
【Part8】学習モデルをハードウェアに最適化したコンパイル(Amazon SageMaker Neo)

AWSでエッジコンピューティング環境を作る Part8です。
学習モデルの軽量化Distillerを、Part7で書きました。今日は、そのモデルをエッジ端末(ラズパイ)上で動かす準備を行います。Amazon SageMakerNeoを用いると、対象のハードウェアに合わせて最適化されたコンパイルをよしなに行ってくれるので、とても良いです。
・PyTorchのモデル保存とONNX形式
・Amazon SageMaker Neoでのコンパイル
・エラーの格闘記録
あたりをお話します。
PyTorchでの学習
前回のDistillerの流れもあり、PyTorchを引き続き使っていきます。PyTorchを使ってみたいという方は、以前私がチュートリアルをやってみた内容を記事に上げているので、ご覧になってください。
REF : チュートリアルやってみた
また、こちらの記事では、学習済みモデルを読み込んで推論&再学習する方法が丁寧に書かれているので、本格的に機械学習を進めていきたい方は必読です。
REF : PyTochでpre-trainedモデルを再学習する
手順(ざっくり)
1. 前回作ったdistillerのモデルを読み込み、ONNX形式に変換する
2. ONNX形式に変換されたモデルをS3に投げ込む
3. Amazon SageMaker Neoを用いてコンパイルする
これだけ!簡単そうですよね。ハマったは最後に書いて行くとして、手順、書いていきましょう。
1. モデル読み込み・変換
前回作ったafter_compression.pth.tarを用います。後述しますが、sagemaker neoがPyTorchの最新バージョンに対応していない(にもかかわらず、distillerは最新バージョンを要求してくる...)ので、DLモデルの共通フォーマットであるONNX形式に変換します。変換コードが↓。compress_testがあるフォルダ内に配置しています。
import os
from distiller.models import create_model
import torch
import tarfile
modelpath = os.path.join("compress_test","after_compress.pth.tar")
onnxfile = "model.onnx"
### pyTorchモデルの読み込み
model_pth = torch.load(modelpath)
### モデルの重みとか、パラメータが"state_dict"に格納されている
parameters =model_pth["state_dict"]
### distillerで同じ箱を作ってやる
model = create_model(False, "cifar10", "simplenet_cifar")
### さっき読み込んだパラメータをはめ込む
model.load_state_dict(parameters)
### ONNXモデルとして出力
# verbose=Trueとしておくと、詳細がわかる
dummpy_input = torch.randn(1,3,32,32, device='cpu')
torch.onnx.export(model, dummpy_input, onnxfile,verbose=True)
# 出力したONNXファイルをtar.gzに圧縮
with tarfile.open('model.tar.gz', 'w:gz') as f:
