
AIは言語の理解にどこまで近づいたか?

2016年にGoogle translateがリカレントニューラルネットワークを活用し、翻訳の精度を劇的に向上させました。その翻訳の流暢さからAIの力により今にもコンピューターが言語を理解できそうだ!AIすごい!と世の期待が膨らみましたが、その後どうなったのでしょう?ここ数年の動向を追ってみました。
Google Translateの衝撃
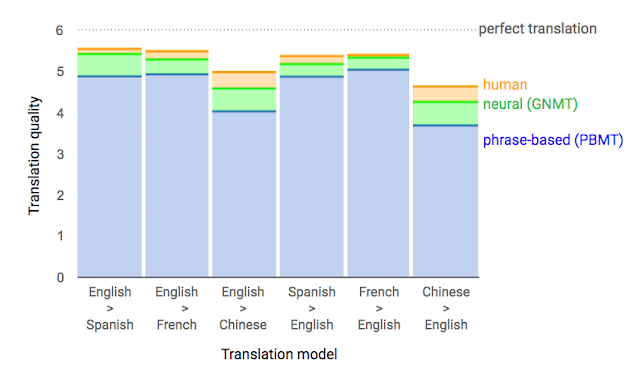
16年の翻訳精度向上の主役はAI。単語ごとのフレーズベースではなく、ニューラルネットワークを使うことで文章の文脈(文の構造)を考慮して翻訳できるようになりました。英語→フランス語を見ると、人間の翻訳精度にほぼ近づいています。
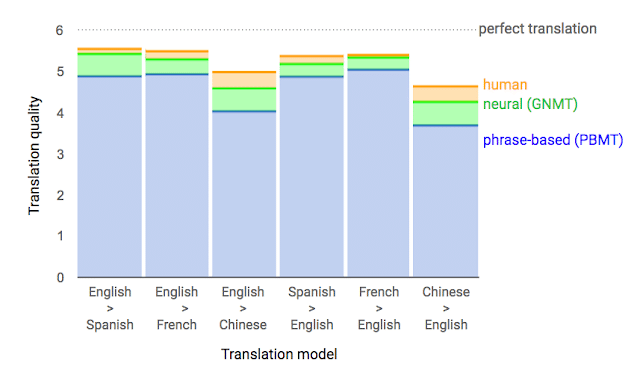

