
Analyticsのデータを加工してみる

こんにちは、辻村です。今回は、Analyticsのデータを REST APIを使って読み出したデータを加工して、グラフにしてみるという内容です。RESTful APIを ZFS Storageで使ってみる例は、以前書かせて頂いた記事が、また、データを読み出す作業自身は、前回の記事が役に立つと思います。
今回のお話
・Analytics のデータのフォーマットについて
・データの加工方法について
・データ加工の際の注意点について
Analytics のデータのフォーマットについて
前回の記事のサンプルコードでは、Analytics のデータを受け取る際、Python の requests パッケージを使っています。受信したレスポンスを json()で変換することによって、Analyticsのデータを辞書の形にすることができます。
グラフにおこしたり、相関を求めたいなら、元データが表形式になってくれていると、わずかな手間で Pandas や R などで読み込むことができて便利です。残念ながら、現在 Analytics のデータは取得したデータによって形式が変わります。従って、読み出したデータを各々解釈し、例えば PandasのDataFrame に変換する必要があります。
【なぜ読み出して加工するのか?】
「グラフなら Analytics があるのでは?」という疑問があると思います。
確かにそうなのですが、Analytics は取ったデータのグラフを複数表示できても、グラフ同士を重ね合わせるとか、部分を切り取ってきて重ねてみるというような処理ができません。そのため、データを読み出した方が有用な場合があります。
Analyticsのデータは、辞書として構成されています。一番上のレベルでは、{"data": <値1>} となっています。この値<値1>にあたるところは、リストになっていて、リストのそれぞれの要素がまた辞書になっています。
{"data:[{辞書1}, {辞書2}, {辞書3}, ... {辞書n}]辞書のそれぞれの項目は以下の通りです。
{
'data': {},
'sample': 425186827,
'samples': 425273227,
'startTime': '20190807T13:30:27'}sample はこのデータポイントについているユニークなシリアル番号です。
samples は返信されてきたデータが何番のシリアル番号で終わるかという数字です。
startTimeは個のデータについたタイムスタンプです。
dataが実データになりますが、ここがさらに3種類の形式に分かれます。まずは上記のようにデータがない場合は、空の辞書が値として帰ってきます。二つ目のパターンは、min, max, valueとしてそれぞれ最小値、最大値、値が辞書の形で返されるものです。
{'data': {'max': 0, 'min': 0, 'value': 0},
'sample': 425230027,
'samples': 425273227,
'startTime': '20190808T01:30:27'},3つ目のケースは、NFSの1秒間あたりのコマンドの数の集計のように、複数のデータポイントが含まれている例です。この場合、返ってくる値は辞書のリストになっています。keyに何の統計情報かを示す値が入ってきます。NFSv3のコマンドの統計であれば、readやgetattrなどになります。
{'data': {'data': [{'key': 'read', 'max': 471, 'min': 0, 'value': 0},
{'key': 'getattr',
'max': 57,
'min': 0,
'value': 0}],
'max': 537,
'min': 0,
'value': 0},データの加工方法について
データの加工の方法として、当初、元データを辞書として作成することにしました。これをデータフレームに変換することによって、目的のデータにします。必要に応じて、NaNになった部分を 0 に置き換えたり、不要な列を drop したりして、成果物を得るようにしました。
