
⚠️執筆途中⚠️
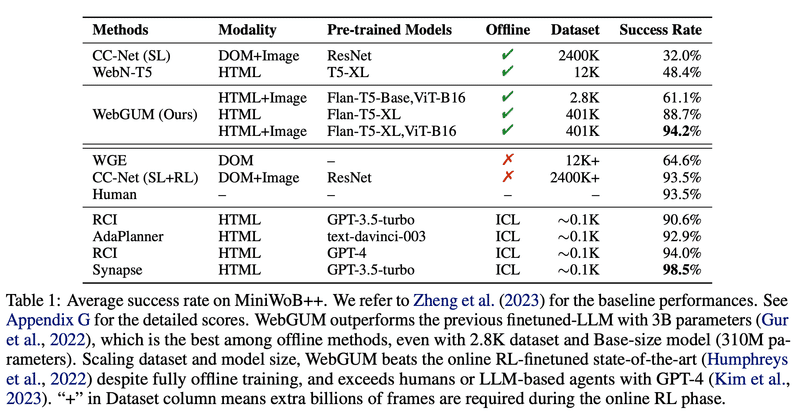
東京大学とDeepMindが共著した, Web Automationの記事がありましたので, 共有します。MiniWoBというデータセットで45.8%以上もSoTAモデルを上回ったというとてつもないモデルです。(existing-SoTA, 人間, GPT-4 based agentをoutperform)
一旦ChatGPTに投げる。
この文書は、視覚言語の基盤モデルを統合することにより自動ウェブナビゲーションを改善するための包括的な研究であり、WebGUMという多モーダルエージェントの開発に焦点を当てています。このエージェントは、クリックやタイピングなどのウェブナビゲーションタスクを実行するために、ウェブページのスクリーンショットとHTMLページの両方を利用し、大規模なデモンストレーションのコーパスから時間的および局所的知覚に焦点を当てた命令微調整言語モデルとビジョンエンコーダーの共同微調整によって訓練されます。
主な内容には以下のものが含まれます:
導入と動機:研究の動機を始めに説明し、大規模な探索的インタラクションへの依存や、一般化を妨げるドメイン固有のモデル設計など、自動ウェブナビゲーションが直面する課題を強調しています。
WebGUMアーキテクチャ:HTMLとスクリーンショットの両方で訓練された改善されたウェブナビゲーションパフォーマンスのためのWebGUMエージェントを記述し、時間的および局所的知覚に焦点を当てた多モーダルトランスフォーマーモデルや、命令微調整された大言語モデルの重要性について詳述しています。
データ収集とトレーニング:言語モデルエージェントを使用した大規模データ収集のアプローチと、言語モデルとビジョンエンコーダーの共同微調整プロセスについて説明しています。
結果と評価:MiniWoBやWebShopなどのベンチマークでのウェブナビゲーションタスクにおける顕著な改善を報告し、エージェントの強化されたHTML理解、多モーダル知覚、および多段階推論能力に成功を帰しています。また、WebGUMの実世界でのアクション予測タスクへの転送可能性についても言及しています。
制限と今後の研究についての議論:WebGUMは有望な結果を示していますが、インターネットスケールのデータ収集や、実世界のウェブナビゲーションに対する一般的なモデルのさらなる探求など、今後の研究のための潜在的な領域を含むその限界と潜在的な領域について議論しています。
広範な影響と結論:研究の広範な影響について反映し、自動ウェブナビゲーションのためのより能力の高いスケーラブルなモデルを作成するためのWebGUMアプローチの有効性を再確認することで結論づけています。
この研究は、命令微調整された言語モデル、ビジョンエンコーダー、および大規模データ収集の相乗効果を活用することにより、自動ウェブナビゲーションのためのより能力の高いスケーラブルなモデルを作成する方向への一歩を表しています。
当論文で紹介されているWebGUMは, スクリーンショットとHTMLと, click/typeというアウトプットアクションを観察し,


githubは以下
https://github.com/google-research/google-research/tree/master/compositional_rl/compwob
この記事が気に入ったらサポートをしてみませんか?