ただこの方法にも、課題はまだあるようです。
・単語を落としてしまう
・固有名詞やまれな用語を誤って翻訳してしまう
・文章単位でしか文脈を把握できない。
など人間の翻訳者であれば、決して起こさない誤りを犯すこともあります。
さて、言葉の科学、言語学的に見ると、他にどういう課題があるのでしょう?
言語学から見た現在地
この本は言語学、自然言語処理の研究者によるもの。言語学の観点からみたAIの現状と限界について解説しています。「言語処理なんてディープラーニングを使えば簡単なんでしょ?」という世の風潮に対するアンサー本にもなっています。「言葉がわかる機械」を作ろうとするイタチたちの物語と、その技術解説からなる構成になっており、読みやすくおススメです。また科学者らしい真摯なアプローチで、雰囲気や将来の展望はなく、丁寧にエビデンスベースで1つ1つ課題を指摘されています。
「AIは言葉を理解できたのか?」結論から言えば「壁はまだまだ高い」ようです。「言葉がわかる機械」を作るために、以下の7つの要素をあげています。
①音声や文字の列を単語の列に置き換えられること
②文の内容の真偽が問えること
③言葉と外の世界を結びつけられること
④文と文との意味の違いが分かること
⑤言葉を使った推論ができること
⑥単語の意味についての知識を持っていること
⑦相手の意図が推測できること
(働きたくないイタチと言葉がわかるロボット 人工知能から考える「人と言葉」)
また、これらの問題は複合的であることの難しさも指摘しています。
上の七つはそれぞれ独立したものではなく、複雑に影響し合っています。たとえば、②で述べられている「文の内容の真偽」が予想できるには、③の「外の世界との関連付け」と⑤の「言葉を使った推論」ができる必要があることを述べました。また、⑤の「推論」は、④の「文と文との意味の違いの認識」のためにも必要でした。さらに、⑤の「推論」には⑥の「単語の意味の知識」が大いに関わっており、⑦の「相手の意図の推測」には、①から⑥までの力以外にも、常識を使ったり状況を把握したりする力が関わっています。
テクノロジーの現在地
言語への理解への壁はまだまだ高いと言っても、日々、数々の進化が劇的な速度で起きているではないか、と思う方もいらっしゃると思います。この領域の最先端を行くGoogleの事例をもとにテクノロジーの現在地を見てみましょう。
Knowledge Graf
Googleが検索エンジンで用いているのがKnowledge Graf。2012年に検索エンジンのアルゴリズムを大きく変更しました。Knowledge Grafは、ある単語に関連する情報をつなげて構造化する手法です。また、同年に「情報エンジンから知識エンジンへ」というコンセプトを掲げています。検索ワードが実世界で何を表しているかを知ることで、情報から知識へのアップデートを目指すものです。
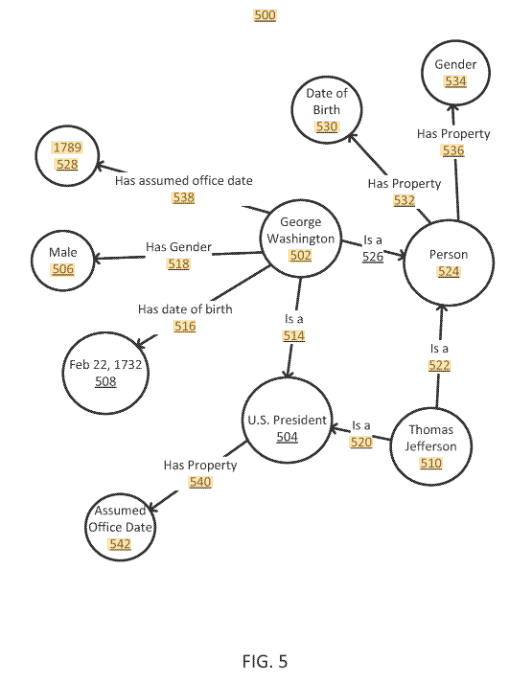
2013年に提出されたGoogleの特許より
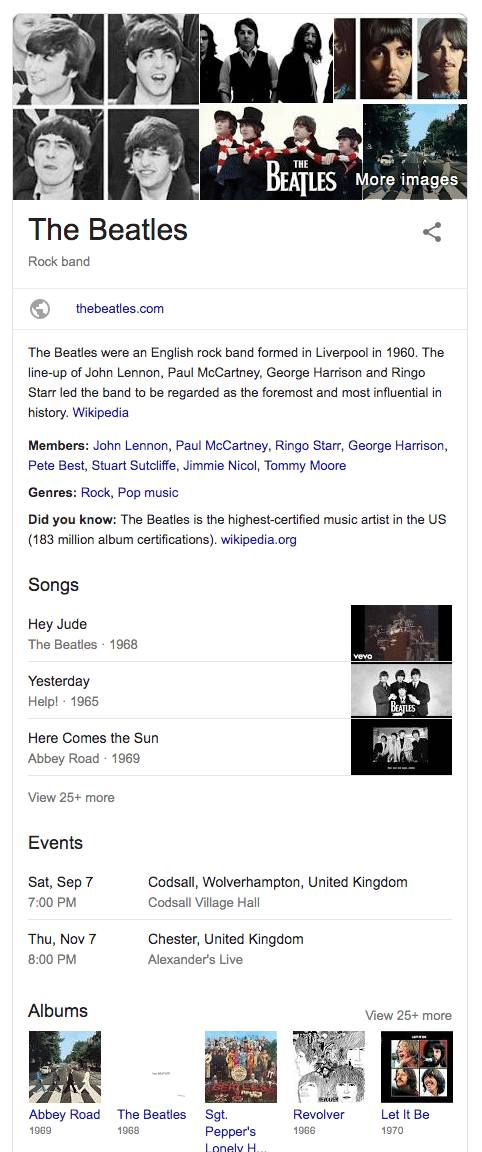
KnowledgeGrafは2012年時点で、5.7億件以上のオブジェクトと、35億のファクト。これらの180億件以上の関係、16年には700億以上のファクトを保持しているとアナウンスしています。これらはすでにGoogleの検索結果に反映されています。検索すると右側に出てくるパネルがこの技術によるもの。例えば、ビートルズで検索すると、写真、メンバー、ジャンル、代表曲など周辺の情報が表示されます。
Knowledge Graf & DeepLearning
次に紹介するのは、Youtubeに投稿された動画がどういう内容なのか?動画に適切な主題を与える研究です。この研究では言語解析、画像解析、KnowledgeGraf、DeepLearningと、この周辺の技術をフル活用したアプローチをしています。

画像認識のConvolutional Neural Networkを用い動画内に写っているものを認識します。

現在の画像認識は画像内からバスケットボール、車椅子が写っていると認識でき、実用レベルまで精度が上がっています。

次に、タイトルや解説文から、KnowledgeGrafを用いて重要そうな言葉のみを抽出しています。

さらに、ディープラーニングで文脈から多義語の意味を特定させています。Washington and NewYorkという文章であれば、Washingtonは大統領ではなく都市。New YorkもNewとYorkではなく、都市のNewYorkといった具合にです。

