
ベクトル検索とは何か?そのメリットとは?エンジニアじゃない人向けのざっくり解説

検索の仕組み
現代の世の中の検索の仕組みは大きく分けて3つあります。
・文字列比較での検索
・全文検索
・ベクトル検索
それぞれ説明していきます。
文字列比較での検索
この検索は文章中に文字が含まれてるのか逐次チェックする方法です。
例えば
「この検索は文章中に文字が含まれてるのか逐次チェックする方法です。」に検索という文字が含まれてるのか、最初から順番に文字の一致をチェックします。まず1文字目をチェックします。”こ”なので違います。2文字目は”の”なので違います。という感じです。3文字目で”検”なので1文字目は合ってます。次の文字が”索”かどうかチェック、というような流れになります。
実際には検索文字の後ろからチェックしてたりとかいろいろな最適化の方法がありますがざっくりとした理解としては一文字ずつ比較して探している感じです。この方法のデメリットは検索にとても時間がかかるという事です。
全文検索
文字列の比較での検索は全ての文字列を走査する必要があるため検索に時間がかかります。論文などで300ページあるドキュメントとかだととても時間がかかることになります。それを解決するのが全文検索です。
全文検索は事前に転置インデックスという目次を作っておき、キーワード→ドキュメントIDという流れで検索をします。
例えば以下の3つのドキュメントがあるとします。
Doc1:「昨日は雨で風が強かった」
Doc2:「今日は曇りで時々雨でした」
Doc3:「明日は晴れる予定です」
これらのドキュメントから転置インデックスを作ります。転置インデックスとはキーワードからドキュメントIDを引くための目次になります。
昨日:Doc1、Index=0
今日:Doc2、Index=0
明日:Doc3、Index=0
雨:Doc1、Index=3
雨:Doc2、Index=3
風:Doc1、Index=5
曇り:Doc2、Index=3
晴れる:Doc3、Index=3
予定:Doc3、Index=6
という感じです。雨というキーワードで検索した場合、インデックスから検索するだけなので走査対象の文字列が大幅に減ります。4000文字のドキュメントの文字列を全て順番に比較する検索方法と比べるとインデックスから検索するほうがパフォーマンスが向上します。
ベクトル検索
ベクトル検索はAIによって生成された数値情報から検索を行います。詳しい部分は簡単な表現にして仕組みを解説していきます。
以下のような単語を考えます。
・投資
・クレジットカード
・ホテル
・アフタヌーンティー
・ドーナツ
・目玉焼き
・ソーセージ
・ビール
・ケグ
類似度で単語を並べてみます。多分こんな感じになるでしょう。(適当です)

プログラムから扱えるように数値を振ります。
・投資 -0.9
・クレジットカード -0.8
・ホテル -0.5
・アフタヌーンティー -0.4
・ドーナツ -0.3
・目玉焼き 0.1
・ソーセージ 0.5
・ビール 0.7
・ケグ 0.8
「ソーセージ」という単語で検索した場合、数値が近い順に検索結果を表示します。距離の絶対値を計算すると
ビール→0.2(0.7-0.5)
ケグ→0.3(0.8-0.5)
目玉焼き→0.4(0.5-0.1)
という感じです。
埋め込みデータの作り方
さてこの数値はどうやって出しているのでしょうか?これはいろいろなドキュメントに含まれる単語の出現頻度などを元に計算します。いろんなHPやブログ、SNSの投稿や論文などのドキュメントを解析します。以下のようなドキュメントを考えてみましょう。
「今朝はホテルの朝食で目玉焼きを食べたぞ!うまい!」
「当ホテルでは1流シェフによる朝食を楽しめます。目玉焼きなどのオーソドックスなものから…」
「ビールにはやっぱりソーセージが合うね!うまかった!」
「ハイステータスなクレジットカードでホテルにチェックインすると、部屋をアップグレードしてくれることもあり…」
「ホテルのアフタヌーンティの3段になってるやつ、どこから食べるか悩むよね?」
「ここのホテルの風呂は特に問題なく普通らしい。シャワーの水圧は重要」
「ホテルと旅館、どっちにしようかな?温泉も気になるな♪」
「温泉でゆっくりして、明日はお城と神社巡り!」
「やはりワインにはチーズが合う!まいうー」
「ケーキとドーナツはギルティ…今週末に事務でもいくか!」
「健康維持のために最近はブロッコリーと鶏肉を食べまくってます!」
「クレジットカードで靴とバッグを買ってしまった…支払いが心配」
こういったドキュメントを学習元のデータとして分析をします。いろいろなドキュメントを見ると「ある単語が出現するドキュメントに同じく出現する単語」というものが存在します。一緒に出現する頻度、2つの単語間の距離などを数値化することでこういった意味の近さといったような類似度を数値化できます。
(※実際には専門家が研究を重ねもっといろいろな指標で数値化をしてます)
とても簡単な理解だとこういった出現頻度などの指標をベースに類似度を計算しているイメージです。
例は一般的なものにしましたが、業務の社内規則のドキュメントや役所の問い合わせページなどでも有効です。給与とボーナスは類似度が高いでしょうし、引っ越しと住民票なども類似度は高いでしょう。
ベクトル空間
先ほどは説明を一番簡単にするために直線上に単語を並べてみましたが、2次元の方がもっと柔軟に並べられそうです。

