プログラミング等(2023/2/11):NetworkX有向グラフショートカットノード省略プログラムの試み2

0.まえがき
前回の続きです。
***
(注:プログラミングとしてはあまり参考にならない、ただの備忘録です。)
***
実はあの後、難航しておりました。
二つ問題があり、一つ解決したのですが、本質的には今も解決していません。
1.有向グラフで不要なショートカットとなるエッジを削除する処理を行いたい
解決した方の話をします。
プログラミング言語Pythonには、点と線、あるいは点と矢印でできているグラフ構造(前者を無向グラフ、後者を有向グラフと呼びます)を扱うのに適したモジュール、NetworkXというものが存在します。
私が個人的にやっている作業のためには、有向グラフは非常に便利なので、NetworkXを活用できないか、ということで、いろいろやっていたのです。
で、たくさんデータを読ませているうちに、
「点a,b,cと矢印a→b,b→c,a→cがあった場合、a→cはショートカットとなる。これを省略した方が見やすくなる」
ということで、そういう処理を作っておりました。
(詳しくは前回の記事を見て下さい)
2.「正しいが遅い」プログラムに甘んじていてはいけない
ところが、プログラムを作っている時にありがちな「正しいが遅い」ものができてしまいました。
最初は「ほーん」と思っていたのですが、1週間かかっても進んでないの、さすがにおかしいし困ります。
早くて待たずに済むことには大きな価値があり、逆に時間がかかって待っているだけになるのは大いなる無駄です。
3.繰り返し処理を行う時に、1回の処理の最後に、作業用データを空にした方がよいこともある
プログラムを動かすには、パソコンの中のメモリ(記憶領域)をある程度使わねばなりません。
脳の記憶もそうなのですが、「覚える」余裕があったり、「考える」余裕があったりしないと、覚えられないし考えられないものです。
で、用事が済んだら、明らかに要らん記憶は忘れた方が、脳の余裕のためになります。
『キン肉マン』シリーズの悪魔超人サンシャイン風に言えば
「いつまでも記憶してちゃあ務まらねえ 都合の悪いことは忘れよ! 記憶力の欠如が必要なんだよ」
というやつです。(なぜそんな例を出した?)
プログラムでも、作業のために使っていたデータは、作業が終わったら空にしたり削除しなければなりません。
特に、中にデータを詰められて、空にすることも出来る特殊なデータというのがあります。pythonだとlist(リスト型)等がそうです。
例えば、100件あるデータで100回繰り返し処理をする作業があったとして、処理のためにリスト型のデータを作った場合、作業が終わったらそのリストは1回ごとに空にした方が良い、という話があります。
そうしないとそのリストは肥大化して、しかもその大半はもう作業に使わない不要なもので、それどころかメモリを圧迫して処理はどんどん重くなるのです。
逆に、処理が重くなっている場合、どこかでリストが空にできていない可能性があります。
4.tracemallocモジュール
pythonにはそういうのを調べる方法が提供されています。あったら便利ですもんね。
tracemallocモジュールについては各自調べて欲しいのですが、これを使ってスナップショットを「前」「後」の二回取って比較を取ると、その間に挟んだ処理でメモリ使用量の増減を見ることができます。
上手くいっている場合は
「あるプログラムファイルがこれだけメモリを使ったので使用量がプラスになったが、終わったら使用量が同じ分マイナスされたので、長期的に見ればプログラムは圧迫されていない」
という事態が観察されます。
上手くいってない場合は、
「あるプログラムファイルが使用しているメモリ使用量がひたすらプラスでもりもり増えていく。これはいずれプログラムを圧迫する」
ということが可視化されます。
ということで、やはりありました。
今回は非常に分かりやすく、NetworkXモジュールで用意されている有向グラフオブジェクト、digraphがガンガン使われて増えていっていました。
有向グラフにデータが蓄積されて、使い終わった後も解放されていない、ということが推測されます。
理由もすぐに分かりました。
「繰り返し処理を行う時に、1回の処理の最後に、作業用データを空にした方がよいこともある」
という話をしました。
ソースをよく見ると、
「繰り返し処理を行う時に、繰り返し処理の最後に、作業用データを空にしている」
のでした。
具体的には、有向グラフを空にする処理、digraph.clear()を、「繰り返し処理の」最後に置いていたのです。
一見正しい処理です。
が、その都度有向グラフを空にしてなかったので、ゴミがどんどん増えていたのですね。
今回のプログラムの趣旨に鑑みると、これではダメだったということです。
5.修正成功
ということで、有向グラフを空にする処理、digraph.clear()を、「1回の処理の」最後に追加しました。
こうすると、メモリは正しく増減しました。
そして、処理が、爆速になりました! ウィーピピー!

6.次のTODO
ところが、もう一個壁が立ちふさがりました。
基本的には爆速で進むのです。
しかし、処理がある地点になると、またのろのろになるのです。
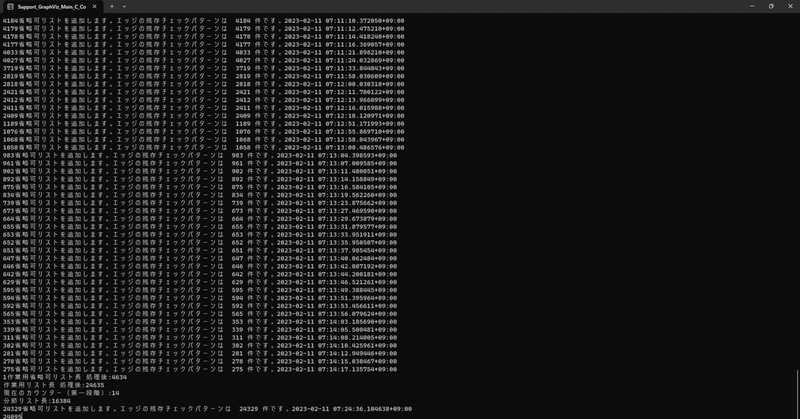
2万行のデータがあると思ってください。
説明しませんが、一度に処理をすると重くてしょうがなくなるので、データを区切って処理しているのです。
最初は1行ずつ、次は2行ずつ、その次は4行ずつ、8行ずつ。倍々ゲームです。
以前から分かっていたことがありました。
倍々ゲームの結果、だいたい16,384行区切りになってから、極端に遅くなるのです。

上の画像のタイムスタンプと右下の時計から判断すると、75分で234行しか処理が進んでいない。
このペースだと60分、つまり1時間でやや甘目にみても200行。24時間、丸一日だと大甘に見て5000行。
チェック元データは約24000行あるから、約5日かかるだろう。
遅い! それは遅い! 一週間とは言わんが5日て。オメーそれはよう。
うーん。これどうすっかな。丸5日待つしかない? それとももっと効率的な方法があるのか? (まあ後で考えよう)
応援下さいまして、誠に有難うございます! 皆様のご厚志・ご祝儀は、新しい記事や自作wikiや自作小説用のための、科学啓蒙書などの資料を購入する際に、大事に使わせて頂きます。