検索ワードからキーワード周辺の関連ワードを拾います。
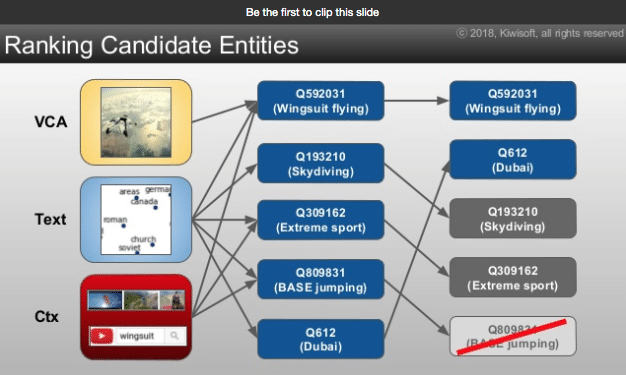
最後にこれらのインプットをもとに適切な主題を決定しています。「ドバイでウイングスーツで飛んでいる動画」という正しい認識にたどり着いています。
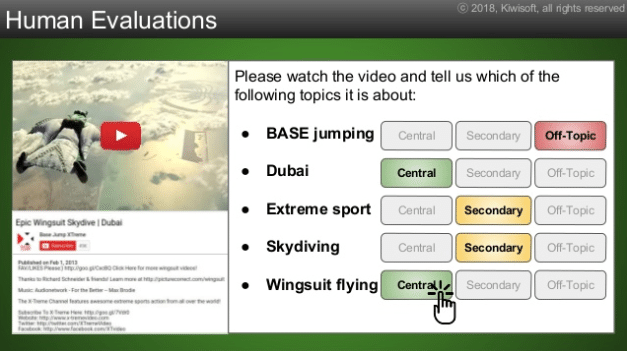
さらに人力で主題、副題、外れているものを選択し精度を上げています。
このプレゼンテーションで、解析対象となっているのがこの動画です。この動画をご覧になってAIすごい!と感じるか、まだまだだなと感じるかいかがでしょう?
言語学的に見たテクノロジーの現在地
これらのGoogleのアプローチは、言語学的に見るとどういう課題を解決していってるのでしょう?
①音声や文字の列を単語の列に置き換えられること
②文の内容の真偽が問えること
③言葉と外の世界を結びつけられること
④文と文との意味の違いが分かること
⑤言葉を使った推論ができること
⑥単語の意味についての知識を持っていること
⑦相手の意図が推測できること
(働きたくないイタチと言葉がわかるロボット 人工知能から考える「人と言葉」)
①音声や文字の列を単語の列に置き換えられること
これはすでに実用レベルに達しています。
③言葉と外の世界を結びつけられること
⑥単語の意味についての知識を持っていること
これらも良い線を行ってそうです。ご紹介した2つは、主にこの課題へのアプローチです。これらがどういう課題なのか、もう少し詳細に見てみましょう。
機械が利用する文脈は「周囲の数単語の字面」ですが、私たちはそれらの単語が外の世界で何と対応しているかという情報も使うことができます。また、それだけでなく、目の前の状況や、過去の体験の記憶も利用します。つまり機械にとっての「文脈」は「言語の世界」の中だけで完結しており、対象となる単語、また周辺に現れる単語が「言語の外の世界」で何に相当するかは考慮されません。(働きたくないイタチと言葉がわかるロボット 人工知能から考える「人と言葉」)
「言語の外の世界」へのアプローチは多様なリソースのもと順調に進化していきそうです。しかし、目の前の状況、過去の体験まで考えると、まだまだ範囲は限定的です。さらに、①③⑥以外のより抽象度の高い課題はさらに難易度が高いでしょう。つまり、言語への理解の大いなる一歩が始まったばかりのようです。
ただし、動画に主題をつける例のように、AIは人間とはまったく違った方法で物事を認知、理解をすることもポイントです。洗濯機が人より早く大量に洗濯できるように、特定の目的にフォーカスすれば、人間以上のパフォーマンスを出す可能性も見えてきます。例えば「⑦相手の意図が推測できること」は、AIに限った問題ではなく人間同士でも意図が伝わらずコミュニケーションのすれ違いが起こります。もしWEBカム動画から相手の表情や音の抑揚などの解析ができれば、人間が読み取れない機微や意図を感じとることができるかもしれません。
人間から見た現在地
最後に2019年現在、人間のAIの使い方を見てみましょう。少し前にTwitterでこんな投稿がバズっていました。
はい、まさに。私は英語を習得するよりも先に、英語に適切に翻訳できる日本語の文体を習得することに成功しました。この技術を得たことは私にとって喜びであり、財産でもあります。なお、この文章も同様です。あなたがこの文章をGoogleで翻訳すれば、あなたは画面上に整った英語の文章を発見する。 https://t.co/0e4Qn5m337
— 瀧波ユカリ🍖Ekodachan author (@takinamiyukari) March 12, 2019
続々と「私も同じような手法をとっていた」と声をあげる人があらわれたのも印象的でした。その翻訳を見て「プロの視点でも全く問題ないレベル!」と言う翻訳家の方すらいました。日本語のGoogleTranslateの精度は中国語→英語レベル。完全には程遠く人間にはまだまだ敵わないレベルです。それでもプロからみて問題ないクオリティを出す「使い方」もできるのです。人間の柔軟性を感じさせる出来事でした。
AIが言葉を完全に理解するのはまだ遠そうですが、不完全なAIを使って人間が新しい言葉の使い方、より多様な言葉の使い方を見いだすかもしれません。LINEを使いスタンプでコミュニケーションをしているなんて10年前には想像すらできなかったのですから。
