データ分析環境のためのaws S3設計

はじめに
データサイエンスという言葉がバズって数年が経ちました。
しかし、「データサイエンス...高度な機械学習に持ち込むには、そもそも良質なデータを必要十分に貯める必要がある」という当たり前の現実に直面した方は多いのではないでしょうか。
私もそのうちの一人です。
さて、Supership株式会社では、bigdataを利用しビジネスを行っております。
bigdataを利用した分析では、しばしばデータの入出力が複数のproject/systemになるため、そのデータをどのように保持し、アクセスさせるかは重要な課題です。
本noteでは、どのようにbucketとIAMを設計するとよいかの指針をまとめました。
TL;DR
・思想
・管理するものは減らしたい。bucketもIAMもたくさん作りたくはない。
・bucketを分割するのは、事故を防ぐための守りの行動である。
・それは、責任分界点の定義であったり
・それは、PIIのようなsensitiveなデータを分離したり
・書き込み
・ある領域に対して、複数のシステムが書き込むような設計は良くない。
・読み込み
・それぞれのbucketを読み込めるIAM policyを用意しておくと良い。
・prefix単位でのread権限を振るのはあまり良くない。
・ACLをIAMでやるのはバッドノウハウと思われる。
・ACLレイヤーを挟もう。
どれくらいbucketを作るべきか
どれくらいの単位でbucketを作るべきかは、この仕事に携わるようになってからずっと悩ましい問題でした。
結論を言ってしまえば、
「要件に合わせて必要十分に作ろう」
「作るメリットが作らないメリットを上回ったときに作ろう」
という身も蓋もない話になってしまうのですが、それでは何の役にも立たないので少し深堀りしてみたいと思います。
そもそも、bucketやIAMは、設計するにも作成するにも工数がかかります。
数が増えればその分の管理工数も増えます。
ビジネスにおいて工数(=人件費、即ちコスト)は当然圧縮したいので、「bucketやIAMは作らなくて済むならば作らないほうが良い」ということになります。
それでは、どういうケースのときにbucketを作るか。
そもそも、bucketを分割するということは、責任分界点を定義するための行為と言えると思います。
それは、例えば以下のようなケースです:
・あるbucketがどのproject/productに属しているのか、また、そのコスト管理やトラブルシュートの範囲等を明確化する
・IAM user/role設計と連動し、IAM設計を容易にする
・特にread権限は、bucketで切るほうがprefixで切るよりも都合がいいと思う
・また、データの取り扱い方が異なるものを区分する
・例:PII v.s. not PII, 自社データ v.s. 他社データ, etc.
このように、bucketを分割するのは、かなり守りの行動であると言えます。
余談ですが、最近、OOPに関する記事が2本くらい目に留まりました。
・オブジェクト指向歴25年のオブジェクト指向おじさんが語るオブジェクト指向設計の処方箋
・オブジェクト指向は単なる【整理術】だよ