f.add(onnx)実行すると、verbose=Trueにしているので、モデルの詳細を見ることができます(なぜこうしているかは後述)。以下のようなログが出てくれば成功です。
graph(%0 : Float(1, 3, 32, 32),
%conv1.weight : Float(6, 3, 5, 5),
%conv1.bias : Float(6),
%conv2.weight : Float(16, 6, 5, 5),
%conv2.bias : Float(16),
%fc1.weight : Float(120, 400),
%fc1.bias : Float(120),
%fc2.weight : Float(84, 120),
%fc2.bias : Float(84),
%fc3.weight : Float(10, 84),
%fc3.bias : Float(10)):
%11 : Float(1, 6, 28, 28) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[5, 5], pads=[0, 0, 0, 0], strides=[1, 1]](%0, %conv1.weight, %conv1.bias), scope: Simplenet/Conv2d[conv1]
%12 : Float(1, 6, 28, 28) = onnx::Relu(%11), scope: Simplenet/ReLU[relu_conv1]
%13 : Float(1, 6, 14, 14) = onnx::MaxPool[kernel_shape=[2, 2], pads=[0, 0, 0, 0], strides=[2, 2]](%12), scope: Simplenet/MaxPool2d[pool1]
%14 : Float(1, 16, 10, 10) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[5, 5], pads=[0, 0, 0, 0], strides=[1, 1]](%13, %conv2.weight, %conv2.bias), scope: Simplenet/Conv2d[conv2]
%15 : Float(1, 16, 10, 10) = onnx::Relu(%14), scope: Simplenet/ReLU[relu_conv2]
%16 : Float(1, 16, 5, 5) = onnx::MaxPool[kernel_shape=[2, 2], pads=[0, 0, 0, 0], strides=[2, 2]](%15), scope: Simplenet/MaxPool2d[pool2]
%17 : Tensor = onnx::Constant[value= -1 400 [ Variable[CPUType]{2} ]](), scope: Simplenet
%18 : Float(1, 400) = onnx::Reshape(%16, %17), scope: Simplenet
%19 : Float(1, 120) = onnx::Gemm[alpha=1, beta=1, transB=1](%18, %fc1.weight, %fc1.bias), scope: Simplenet/Linear[fc1]
%20 : Float(1, 120) = onnx::Relu(%19), scope: Simplenet/ReLU[relu_fc1]
