
壊れても耐える仕組み、RAIDについて

こんにちは、辻村です。ZFSのミラーリングについてお話ししましたが、RAIDについて整理をしていませんでした。今回は、RAIDについてお話しします。まず、RAIDの種類についてご紹介し、そして、ハードウェアRAIDとソフトウェアRAIDについて、それぞれの特徴をご紹介します。
RAIDとは?
RAIDは「レイド」と読みます。 Redundant Array of Independent Disks(冗長性を持たせた独立したディスク群)の略で、複数のディスク装置を組み合わせて使うことで、ディスクが故障しても簡単にはデータが壊れないようにする技術です。歴史的には、ディスク装置が高価なものだったときに発明され、元々は Redudant Array of Inexpensive Disks(冗長性を持たせた安価なディスク群)という意味だったそうです。"Independent" がなんかしっくりこなかったのは安価になってから略語の意味を変えたからだと思われます。
(参考文献の最後に挙げた文献には、IBMのメインフレームと呼ばれる大型コンピュータ向けのIBM 3380が高価なディスクの例に挙げられています。その代替案としてコストパフォーマンスが高いRAIDが紹介されています。)
RAIDレベル
RAIDにはRAIDレベルというものがあります。
RAID-0
「ストライピング」と呼ばれます。
故障に強くすると言うよりも性能を求める方式です。用意したディスクにデータを分割して同時に書くことでスピードを上げます。あるディスクに書かれたデータは他のディスクには書かれていないので、ディスク装置が1台壊れれば元データは読み出せなくなってしまいます。
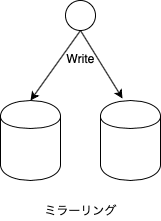
RAID-1
ミラーリングとも呼ばれます。
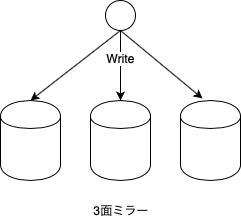
ミラーは鏡の意味ですが、その名前の通り、同じデータを2台に書くことでディスクが壊れても復旧できるようにします。あまり一般的ではないようですが、ストレージを扱う私のチームでは、データが書かれるそれぞれのグループを「面」(英語だと side)と呼んでいます。容量を増やすにはそれぞれの面に同じようにディスクを追加します。つまり、増設は最低でも2台単位ということです。理論的には、何台でもミラーリングは構成できますが、製品となっているのは3台までのようです。3台に同時書き込む場合は、3面ミラーと言っています。この場合、増設の単位は3台ずつになります。
RAID 0+1 、RAID 1+0
ミラーリングは性能が出にくく、速度が要求される場合は、ストライピングとミラーリングを組み合わせます。方法は二つあります。
・RAID 0+1 (ストライピングしてミラーリング)
・RAID 1+0 (ミラーリングしてからストライピング)
RAID 1+0 の方が故障に強いです。世に出回っているミッドレンジからハイエンドの製品では、ミラーリングといった場合、RAID 1+0 を指すようです。ZFSでは RAID 1+0を使います。手元の Oracle Solarisで確認したところ、3面ミラー以上も作れます。個人的には実際に運用されているシステムで3面以上を見たことはありません。私が見た例では、3面ミラーもバックアップ時にミラーの一面を取り外して使うという特殊な使い方をされていました。
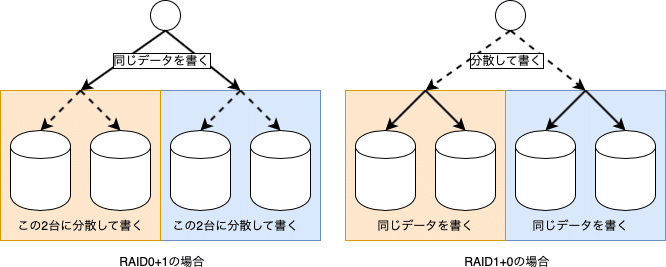
RAID0+1はオレンジと青のそれぞれから1台のディスクが壊れるとデータが読めなくなってしまいますが、RAID1+0はそれぞれから1台壊れた場合でもデータは正常に読み出すことができ、同じ色のグループのディスクが同時に2台同時に壊れない限りはデータを読むことができます。
RAID-5
RAID-5は容量を確保しつつ、1台のディスクが故障しても大丈夫なようにする仕組みです。