OOPもbucket設計も、責任分界点の定義であったり整理術であったりというところは両者良く似ていると思います。
書き込みの流れは一方通行に
次に、書き込み権限の振り方を考えてみましょう。
考え方は非常にシンプルで、「あるarea(bucket or prefix)に書き込めるsystemは1つだけにする」ということです。
そのように設計することで、そのareaに対する責任が明確化され、その結果として事故が起きる可能性を下げることができ、また、事故が起きたときに迅速な対応が可能になります。
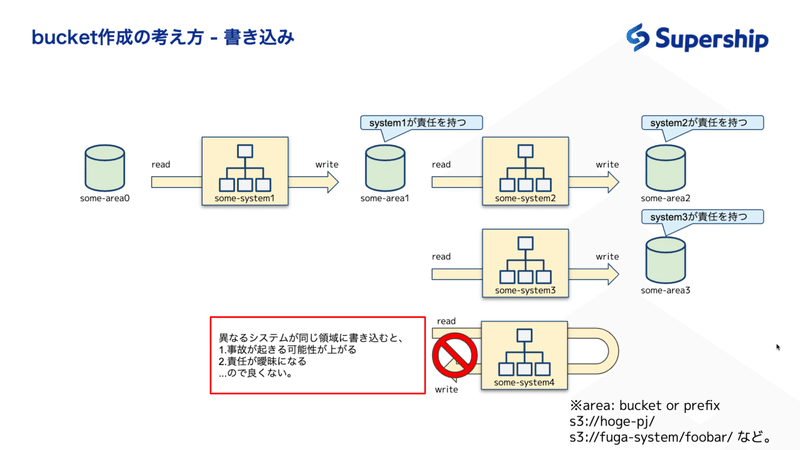
では、異なるsystemが同じ領域に書き込むような設計は何が問題なのでしょうか。
それは、以下のように、事故を誘発し、また事故の原因特定が困難になるというところにあると思います。
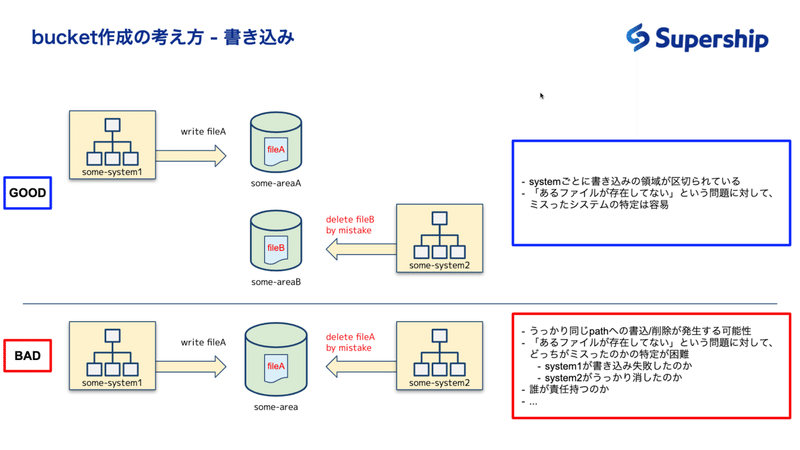
GOODの例では、
・some-areaAの書き込み権を持つのはsome-system1のみ
・some-areaBの書き込み権を持つのはsome-system2のみ
という前提の元、fileBをsome-system2が消してしまった例です。
このケースでは、some-areaBの書き込み権を持つのはsome-system2のみであるため、some-system2が失敗しているというのがすぐに分かります。
一方、BADの例では、
・some-areaの書き込み権を持つのはsome-system1とsome-system2
という前提の元、fileAをsome-system2が消してしまった例です。
このケースでは、some-areaの書き込み権を2つのsystemが持つため、どちらが失敗したのかの特定に時間がかかります。
このように、責任範囲の明確化を行うことで事故確率の低減や事故が起きたときの対応の迅速化ができます。
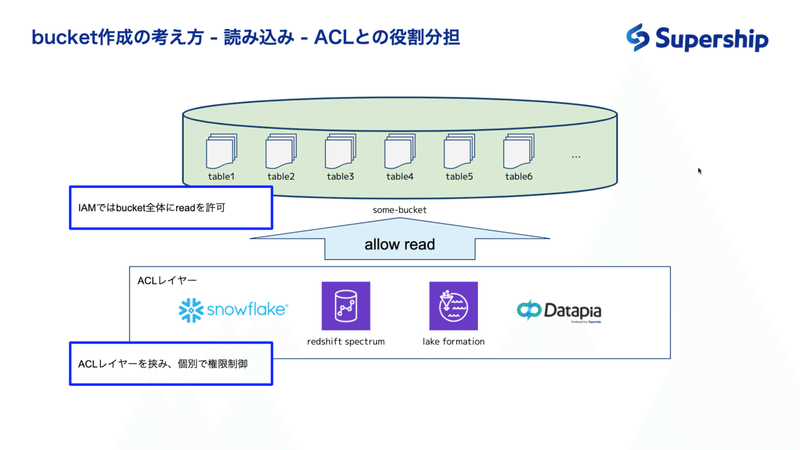
bucketに対してはまるっと読み込ませる
次に、読み込み権限の振り方を考えてみましょう。
読み込み権限をどう設計するかは自由ですが、IAMの定義量を少なく済ませるという観点から、prefixごとにread権限を制御することはあまり好ましいものではないと認識しています。
以下に、
・s3://some-database/some_prefix/user_*
・s3://some-database/some_prefix/service_attr_agg/*
・s3://some-database/some_prefix/accesslog_hourly/*
の3領域に対してのread権限を振るIAM policyを示します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3BucketOperationSomeDatabase",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::some-database",
"Condition": {
"StringLike": {
"s3:prefix": [