2次元のほうがホテル、アフタヌーンティー、目玉焼きの距離感がより柔軟に設定できそうですね。2次元であれば3つの距離が同じというような配置が可能になります。1次元ではそのような配置はできません。
データの表現ですが2次元の場合は
目玉焼き:[0.2, -0.4]
という形のデータになるでしょう。高校の数学でならった関数やベクトルなどでの座標の表現になります。
もっと言えば3次元のほうがさらに柔軟に距離や角度を設定できますし、もっと言えば1536次元の方がより良さそうです。1536次元の場合
目玉焼き:[0.2, 0.5, -0.12, -0.4354, 0.982….]←1536個数値が並ぶ
というデータになります。
この数値の羅列のデータのことを埋め込みデータ(Embedding)と言い、OpenAIや他のAI企業が公開しているAPIを使うと文字列のデータからこの埋め込みデータを生成できます。
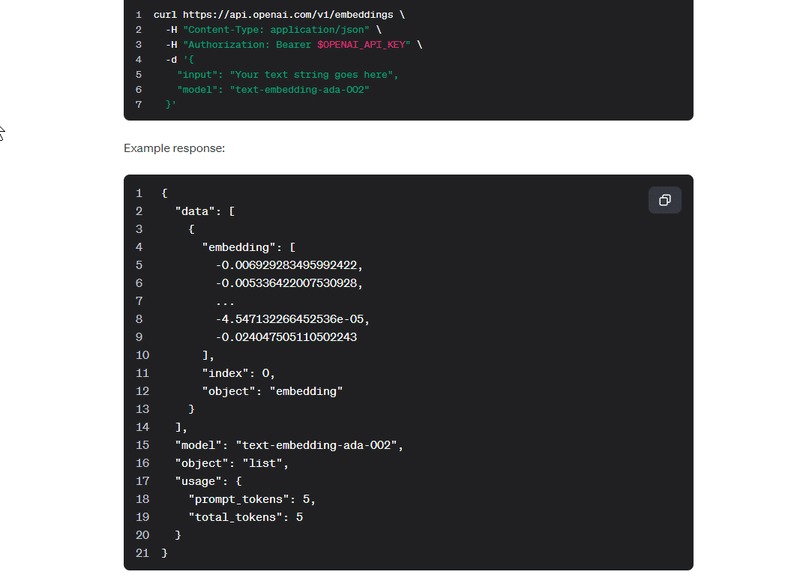
各ドキュメントの埋め込みデータが出来たらあとは計算するだけです。中学校で習った点と点の間の距離だったり、点と点の角度(コサイン類似度)だったりの数値を計算し、近いモノ(絶対値が小さいモノ)から順番に抽出することで検索結果を取得できます。
2点間の距離(金沢大学のHPより)
例えばソーセージで検索すると、この図を見ると

ソーセージの近くには目玉焼きとビールがあるのでその2つが検索結果として出てくるイメージです。
ベクトル、コサイン、みなさんも高校で習いましたね。私はほとんど忘れてますが(汗)その辺が使われてる感じです。
ベクトル検索のメリット
ベクトル検索のメリットは何でしょうか?順番に解説していきます。
検索速度
ベクトル検索の距離の計算は単純な数学的な計算なため、とても処理が速いです。内部的にはANNアルゴリズムやSScaNNなどを活用した手法などde
高速され素早く検索結果を取得できます。
※Googleのベクトル検索の解説↓
意味で検索できる
全文検索ではその仕組み上、検索キーワードが含まれているドキュメントだけが検索されます。ベクトル検索では意味が近いモノが検索されます。全文検索では引っかからないドキュメントも検索に引っかかることで検索結果のクオリティが向上します。
興味深いのは誤字があっても検索に引っかかるということです。先ほどの文章例で誤字があったのに気づきましたか?
「ケーキとドーナツはギルティ…今週末に事務でもいくか!」
ジムが事務になっています。しかしこれでも検索に引っかかります。これは何故かというと学習元のドキュメントに同じように誤字が含まれていて、それを元にデータを作るからです。なので多くの人が間違いそうな誤字などは自然と検索に引っかかるようになります。面白いですね。
画像・音声・動画も検索できる
ベクトル検索はその仕組み上、埋め込みデータのコサイン類似度を計算しているだけなので、画像や動画から埋め込みデータを作れれば類似する動画を検索することも可能になります。これは全文検索ではできないため、大きなメリットになります。埋め込みデータの生成さえできれば、「笑える面白いコンテンツ」といった人間が捉えるような意味の類似で検索が可能になるはずです。
まとめ
以上、2023年の検索の簡単な説明でした。業務では
・営業の製品カタログを元に適切に提案できるようにしたい
・問い合わせに対して的確な回答を検索したい
・関連が深い論文を素早く検索したい
などでベクトル検索は活用できそうです。この辺はまた今後。
読んで「ベクトル検索の理解が深まった!」という方はよかったらフォローといいねお願いします!
この記事が気に入ったらサポートをしてみませんか?