RAID-5の下敷きになった技術として、RAID-4があります。これは、それぞれのドライブに書き込まれたデータから、パリティと呼ばれるものを計算して、パリティ専用のディスクに書き込むことで、1台が壊れても復旧できるようにしたものです。RAID-5がRAID-4と異なるところは、パリティ専用ディスクに書く代わりに、書き込みのたびにパリティを保管するディスクを変えていくところです。
(下の図で、P1〜P4がパリティ)
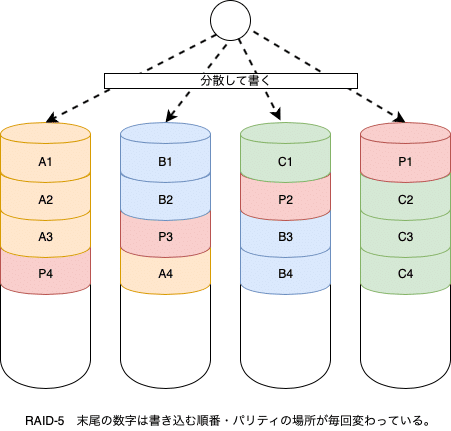
コンピュータの中ではすべてのデータは2進法で表現されています。つまり、0あるいは1しかありません。RAID-5のパリティの計算の仕方は、XOR(エクスオアとよみ、日本語では排他的論理和)と呼ばれるものです。これは、2つの値を比べて同じなら0、異なるなら1となる計算です。
例えば、1台目に1と書き込まれ、2台目に0と書き込まれた場合は、パリティは1になります。同様に、1台目に1,2台目に1と書き込まれた場合は、0になります。
ひとつ目のケース 1(1台目) 0(2台目) 1(パリティ)
ふたつ目のケース 1(1台目) 1(2台目) 0(パリティ)
ここでかりに2台目が壊れたとすると、以下の状態になります。
ひとつ目のケース 1(1台目) ?(2台目) 1(パリティ)
ふたつ目のケース 1(1台目) ?(2台目) 0(パリティ)
じっと見ていると気がつくかもしれませんが、実は、1台目とパリティをXORで計算することによって、2台目の値が計算できます。
ひとつ目のケース 1(1台目) 1(パリティ)= 0 (2台目に等しい)
ふたつ目のケース 1(1台目) 0(パリティ)= 1 (2台目に等しい)
3台あった場合は、以下のようになります。
1(1台目) 1(2台目) 0(3台目)0(パリティ)
同じく2台目が壊れたとすると、データを復旧する計算は以下のようになります。
1(1台目) 0(3台目) 0(パリティ)=1(2台目)
(2進数の計算に興味がある方は、2019/7/20 発売の結城浩先生の「ビットとバイナリー」がきっと役に立ちます。)
ディスクを交換したあとに一生懸命読み書きをしているのは、今あるデータを読みつつ、この計算をして元データを復旧しているのです。なお、RAID-5には最低3台のディスクが必要です。
ZFSのRAID-Z1はRAID-5相当であり、パリティ計算はこの方式です。残念ながら、RAID-5は停電やクラッシュ時にまれに検出が難しい誤りが入ってしまうという問題があります。ハイエンドのストレージ装置では、この問題を回避するために予期せぬ電源断に備えてバッテリーが搭載されています。ZFS は、書き込んだそれぞれのブロックに対してチェックサムをつけてこのようなエラーも検出できるようにすることで、問題を回避できるように設計されています。
RAID-6
RAID-6 はパリティを2台にして、同時に2台までの故障に対応できるようにしたものです。RAID-6が出てきた背景というのは、RAID-5に以下のような欠点があるからです。
(1) ディスク故障中の安全性が低い。
(2) ディスク装置の大容量化にともない、復旧中に2台目が壊れることがある。
(2) は某社の1TBディスクが出てきた頃に私も経験したことです。ある論文には名前こそ書かれていませんでしたが、2%程度は故障したとありました。同じ製品かどうかわかりませんが、同じ頃に取った私の個人的な集計でも、ある会社のハードディスクは 2%前後の故障率がありました。また、真偽は不明ですが、同じ頃、他社のお客様とおぼしき人が、「1TB以上のディスクにはRAID-5は推奨しない」というメールを受け取ったとしています。
RAID-6は2つのパリティを計算します。1つ目のパリティにはRAID-5で説明した XOR を使う方法を使います。2つ目のパリティには、対角線パリティと呼ばれるものやPQパリティと呼ばれるものを使います。PQパリティの計算には重み付けをしたガロア体というものを使います。(このあたりはまた別途書くかもしれません。)
RAID−Z2は RAID-6 相当です。また、ZFSではRAID−Z3と呼ばれるトリプルパリティの構成も組むことができます。この場合、理論的には3台同時に故障しても大丈夫です。
ハードウェアRAID