試行錯誤しましたが、json_normalize() 関数を使ってPandasのデータフレームに変換したあと、必要な操作をした方が柔軟性が高そうなので、そちらの方法を使いました。この方法では data.dataの列が辞書のリストになってしまいますが、関数を書いて通常の列になるように変換をしています。
決して良いコードではないと思いますが、記事の終わりにサンプルコードへのリンクを示します。実際のロジックは、そちらをご覧ください。
データ加工の際の注意点について
ここに書いてある内容は、データフレームを操作したときに出くわしたカラムの値(列名)についての内容です。辞書であれば、キーの値について同じような注意が必要です。
(a) データフレームを作成するときのカラムの名称に注意
Pandasのデータフレームは2次元です。あるインデックスの値の時に、あるカラムのに入る値がいくつになるかと言う形で保管されることになります。カラムの値が同じと言うことは同じデータと見なされます。同様に、辞書であれば、辞書のキーと値のペア(key-value pair) の形を作る必要があります。辞書はキーがユニークでなければいけません。
しかしながら、それぞれのデータセットでは、max, min, value などと言った一般的な英語が使われており、これらの値を素直に、キーの値として使ってしまうと、異なるデータセットの間で、重複した名前の項目ができてしまいます。これは、データフレームに使うカラムの名称でも同じです。
サンプルコードでは、data.dataの列の中身を見て、可能な限りユニークなカラム名を作っています。たとえば、NFSv3のコマンド毎の統計のデータでは、 read/getattr といったコマンドの名前(key: <値> の値の部分)と min/max/value といったキーの名前を合成して、例えば、read_min と言ったキーを作っています。
現実的には、NFSv3 と NFSv4 のコマンドの統計情報の様に、工夫しても重複することがあります。従って、サンプルコードでは、変換作業をおこなう際に、ユーザーが任意の値をカラム名の先頭に付加できるように関数を書いてあります。(expand_column() の関数に渡す prefixの値です。)
これによって、例えば、NFSv3 と NFSv4のデータのデータフレームを各々作成し、後に合成してもカラム名の衝突が起きなくできます。
(b) startTime のフォーマット
元データのstartTime のフォーマットは文字列です。サンプルコードの中では、Pandas の to_datetime() で datetime型に変換しています。Matplotlib などで startTime をインデックスとして表示したい場合、set_index()メソッドで設定してください。
(c) 不要な列の除外
Matplotlibなどで表示する際、sample, samples の列は不要です。事前に除外してください。
サンプルグラフ
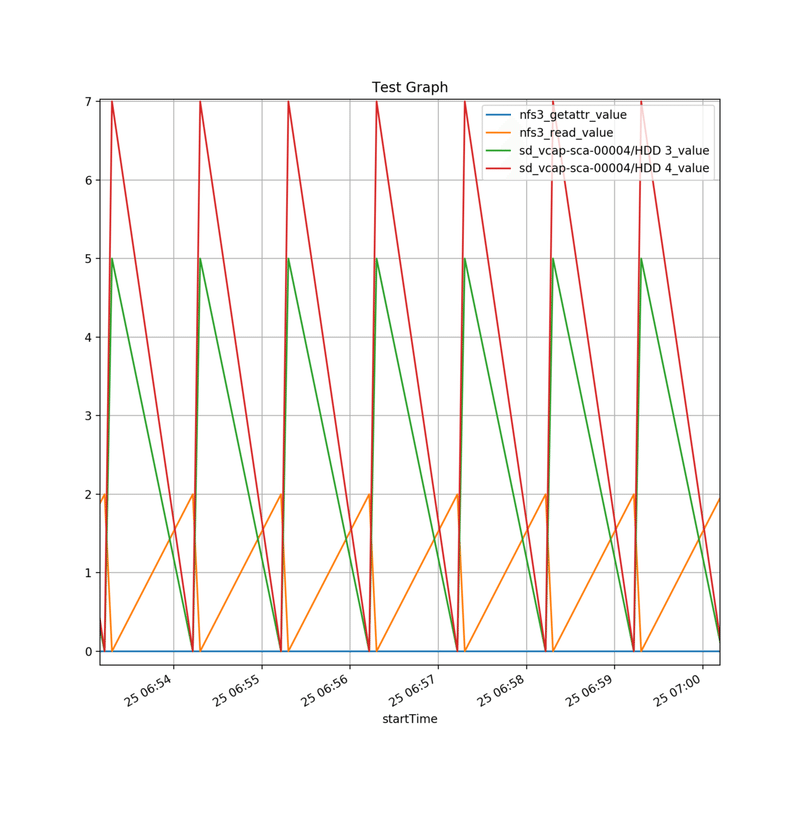
サンプルグラフは、NFSv3のGETATTR, READの毎秒あたりのコマンドの数と、HDD3と4の IOPSのデータをZFSSAから24時間分読みだし、合成しました。元データは簡単にI/Oをかけただけですので、あまりいいグラフでありませんが、合成できていることは分かって頂けると思います。
24時間分を秒単位で取ると、86,400のデータポイントができてしまい、表示したときにべた塗りのようになります。従って、以下のグラフは、表示したあとに6分間くらいのデータを拡大表示したものです。
サンプルコード
以上何かのご参考になれば幸いです。
この記事はここまでです。 最後まで読んでいただいてありがとうございます。 気に入っていただいたなら、スキを押していただいたり、 共有していただけるとうれしいです。 コメントや感想大歓迎です!