
FX機械学習入門(6/6):特徴量の追加と整理、有益な特徴量のランキング

特徴量の追加(200個追加)
このコードは、与えられたデータセットから新しい特徴量(フィーチャ)を自動的に生成する関数generate_new_featuresの実装です。フィーチャエンジニアリングは、機械学習モデルのトレーニングに使用するために、生データをより有用な特徴量のセットに変換するプロセスです。この関数は自動フィーチャエンジニアリングのアプローチを採用しており、指定された数の新しい特徴量をランダムな演算によって生成します。以下に、日本語でのコメントを追加したコードを示します。
import random
import pandas as pd
def generate_new_features(data, num_features=200, random_seed=1):
random.seed(random_seed) # 乱数シードを設定
new_features = {} # 新しい特徴量を保持する辞書
# 指定された数の新しい特徴量を生成
for _ in range(num_features):
feature_name = f'feature_{len(new_features)}' # 新しい特徴量の名前
# データからランダムに2列選択
col1_idx, col2_idx = random.sample(range(len(data.columns)), 2)
col1, col2 = data.columns[col1_idx], data.columns[col2_idx]
# 実行する演算をランダムに選択
operation = random.choice(['add', 'subtract', 'multiply', 'divide', 'shift', 'rolling_mean', 'rolling_std', 'rolling_max', 'rolling_min', 'rolling_sum'])
# 選択した演算に基づいて新しい特徴量を計算
if operation == 'add':
new_features[feature_name] = data[col1] + data[col2]
elif operation == 'subtract':
new_features[feature_name] = data[col1] - data[col2]
elif operation == 'multiply':
new_features[feature_name] = data[col1] * data[col2]
elif operation == 'divide':
new_features[feature_name] = data[col1] / data[col2]
elif operation == 'shift':
shift = random.randint(1, 10)
new_features[feature_name] = data[col1].shift(shift)
elif operation == 'rolling_mean':
window = random.randint(2, 20)
new_features[feature_name] = data[col1].rolling(window).mean()
elif operation == 'rolling_std':
window = random.randint(2, 20)
new_features[feature_name] = data[col1].rolling(window).std()
elif operation == 'rolling_max':
window = random.randint(2, 20)
new_features[feature_name] = data[col1].rolling(window).max()
elif operation == 'rolling_min':
window = random.randint(2, 20)
new_features[feature_name] = data[col1].rolling(window).min()
elif operation == 'rolling_sum':
window = random.randint(2, 20)
new_features[feature_name] = data[col1].rolling(window).sum()
# 新しい特徴量を元のデータに結合
new_data = pd.concat([data, pd.DataFrame(new_features)], axis=1)
# 生成された新しい特徴量の確認
print("\n生成された特徴量:")
print(new_data[list(new_features.keys())].tail(100))
return new_data
# balanced_dataを使用して新しい特徴量を生成
new_data_with_features = generate_new_features(balanced_data, num_features=200, random_seed=42)
# 新しいデータセットを確認
print(new_data_with_features.head())
この関数呼び出しでは、元のデータセットbalanced_dataに200個の新しい特徴量を加えるよう指定しています。乱数シードは42に設定されており、これにより結果の再現性が保証されます(つまり、同じシード値を使用すれば、同じランダム選択が行われます)。
特徴量の整理、クラスタリング
from sklearn.mixture import GaussianMixture
import numpy as np
def cluster_features_by_gmm(data, n_components=4):
# 'label'と'labels'列を除外して特徴量のみを選択
X = data.drop(['label', 'labels'], axis=1)