ハードウェアRAIDは二つに分けることができます。
(1) HBAにRAIDの機能があるもの。
(2) RAID装置にコントローラがあり、OS側からはLUの形で見えるもの。
HBAは Host Bus Adapter の略で、SCSIやSAS、SATAなどといった規格でディスク装置と接続するためのカードをさします。HBAにはRAID機能があるものがあり、この機能で複数の物理ディスクをRAIDに構成します。RAIDの構成情報はカードが覚えています。また、サーバーによっては、マザーボード上にHBAの役目をするチップを載せて、内蔵ディスクでRAIDを構成することができるものもあります。なお、ファイバーチャネルのHBAと言うものもありますが、(2) に使われます。この場合、HBAに RAIDの機能があってもカード側の機能は使いません。
(2) のRAID装置にコントローラがあるものは、装置に多数のディスクがつながっていて、コントローラを使って「ボリューム」を作成します。コントローラはOSにたいしてボリュームを論理ユニット(LU)の形で見せます。つまり、OSからはブロックデバイスに見えます。このタイプでは、通常の方法でRAIDレベルを知ることはできません。
RAID装置は、性能向上のために大量のメモリをキャッシュに持ったり、災害対策用にレプリケーションなどの機能を備えるものもあります。ボリュームのスナップショットを取ったりすることができる製品もあります。接続の冗長性をもたせるるため、複数のポートで接続できます。複数のポートを持つ製品はOSが直接認識する製品でない限り、パス制御用のソフトウェアを別途導入する必要があります。これらの追加の機能を持つの製品はエンタープライズ向けが多い印象です。
スナップショットの取り方や停電時のデータ保護の方法なども興味深い話題ですが、こちらはまたの機会に。
ソフトウェアRAID
ソフトウェアRAIDにはボリュームマネージャと呼ばれる製品と、ファイルシステムの一部としてディスク装置の管理ができてしまう製品があります。
前者には、Veritas Volume Manager や Solaris Volume Managerなどがあります。これらの製品で必要な LUを作成した上で、必要に応じて任意のファイルシステムをLU上に作成する形で使います。
後者にはbrtfsやZFSがあります。ZFSではディスク装置はJBODとして取り扱って、ディスク装置をプールとして考え、そこから必要に応じてファイルシステムを「切り出す」という形で管理をします。
ソフトウェアで構成されているので、上位層との連携がしやすいのも利点です。例えば、Oracle Solaris上の ZFS では NFSv4 で使用する際、上位層からI/Oのヒントをもらって自動的に I/Oのレコードサイズを調整するといったことをおこなっています。(特定の条件が満たされたときのみに利用されます。)
今回は RAIDについてまとめてみました。ご参考になれば幸いです。
より詳しく知りたい方に
ハードディスクやSSDが壊れたときにどの様に復旧するかをより詳しくお知りになりたい方は、以下の記事をご覧下さい。
・RAIDのデータ復旧の仕組み(1)
・RAIDのデータ復旧の仕組み(2)
また、ハードディスクの障害解析について知りたい方は、以下の記事がご参考になるかもしれません。
参考文献
・Wikipedia: RAID(英文)
・Illumos: usr/src/uts/common/fs/zfs/vdev_raid.c のコメント
・New RAID level recommendations from Dell (二次情報の可能性あり)
・A Tutorial on Reed-Solomon Coding for Fault Tolerance in RAID-like Systems
・A Case for Redundant Arrays of Inexpensive Disks (RAID)
この記事はここまでです。 最後まで読んでいただいてありがとうございます。 気に入っていただいたなら、スキを押していただいたり、 共有していただけるとうれしいです。 コメントや感想大歓迎です!