バイナリダンプで学ぶPostgreSQL

この記事はPostgreSQL Advent Calendar 2019の6日目の記事です。
「PostgreSQLってどういう風にデータを保存しているんだろう?」ってよく思いますよね。たとえばr1というテーブルを作った場合、そのファイルがどこにできるかは、pg_database.oidとpg_class.relfilenameをみることでわかります。
user=> SELECT * FROM r1;
i | t
---+-----
1 | One
2 | Two
(2 rows)
user=> show data_directory;
data_directory
---------------------------
/Users/user/pgsql/11/data
(1 row)
user=> SELECT oid, datname FROM pg_database WHERE datname = 'user';
oid | datname
-------+---------
16384 | user
(1 row)
user=> SELECT relname, relfilenode FROM pg_class WHERE relname = 'r1';
relname | relfilenode
---------+-------------
r1 | 16434
(1 row)
ファイルは「database_directory + "/base/" + pg_database.oid + "/" + pg_class.relfilenode」にあります。
ページレイアウト
では実際にファイルの中身を見てみましょう。
$ cd /Users/user/pgsql/11/data/base/16384
$ hexdump -C 16434
00000000 00 00 00 00 68 37 30 02 00 00 00 00 20 00 c0 1f |....h70..... ...|
00000010 00 20 04 20 00 00 00 00 e0 9f 40 00 c0 9f 40 00 |. . ......@...@.|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001fc0 59 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |Y...............|
00001fd0 02 00 02 00 02 09 18 00 02 00 00 00 09 54 77 6f |.............Two|
00001fe0 59 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |Y...............|
00001ff0 01 00 02 00 02 09 18 00 01 00 00 00 09 4f 6e 65 |.............One|
00002000
8kbyte(0 〜 0x00001fff)のファイルの最後のあたりにレコードが格納されていそうにみえますね。
新たにレコードを追加してみましょう。テーブルにINSERTなどを行ってもすぐにはファイルに反映されませんが、CHECKPOINTコマンドを実行するとファイルに反映されます。
--
user=> INSERT INTO r1 VALUES(3, 'Three');
INSERT 0 1
user=> CHECKPOINT;
CHECKPOINT$ hexdump -C 16434
00000000 00 00 00 00 50 3a 30 02 00 00 00 00 24 00 98 1f |....P:0.....$...|
00000010 00 20 04 20 00 00 00 00 e0 9f 40 00 c0 9f 40 00 |. . ......@...@.|
00000020 98 9f 44 00 00 00 00 00 00 00 00 00 00 00 00 00 |..D.............|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001f90 00 00 00 00 00 00 00 00 5a 02 00 00 00 00 00 00 |........Z.......|
00001fa0 00 00 00 00 00 00 00 00 03 00 02 00 02 08 18 00 |................|
00001fb0 03 00 00 00 0d 54 68 72 65 65 00 00 00 00 00 00 |.....Three......|
00001fc0 59 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |Y...............|
00001fd0 02 00 02 00 02 09 18 00 02 00 00 00 09 54 77 6f |.............Two|
00001fe0 59 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |Y...............|
00001ff0 01 00 02 00 02 09 18 00 01 00 00 00 09 4f 6e 65 |.............One|
00002000
hexdumpの結果で`*`となっている行は、中身が空なので表示が省略されている部分です。つまりこのファイルは8kbのページの中で、上のちょっとと下のちょっとだけを使っていることになります。これがPostgreSQLの内部構造を勉強したことがある人は一度は見たことがあるページレイアウトの絵です。
このページレイアウトの詳細については以前から公式のドキュメントに説明がありましたが、最近は図も入るようになったようです。
https://www.postgresql.org/docs/12/storage-page-layout.html#STORAGE-PAGE-LAYOUT-FIGURE
可変長レコードの保存方法
ところでなぜこのような構造になっているのでしょう?
固定長のレコードであれば、そのレコード長 * n バイト目にアクセスすればいきなりレコードにアクセスすることができます。
しかしPostgreSQLのレコードはすべて可変長です。可変長のレコードを保存するためには、それぞれのレコードの長さを知るために、たとえばレコードの終端をNULLで区切るとか、あるいは各レコードの先頭に長さを格納するいわゆるPascal文字列のような方法があります。
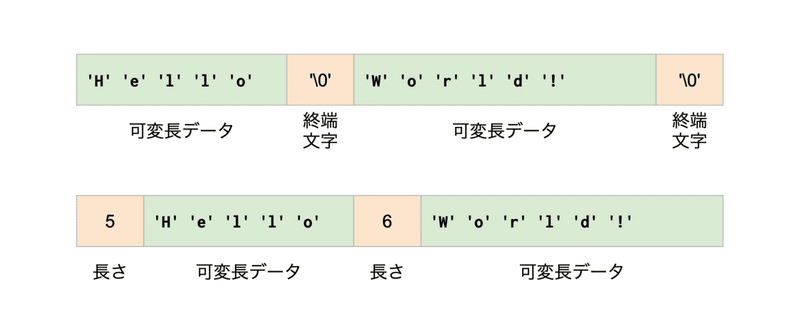
(説明のために文字列にしましたが、実際に格納されている可変長データはレコード全体です)
もしこのような方法を採用したとすると、1000レコード目を取り出したい時は1レコード目から1000回順に辿る必要があるため、固定長の任意のレコードにアクセスするときと比べて遅くなってしまいます。
実際にはPostgreSQLは、1つのレコードを保存したとき、
1. ページの下側にその可変長データそのものを保存し、
2. そのデータをページ内のどこに保存したかをページの上側に保存します
2.は固定長のデータであるため、任意の場所のレコードに一度でアクセスでき、そこに格納された情報から1.にアクセスすることができます。
いかがでしたか?
PostgreSQLの下側のストレージ周りに興味があるかたは、公式ドキュメントの「第68章 データベースの物理的な格納」もご参照ください。
この記事が気に入ったらサポートをしてみませんか?