# 無限値をNaNに置換し、NaNを中央値で埋める
X = X.replace([np.inf, -np.inf], np.nan)
X = X.fillna(X.median())
# ガウス混合モデルのインスタンスを生成
gmm = GaussianMixture(n_components=n_components, random_state=1)
# データにフィットさせる
gmm.fit(X)
# 各データポイントのクラスタ番号を予測し、新しい列として追加
data['cluster'] = gmm.predict(X)
# クラスタリング結果の確認
print("\n特徴量クラスタ:")
print(data[['cluster']].tail(100))
# クラスタリングされたデータセットを返す
return data
# new_data_with_featuresは、generate_new_features関数で生成されたデータセット
clustered_data = cluster_features_by_gmm(new_data_with_features, n_components=4)
# 新しいデータセットを確認
print(clustered_data.head())
このコードは、new_data_with_featuresデータセットの特徴量を4つのクラスタに分けるためにGMMを使用します。クラスタリングを行うことで、データ内の隠れたパターンや構造を発見し、類似の特徴量をグループ化することができます。この情報は、データのさらなる分析や、特定のクラスタに基づくモデルのトレーニングに役立つかもしれません。最終的に、各データポイントに対してクラスタ番号が割り当てられ、この新しいcluster列がデータセットに追加されます。
特徴量の有益さを比較
import numpy as np
from sklearn.feature_selection import RFECV
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
def feature_engineering(data, n_features_to_select=10):
data.replace([np.inf, -np.inf], np.nan, inplace=True)
data.dropna(inplace=True)
# 'label'列は特徴量ではないので削除
X = data.drop(['label', 'labels'], axis=1)
y = data['labels']
# RandomForestClassifierモデルの作成
clf = RandomForestClassifier(n_estimators=100, random_state=1)
# Use RFECV to select n_features_to_select best features
rfecv = RFECV(estimator=clf, step=1, cv=5, scoring='accuracy', n_jobs=-1, verbose=1,
min_features_to_select=n_features_to_select)
rfecv.fit(X, y)
# 最良の特徴量、'label'列、'labels'列を含むDataFrameを返す
selected_features = X.columns[rfecv.get_support(indices=True)]
selected_data = data[selected_features.tolist() + ['label', 'labels']] # selected_featuresをリストに変換
# 最良の特徴量のテーブルを出力
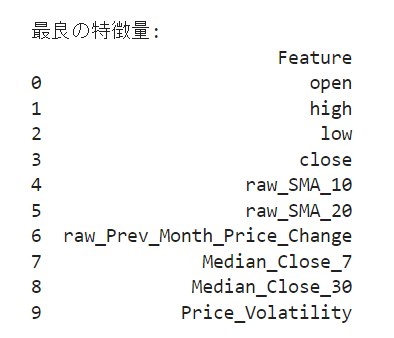
print("\n最良の特徴量:")
print(pd.DataFrame({'Feature': selected_features}))
return selected_data
labeled_data_engineered = feature_engineering(balanced_data, n_features_to_select=10)
Gaussian Mixture Model (GMM) を使用した特徴量のクラスタリング:
何をしているか: GMMは、データが複数の正規分布の混合で生成されると仮定し、各データポイントがそれぞれの分布からどれくらい異なるかを評価して、クラスタリングを行います。
なぜしているか: データを複数のクラスタにグループ化することで、データセット内の潜在的な構造やパターンを理解しやすくします。これは、異なるクラスタ内のデータが互いに異なる傾向や特性を持つ場合に特に役立ちます。GMMはその柔軟性から、データの複雑な構造やぼやけた境界を持つ場合に有用です。
RFECVを使用した最良の特徴量の選択:
何をしているか: RFECV(Recursive Feature Elimination with Cross-Validation)は、モデルの性能を最大化するために最も有益な特徴量を選択します。具体的には、モデルの性能を評価しながら、1つずつ特徴量を削除していき、性能が最大となる特徴量のサブセットを選択します。
なぜしているか: モデルの性能を最大化するためには、不要な特徴量を削除し、有益な特徴量のみを残すことが重要です。これにより、モデルの複雑さが減少し、過学習のリスクが低減します。また、選択された特徴量がより解釈可能であり、モデルの予測力が向上します。
このプロセスを通じて、データをクラスタにグループ化し、最も有益な特徴量を選択することで、モデルの性能と解釈性を向上させることができます。
最良の特徴量がデタ!!
所感:
面白いと思って見切り発車したけど、これって使えるの?正解データをランダムにしてるから毎回ランダムになるんで、つまりあるときはデイトレ、ある時はスイングの形になると思われる。
なんか違う感じもしますよね。
最近機械学習、AIが流行ってきてて、でも実際につかえるのかは自分的にちょっと疑問(RichmanBTC式とかも・・・)
この記事が気に入ったらサポートをしてみませんか?