%21 : Float(1, 84) = onnx::Gemm[alpha=1, beta=1, transB=1](%20, %fc2.weight, %fc2.bias), scope: Simplenet/ReLU[relu_fc1]
%22 : Float(1, 84) = onnx::Relu(%21), scope: Simplenet/ReLU[relu_fc2]
%23 : Float(1, 10) = onnx::Gemm[alpha=1, beta=1, transB=1](%22, %fc3.weight, %fc3.bias), scope: Simplenet/ReLU[relu_fc2]
return (%23)2. S3に保存
ONNXに変換したモデルができたので、S3に保存しましょう。こちらはバケットを適当に作り、モデルをアップロードするだけです。S3の作り方はPart3あたりを参考にしてください。
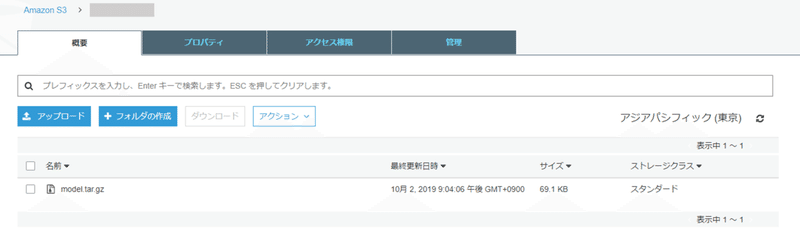
3. SageMakerNeoでコンパイル
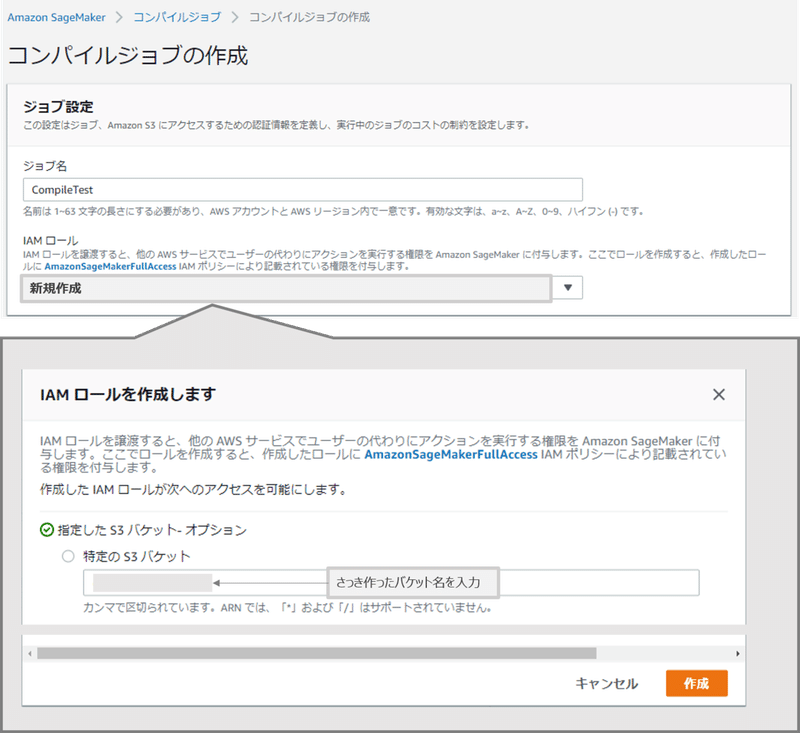
S3に配置したモデルをラズパイで使えるようにコンパイルしましょう。AWSのSageMakerNeoを用います。SageMaker⇨コンパイルジョブを選択し、作成を初めましょう。

ジョブ名はアカウント&リージョンで一意に定まるように、適当に決めてください。また、IAMロールでは、先程作成したS3にアクセスできるようにロールを作成しましょう。
つぎは入力設定です。まず、S3に格納したモデルの場所を設定します。次がデータ入力設定。そしてフレームワークをONNXとして完了です。
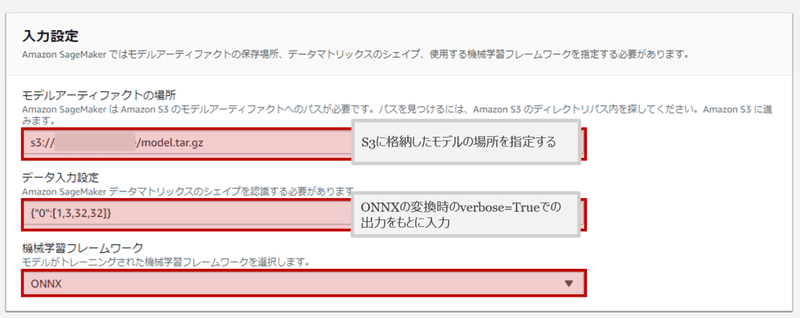
ここで、データ入力設定が重要です。データの型が間違っていると永遠にエラーを吐きます。ここでさっきの変換時に使ったverboseが活きてきます。出力結果の一部を再掲します。
graph(%0 : Float(1, 3, 32, 32),
%conv1.weight : Float(6, 3, 5, 5),
%conv1.bias : Float(6),
%conv2.weight : Float(16, 6, 5, 5),
%conv2.bias : Float(16),
%fc1.weight : Float(120, 400),
%fc1.bias : Float(120),
%fc2.weight : Float(84, 120),
%fc2.bias : Float(84),
%fc3.weight : Float(10, 84),
%fc3.bias : Float(10)):この一番はじめの%0 : Float(1, 3, 32, 32),が入力の型です。これを参考に、{"0" : [1, 3, 32, 32]}と入力します。間違えないようにしましょう。
入力が終われば、最後は出力の設定です。出力場所はさっきのS3と同じにして、compiled/以下に保存されるようにしましょう。対象となるハードウェアはラズパイなので、それ用に最適化してもらいます。すべて入力し終われば、コンパイルを開始しましょう。
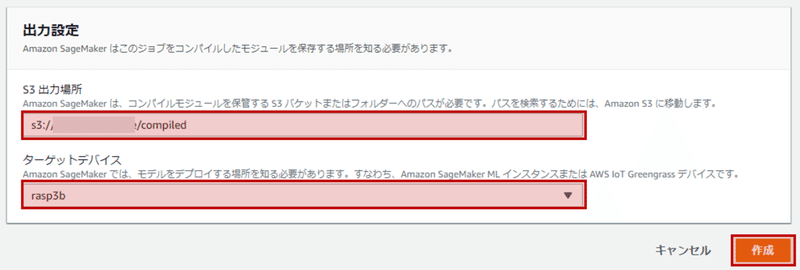
成功すれば下図のようになります。
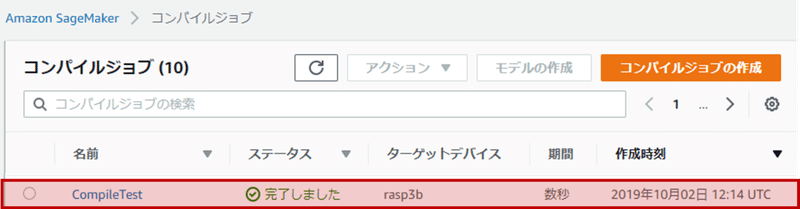
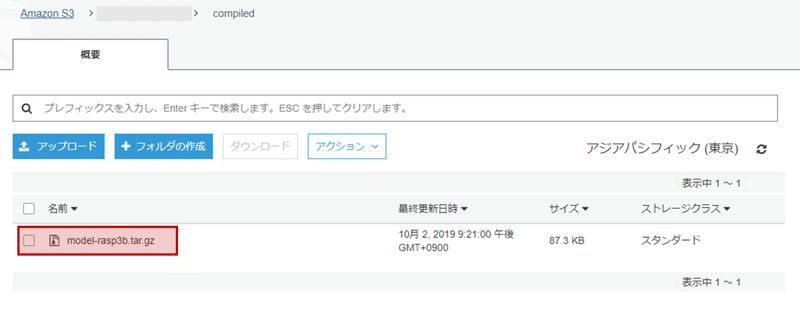
また、S3にはコンパイル後のモデルが入っています。
これをGreengrassを用いてデプロイすれば、学習モデルをラズパイで使うことができます!