AIと私達に身近な言語の関係を考えることは、人とAIの関係を考えること、ひいては、人の新たな可能性を見つめなおすことに他なりません。また数年後に人とAIの現在地をチェックしみたいと思います。
Appendix
その他、興味深かった記事や論文です。
自然言語処理、機械学習
自然言語処理の課題。機械学習方面から自然言語処理に入るには、この講義シリーズはオススメ。
[自然言語処理 06 自然言語処理の未来 - YouTube]
人間は「スズメは飛ぶことができる」と「ハトは飛ぶことができる」という知識から、今まで見たことがない動物でも「羽を持つ動物は飛ぶことができる」と推測できる。このような知識構築の研究
[Google AI Blog: Wide & Deep Learning: Better Together with TensorFlow]
大量のトレーニングデータの確保は機械学習の大きな課題。少量のデータで大量の言語モデルの結果を上回った研究。Better networks to trainからBetter ways to train networksへの発想の転換。音声を波形の画像データとして使用しているのが特徴。
[Google AI Blog: SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition]
Spotifyのレコメンデーションアルゴリズム。協調フィルタリングベースから、ニューラルネットワークベースに変更し精度改善。こちらも音声波形の画像データを入力に使用。ビブラートを拾うフィルター、バスドラムを拾うフィルターなど、AIの「音楽の理解の仕方」が興味深い。
[Recommending music on Spotify with deep learning – Sander Dieleman]
機械学習は、その仕組み上「100%の認識を実現することは不可能」。この前提をもとに、完全ではなく個別最適化を目指した研究。また、人間とコンピューターの接点であるUIに注力しているのも興味深い。つまり、人間の機能の最大化でもある。
[歩み寄りインタフェースの提案 | 宮下研究室 論文データベース]
GANを使った言語処理、機械翻訳のサマリー。ニューラルネットワークを使った翻訳のPros/Consについても触れられている。流暢に訳せる反面、致命的な問題もまだ残っている。
[言語処理における GAN の展開]
差別的な投稿の対応に頭を悩ませているTwitter。機械学習などの自動化により38%の不適切な投稿の抽出に成功。最終的には人力のチェックをしている。機会学習で全自動化はできないが、人力との組み合わせで「課題は解決できる」ことを示唆している。Done is better than perfectな事例。
[Twitter says it now proactively surfaces 38% of abusive content | VentureBeat]
Knowledge Graf
Knowledge Graphを使ったGoogleの検索戦略。検索だけでなくGoogleの言語への理解への姿勢と哲学がよく分かる。2012年と少し古いが基本方針は今も変わっていない。
[Googleの新しい検索技術 Knowledge Graphについて]
ナレッジグラフの構築で重要なEntity。Googleは約6400もの特許を取得しており力の入れ具合が伺える。Gooleはオープンな会社のように見えるが、コアコンピタンスである検索エンジンの根幹ついては実はクローズド。特許を眺めていると戦略の重心がなんとなく見えてくる。
[Google Patents]
KnowledgeGrafの一部はAPIとして提供されている。Entityの定義を見ると
どう構造化しているかが垣間見える。
[Google Knowledge Graph Search API | Knowledge Graph Search API | Google Developers]
Google、Microsoft、Yahooなどにより設立されたコミュニティ。具体的なEntity定義の仕様が見れる。この団体は、Webサイトのより詳ししい情報を検索エンジンに伝えるための共通仕様を作ることを目的としている。
[https://schema.org/Person]
CoverPhoto by Asya Lenda on Unsplash
この記事が気に入ったらサポートをしてみませんか?