
Python+Selenium+ChromeでウェブスクレイピングしてYouTubeの動画をダウンロードする

Python+Selenium+ChromeでウェブスクレイピングしてYouTubeの動画をダウンロードします.本稿では,OfflibertyをSeleniumでダウンロードします.
前回までの甘茶の音楽工房のダウンロード を実施していましたが,せっかくなのでseleniumをとうしたブラウザの操作をしてみます.
本稿では,OfflibertyというYouTubeのURLをコピペすればダウンロードできるサイトがあったので,これの操作をSeleniumでします.
今回は練習でしたものですので,多分に悪ふざけが入っていますし,def文でまとめてはいません.
こちらでも閲覧できますし,まだnoteにしていない記事もあります.https://www.hamlet-engineer.com/posts/websc_selenium04.html
有料枠設定にしていますが,youtubeの投げ銭的な物として,お考えください.
selenium.webdriverの起動
selenium.webdriverの起動は本サイトのPython+Docker+Selenium+Chromeでウェブスクレイピングをする part3で作成したものを使います.
# ローカル上でselenium.webdriverの起動
def webdriver_local_start():
# versionに応じたchrome driver のインストール
version = chrome_version()
url = 'http://chromedriver.storage.googleapis.com/LATEST_RELEASE_' + version
response = requests.get(url)
options = Options()
options.add_argument('--headless')
# インストールしたchrome driverでchromeを起動
driver = SeleneDriver.wrap(webdriver.Chrome(
executable_path=ChromeDriverManager().install(),
chrome_options=options))
return driver
# docker上でselenium.webdriverの起動
def webdriver_start():
# Chrome のオプションを設定する
options = webdriver.ChromeOptions()
# Selenium Server に接続する
driver = webdriver.Remote(
command_executor='http://localhost:4444/wd/hub',
options=options,
)
return driverSeleniumでGoogle検索する
まず,例題として下記のコードでSeleniumでGoogle検索を実施します.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# selenium.webdriverの起動(ローカル)
driver = webdriver_local_start()
#指定したURLに遷移する
driver.get("https://www.google.co.jp")
#検索テキストボックスの要素を名前から取得
element = driver.find_element_by_name('q')
#検索テキストボックスでシフトボタンを押下しながら"selenium"を入力
element.send_keys(Keys.SHIFT,"selenium")
#カーソルを1文字分左にずらす
element.send_keys(Keys.ARROW_LEFT)
#BackSpaceを1回押下し1文字分消去
element.send_keys(Keys.BACK_SPACE)
#Enterキーを押下する
element.send_keys(Keys.ENTER)
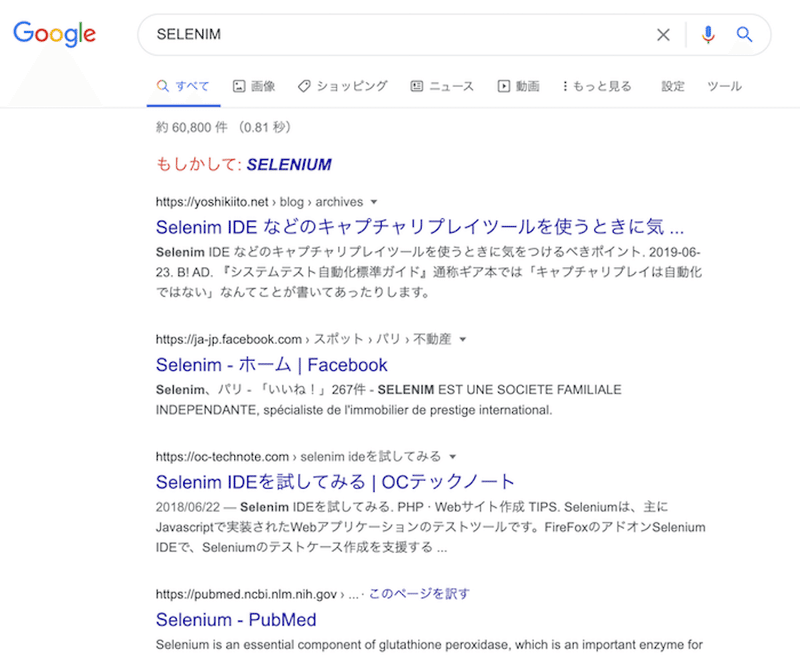
print(driver.current_url)printされたURLをブラウザに表示し,「SELENIM」が表示されていたら,OKです.
offlibertyでyoutubeをダウンロード
ここからはofflibertyにyoutubeのURLをコピペして動画をダウンロードします.

