
【stable diffusionプロンプトジェネレーター】おすすめ設定

皆さんこんにちは!stable diffusion(ステーブルディフュージョン:以下SD)のプロンプトジェネレーターを公開しています。
SDのプロンプトを比較的簡単に作成できるツールなので、ぜひ見てみてください(^^)
今回は、このプロンプトジェネレーターを使ううえ、設定してほしいSDの設定項目について紹介します。
設定してほしい箇所一覧
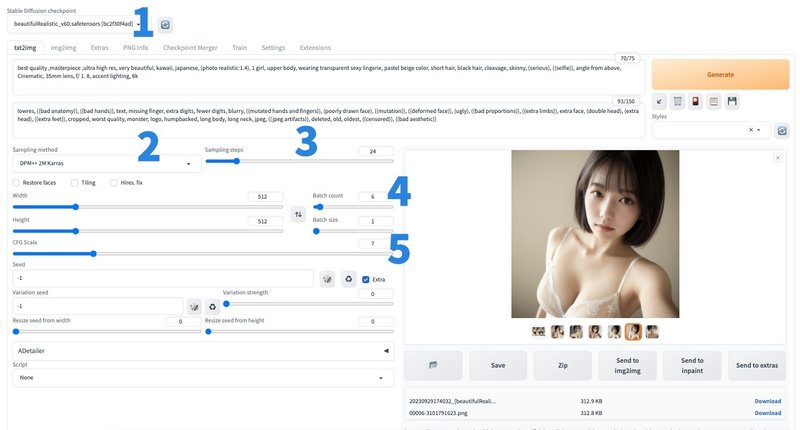
1〜5までの番号が振られているところです。
他にも色々調整しても大丈夫なので、設定項目について詳しい方はご自身で設定してみてください。
今回は、「どこをどう設定して良いか分からない」人向けです。
それでは見ていきましょう。
1,学習モデルの設定(必須)
SDは、学習モデルを切り替えができます。
学習モデルというのは、SDが画像を描画するのに学習モデルの内容を学習して、その学習内容から画像を描画します。
学習モデルを切り替えることで、美女を比較的に簡単に出力できるようになります。この学習モデルについては、美女が出やすいものであれば問題なさそうですが、基本的にはBRAV5またはBRAV6という学習モデルがおすすめです。
2,サンプラーの選択
SDの場合は、画像を生成するときに、1枚の画像からノイズを除去して画像の描画を行います。ちょっとむずかしい仕組みなので、覚えなくても問題ないです。
サンプラーというのは、ノイズを除去する方法を選択するということで、出来上がる画像のクオリティに影響があります。
Euler a
DPM++ SDE Karras
DPM++ 2M Karras
DDIM
このあたりを選択すると問題ないです。
3,サンプリングステップ数
一つ前のサンプラーの項で、SDは画像からノイズを除去するという話をしましたが、ノイズを除去する回数を決めるのがこの設定です。
単純に数値を上げると生成される画像のクオリティが上がりやすくなります。ただし、その分画像生成にかかる時間が増えます。
おすすめは20から25の間くらいが良いかなと思います。
4,一度に出力する画像の枚数
Batch countと書かれているところです。
これは、一度に出力する画像の枚数を指定するものです。6と入力すると1回の生成で6枚の画像が出てきます。単純にしてした数だけ処理を繰り返すものです。
SDはガチャのような仕組みで、期待どおりの画像を手に入れるには何回か出力を繰り返す必要があります。この数値を上げておけば、一度の出力で数枚の画像が出てくるので便利です。
5,プロンプトに対してどれくらい忠実に出力するか
CFG Scaleと書かれています。
これは、プロンプトに対してどれだけ忠実に画像を再現するかの設定です。数値を上げると忠実度が増えます。
これにはデメリットがあり、数値を上げると画像のクオリティが下がりやすくなります。
プロンプトの忠実度を上げたい(プロンプト通りの画像がなかなか出ない)ときには、少し数値を上げてみるのも良いでしょう。
出力された画像を見ながら調整してみてください。
以上になります。
SDには他にもたくさんの設定項目があります。気になる方は以下の記事も読んでみてください。
この記事が気に入ったらサポートをしてみませんか?