Amazon SageMaker Neoで学習モデルのコンパイル格闘記録
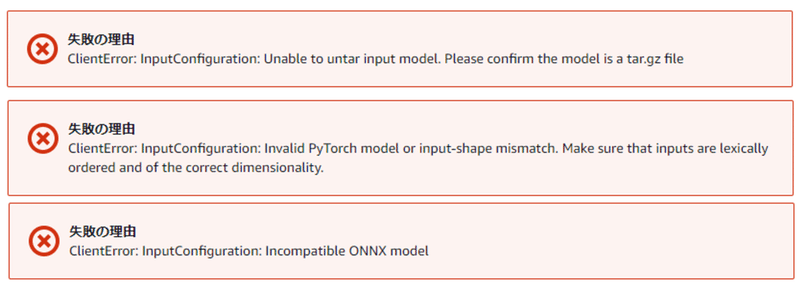
実は、全然スムーズにコンパイルできたわけではありません。PyTorchのモデルをコンパイルしようとすると、実に様々なエラーがでました。格闘記録をエラーメッセージとともに書いておきます。
☑ tar.gzで保存する必要がある。
ClientError: InputConfiguration: Unable to untar input model. Please confirm the model is a tar.gz file
☑ input shapeが決まっているようだ
ClientError: InputConfiguration: Invalid PyTorch model or input-shape mismatch. Make sure that inputs are lexically ordered and of the correct dimensionality.
ここにシェイプタイプの例が書かれているので参考に。気をつけるのは、そのフレームワークがNHWC形式なのかNCHW形式なのかを把握しておくこと
☑ NHWC : Tensorflow
☑ NCHW : MXNet, PyTorch, ONNX
N : Number
H : Height
W : Width
C : Channel
でないと、エラーが出る
☑ PyTorchの互換性が無い
ClientError: InputConfiguration: Invalid PyTorch model or input-shape mismatch. Make sure that inputs are lexically ordered and of the correct dimensionality.
PyTorchだと永遠にエラーがでる。
調べると、PyTorch1.1.0以降には未対応(2019/9/1現在)の模様。使いたい場合は0.4.0にデグレードするか、ONNXに変換するかという選択肢になる。ONNXとは、ニューラルネットの共通フォーマットのひとつで、様々なライブラリを共通のモデルの型に変換できる。
ONNX : Open Neural Network Exchange
ニューラルネットの共通フォーマットの一つ。
☑ ONNX モデルへの変換 (エクスポート)
・Caffe2
・PyTorch
・CNTK
・Chainer
☑ ONNX モデルを用いた推論 (インポート)
・Caffe2
・CNTK
・MXNet
・TensorFlow
・Apple CoreML
・TensorRT (ただしサンプルコードが未公開)
REF1: ONNX公式
REF2: Qiita ONNX形式のモデルを扱う
ONNXにエクスポートすることでとりあえず解決
☑ ONNXにおいて、input shapeのはじめのkeyが違う
Neoコンパイルエラー時のトラブルシューティング
上記リンクの例の通り入力をおいて、ONNXにしても、まだエラーがでた。
ClientError: InputConfiguration: Incompatible ONNX mode
どうやら入力に使っているkeyが違っているらしい。手順3で説明したように、変換時にverbose=Trueにすると、わかる。これで調べて、input shapeをきちんと書き直したところ、見事Finish
長かった...
まとめ
ここまでで、学習モデルをラズパイ向けにコンパイルし、Greengrassにデプロイする準備ができました。途中PyTorchに慣れたり、互換性等々の問題もあって少し苦労しましたが、無事にできてよかったです。
いよいよ次回、Greengrassでデプロイしてエッジコンピューティングを実行していきましょう。コンパイルした推論モデルを動かすDLR(Deep Learning Runtime)を導入し、エッジ推論ができるか試していきます。ではではっ
Part 7. モデル圧縮専用ライブラリDistiller
Part 9. GreengrassとDLR
サポートいただけると励みになります! よろしくおねがいします!!