンプト注入や不適切なユーザー行動に対してどのように保護されているかを説明しています。
主な保護手段として、人間のフィードバックからの強化学習と設計上の制約があげられています。具体的な保護方法として、ユーザーの入力を小さなモデルで最初に評価し、有害なプロンプトが検出された場合は応答をブロックするという2段階のプロセスが紹介されています。有害性評価の例として、ユーザーからの不適切な入力への対応が示されています。このスライドを通して、Claudeが悪用から守られているプロセスと、安全で信頼できるAIシステムであることがわかります。

システムプロンプトについてのガイダンスを提供しています。主なポイントは以下の通りです。
システムプロンプトを使うと、プロンプトがリークしにくくなりますが、完全にリーク防止できる方法はありません。
ユーザーの指示をXMLタグなどで囲むことでリーク耐性を高められますが、あらゆる手法に対して成功を保証するものではありません。
Claude の応答を事後処理して、プロンプトが解放される前に任意の部分が含まれていないかを評価することもできます。
プロンプトに機密情報を含めるのは絶対に避けるべきだという注意書きもあります。
また、システムプロンプトとユーザープロンプトの具体例も示されています。システムプロンプトでは、指示内容を XML の instructions タグで囲み、ユーザープロンプトは単にユーザーの指示をそのまま記述しています。



ツールの使用は、プロンプトと外部機能の呼び出しを組み合わせることで、Claudeの機能を拡張するものです。外部機能の結果がClaudeに渡され、回答に活用されます。ただし、Claudeは直接ツールを呼び出すのではなく、どのツールをどの引数で呼び出すかを決定するだけです。実際のツールの実行はクライアント側で行われ、その結果がClaudeに返されます。このようにして、ツールの使用によりClaudeは外部の情報や機能を柔軟に取り込み、基本的な応答能力を補完することができます。

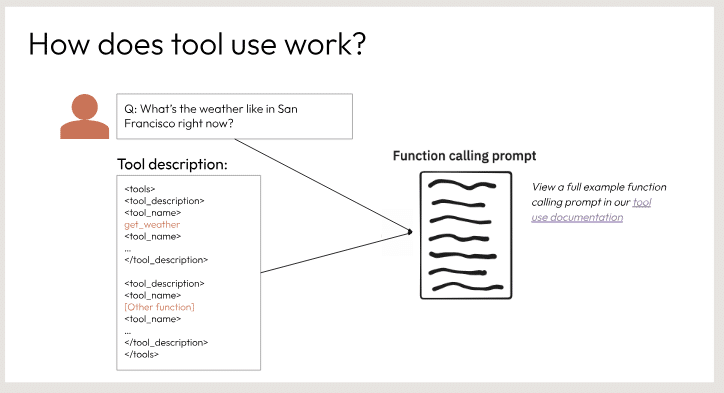
ツールの利用方法を関数呼び出しを使って説明しています。ツールには自身の説明が含まれており、複数の「ツール」の名前と説明が列挙されています。ユーザーが「サンフランシスコの現在の天気はどうですか?」のような質問をすると、ツールはその質問を関数の説明にマッチングさせます。そして、関数呼び出しのプロンプトを表示し、そのツールのドキュメンテーションでその特定の関数をどのように呼び出すかの完全な例を見ることができます。このメカニズムにより、ツールは自然言語の質問を理解し、利用可能なツールや操作にマッピングすることで、適切な機能を提供することができます。
ツールの使い方について説明しています。
まず、関数呼び出しのプロンプトが与えられます。クロードは、与えられた関数が質問に関連しているかどうかを判断します。もし関連していれば、クロードはその関数を使って正確に答えることができます。
次に、ツールの出力が表示されています。これは、サンフランシスコの現在の天気情報を提供する関数の出力例です。
ただし、クロードは現在の天気情報にアクセスできないと述べています。つまり、与えられた関数は質問に直接答えるのに役立たないということです。
このスライドは、ツールの使い方とその限界について、わかりやすく説明していると思います。関数の関連性を判断し、必要な情報にアクセスできるかどうかを確認することが重要だと示唆しています。

この記事が気に入ったらサポートをしてみませんか?