今回,ダウンロードするのはSIRENの奉神御詠歌【ほうしんごえいか】 歌詞付きです.
コピペした後は読み込みに時間がかかるので,奉神御詠歌の歌詞が流れるようにしてます.(<-悪ふざけ)
うまくいけば,1周半で読み込みが完了します.たまに,読み込みがうまくいかない時があるので複数回試す必要があります.
後述の理由でdef文でまとめてはいません.
import os
import sys
import urllib.request
import requests,os,bs4
from selenium import webdriver
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selene.driver import SeleneDriver
from webdriver_manager.utils import chrome_version
from webdriver_manager.chrome import ChromeDriverManager
# ローカル上でselenium.webdriverの起動
def webdriver_local_start():
# versionに応じたchrome driver のインストール
version = chrome_version()
url = 'http://chromedriver.storage.googleapis.com/LATEST_RELEASE_' + version
response = requests.get(url)
options = Options()
options.add_argument('--headless')
# インストールしたchrome driverでchromeを起動
driver = SeleneDriver.wrap(webdriver.Chrome(
executable_path=ChromeDriverManager().install(),
chrome_options=options))
return driver
# docker上でselenium.webdriverの起動
def webdriver_start():
# Chrome のオプションを設定する
options = webdriver.ChromeOptions()
# Selenium Server に接続する
driver = webdriver.Remote(
command_executor='http://localhost:4444/wd/hub',
options=options,
)
return driver
'''offlibertyでyoutubeをダウンロード'''
# selenium.webdriverの起動(ローカル)
driver = webdriver_local_start()
#指定したURLに遷移する
driver.get("http://offliberty.io")
# youtubeのURL
url = 'https://www.youtube.com/watch?v=ZOX6JbecV3Y'
# URL入力箇所を取得
element = driver.find_element_by_class_name("track")
# URLを入力
element.send_keys(url)
#Enterキーを押下する
element.send_keys(Keys.ENTER)
# 読み込み中の処理
# WARUFUZAKE
import time
houshin = ['敬い申し上げる',
'天におわす 御主(おんあるじ)',
'光り輝く御姿で 現れ給う',
'ぐるりや 三つの御印を',
'持って拝み奉る',
'一つや 二つ 三つを',
'過ぎたれば 天の理(ことわり)',
'我ら 父母の咎(とが)に',
'罰を加え給うことなし',
'御主(おんあるじ)のおいでます',
'楽園にお連れ給う',
'-------------']
i = 0
elements = []
while len(elements)==0:
# エラー防止のためにelementsにしてリストで帰って来るようにする.
elements = driver.find_elements_by_class_name("download")
i += 1
houshin_text = houshin[i%len(houshin)]
print(houshin_text)
time.sleep(4)
# 読み込みに4分以上かかれば中止する
if i >= 60:
print('ダウンロード失敗')
sys.exit() # 実行中止
# ダウンロードのリンク先
download_url = elements[0].get_attribute('href')
# 出力ファイル
outdir = './youtube/'
os.makedirs(outdir, exist_ok=True)
title_text = '奉神御詠歌【ほうしんごえいか】 歌詞付き'
file_name = os.path.join(outdir, title_text + '.mp4')
# ダウンロード開始
print('ダウンロード開始:'+ title_text)
urllib.request.urlretrieve(download_url, file_name)
print('ダウンロード完了')まとめ
seleniumに慣れるために,offlibertyというyoutubeをダウンロードしましたが,ぶっちゃけ上記のコードを使うくらいならpytubeを使う方が楽ですので,def文でまとめてはいません.
参考サイト
10分で理解する Selenium
Selenium webdriverよく使う操作メソッドまとめ
【Python】seleniumでWebElementからhtmlを取得する
Python + Selenium + Chrome でファイル保存まわり
Python/SeleniumでChrome自動Google検索
ここから先は
¥ 100
この記事が気に入ったらサポートをしてみませんか?