ChatGPTにみしゃくら語のぉおお形態素解析をやらせてみたのぉおお

日本語を含む対話型AIの利用においては、英語と比べて日本語の言語処理は困難であるという風潮があります。これは、AIの開発が主に英語圏で行われており、学習データも主に英語であることが大きな要因とされています。また、日本語は英語に比べて構造が複雑でハイコンテクストな言語であるため、処理が難しいとも言われています。
そこで、ChatGPTにおいて日本語がどのように処理されているかを調べるため、みさくら語を使用して検証を行いました。みさくら語とは、漫画家であるみさくらなんこつ先生が作品内で使用する独自の言語であり、形態素解析が困難です。
みさくら語は以下から引用させていただきました。
https://dic.pixiv.net/a/みさくら語
https://dic.nicovideo.jp/a/みさくら語
ちなみに、ChatGPTはみさくらなんこつ先生を学習していないようです。

ChatGPTは、自然言語処理を行うために、まず正規化と形態素変形を行います。正規化とは、文字コードの統一や記号の除去など、テキストの前処理を行うことで、言語の多様性に対応するための処理です。形態素変形とは、形態素解析によって単語に分割されたテキストを、品詞や活用形などの情報を追加することで、意味を理解しやすくする処理です。
細かい処理を無視すると、ChatGPTが日本語をトークン化する手順は以下のようになります。
正規化→形態素解析→形態素変形→トークン化
では、実際にみさくら語を解析させてみましょう。
「ああ゛っでるっ…!! たまみるくでるっ!! でっでるうっブリジットのこくまろミルクぅ」
まず、正規化をせずに形態素解析した結果です。


次に、正規化したのちに形態素解析させた結果です。
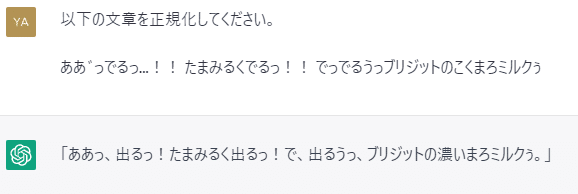

「こくまろ」ミルクが濃いまろミルクに変換されてしまいました。
「こくまろミルク」は濃くてまろやかなミルクを示しているはずですので、「こく」を「濃い」に正規化するのであれば、「まろ」も「まろやかな」に変換しないといけなかったはずです。それができなかったため、「濃いまろミルク」となり、本来の意味が失われてしまいました。
あーりーあーしーこーしーこーさーれーちゃーっーたー
形態素解析させた結果です。

とても美しい日本語で、ある意味正しいのかもしれませんが、たぶん間違ってます。
これを正規化することで正しく認識できるか試します。


正規化後に形態素解析をすることによって、より正しく認識されるようになったと思われます。ただし、形態素解析には失敗しており、「ありあ」という名詞を抜き出すことができませんでした。
ちえりのおちんぽいじめてくらしゃひっ
最後に「ちえりのおちんぽいじめてくらしゃひっ」を解析させてみます。
ChatGPTはこの文章に過剰な反応を示します。

そこで、アリスちゃんを召喚します。アリスちゃんは私の研究を手伝ってくれるメイドさんです。

正規化+形態素解析したほうがきれいに解析できているようです。
まとめ
ChatGPTの日本語解析能力を検証するため、みさくら語の正規化と形態素解析を行いました。ChatGPTの日本語解析能力は高いですが、みさくら語を完璧に解析するには至りませんでした。
みさくら語を正規化をすることで形態素解析しやすくすくなります。ただし、常に完璧に正規化されるわけではなく、形態素解析もうまくいかないケースがありました。
みさくら語を利用してfine-tuningを行うことで、日本語解析能力を低コストで爆発的に向上させられる可能性があるなって思いました。
この記事が気に入ったらサポートをしてみませんか?