"some_prefix/user_*",
"some_prefix/service_attr_agg/*",
"some_prefix/service_attr_agg",
"some_prefix/accesslog_hourly/*",
"some_prefix/accesslog_hourly",
"some_prefix/",
""
]
}
}
},
{
"Sid": "S3ObjectOperationSomeDatabase",
"Effect": "Allow",
"Action": "s3:Get*",
"Resource": [
"arn:aws:s3:::some-database/some_prefix/user_*",
"arn:aws:s3:::some-database/some_prefix/service_attr_agg/*",
"arn:aws:s3:::some-database/some_prefix/accesslog_hourly/*"
]
}
]
}とても煩雑で嫌になりますね。
getだけであれば `S3ObjectOperationSomeDatabase` を書けば終わりますが、listを制御しようとすると `S3BucketOperationSomeDatabase` を大量に書かなくてはいけません。
また、IAM policyの文字数は制限されています。(AWS公式サイト::IAM ロールまたはユーザーのデフォルトの管理ポリシーまたは文字数サイズ制限を引き上げるにはどうすればよいですか?)
これらのことから、IAMを利用したACLはバッドノウハウと言え、ACLレイヤーを入れることが良いアプローチであると考えられます。
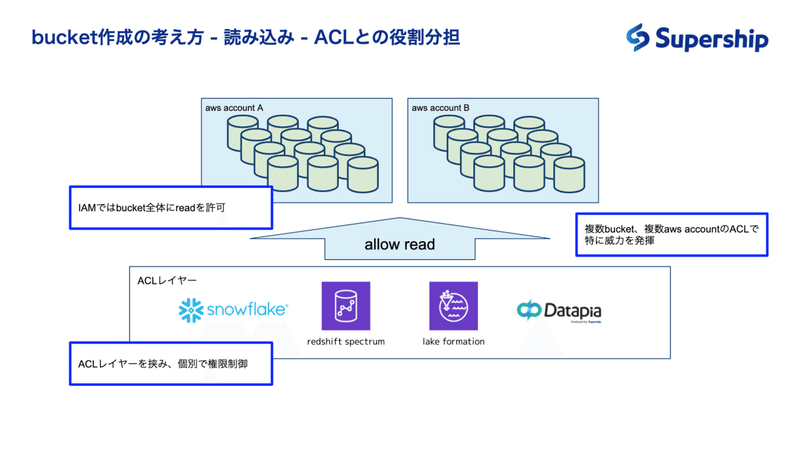
ACLレイヤーの存在は、特に複数bucket、複数AWSアカウントをまたいだACLを行いたいときにも威力を発揮すると考えられます。
bucket命名規則
最後に命名規則について述べます。
IAMにおいてbucket名に対してもワイルドカードが使えることから、大きい括りでの命名が良いと考えており、弊チームでは
`{環境名}-{product}[-{sub-product,複数可}][-{data種別}]` というルールを採用しています。
おわりに
bucket / IAM設計の指針を示すことは、Supershipに入ってからずっと課題でした。
これを試行錯誤を繰り返す中でこのような形でまとめられて本当に良かったなと思っています。
(メンバーには結構な迷惑をかけたので...。)
しかしながら、例えばクロスアカウントを行う場合どうするかといった問題や、より全体的なアカウント設計、ACLレイヤーとの組み合わせの指針を示すなどの課題は残っており、まだまだまとめるべきことはたくさんあるかなと思います。
私が2年前にデータエンジニアを志望しSupershipに入社したのは、前職でデータアナリストをやる中で、
「日本企業は、この先10年位は適切にデータを貯め、使える状態にする必要がある」
という見解からでした。
このノートが、その一助になれば幸いです。
皆様のサポートが励みになりますのでどうぞよろしくお願いします...!