
OpenAIのGPT-4のアーキテクチャへの仮説:Mixture Of Experts(MoE)による拡張性の高いLLM

OpenAI社のGPT-4は、従来のGPT-3, GPT-2.5と比較して巨大な言語モデル持ち、パラメタ数でいうと1,750億〜2,800億個、とされています。これはデータ量で言うと45GBに及びます(従来のGPT-3はその1/3近くの17GB)。データ量が多くなった分、精度や正確性は高くなったと評価されてますが、ハルシネーションによる間違った回答の比率が少なくなったかと言うと そうでも無い、と言う意見も多いし、人間の思考の様な推論(reasoning)がまだ十分にできない、と言うことも根本的な課題です。
AIシステムのパラメタが巨大化する最大の課題は、それをトレーニングするためのコストが著しく高くなってしまう、という事。この辺のスタディはかなりされていると思いますが、この課題を解決する方法の一つとして、MoE (Mixture of Experts) アーキテクチャ、と呼ばれるニューラルネットワークの技術があります。
GPT-4はほとんど内部構造に関する技術情報が開示されていませんが、このMoEを採用している、とされています。MoEアーキテクチャは、特定の「エキスパート」が特定のタスクや情報タイプに特化することを可能にします。具体的にどの様なエキスパートによって構成されているのか、は公表されていません。
これにより、単一のネットワークが全ての情報を処理する代わりに、MoEでは最も関連性の高い部分だけが活動するため、計算効率が向上します。GPT-4のアーキテクチャにMoEが組み込まれることで、より大規模で、複雑で、多様なタスクをより効率的に処理できるようになってる、とされています。
フランス企業である、MistralAI社はMoEに基づいたLLMを開発してオープンソースとして提供している企業として話題を集めています。
当面、OpenAIの独自仕様による動きと、MistralAIに代表されるオープンソース型の動きが拮抗する状況が2024年も続くものと想像されます。
OpenAIの最も厳重に守られた秘密の明らかに: GPT-4のアーキテクチャ
Eric Risco
元の記事: Unveiling OpenAI’s Best-Kept Secret: The Architecture of GPT-4 | by Eric Risco | Dec, 2023 | Medium

OpenAIの進化
2023年はテキスト生成AIにとって画期的な年となり、この革命の中心にはOpenAIがあります。この組織はAI分野のリーディングカンパニーとして台頭していますが、興味深いパラドックスを抱えています。その名に「Open」を冠しているにも関わらず、OpenAIはかつてディープラーニングコミュニティの礎石であったオープンソースの精神から徐々に遠ざかっています。
OpenAIの旅は、オープンなコラボレーションと知識共有へのコミットメントと共に始まりました。同社はAIの民主化と強力なツールを全ての人にアクセス可能にすることについて声高に語っていました。この哲学は、科学論文のオープンな交換と詳細な方法論に長く依存してきた学術研究コミュニティに共感を呼びました。
しかし、ChatGPTやDALL-EのようなOpenAIの技術が前例のない人気を博するにつれて、同社のアプローチは変化し始めました。OpenAIの「Open」という名前の皮肉がより顕著になりました。同社は知的財産の保護を優先するようになり、これは競争が激しい分野で革新的な先進性を維持する必要性に部分的に駆り立てられています。
この変化はいくつかの方法で現れました。かつてのOpenAIの定期的な科学的出版物は、より警戒心の強い技術報告に取って代わられました。これらの報告は広範囲に渡るものの、学術界が重視する深さと透明性にしばしば欠けていました。OpenAIの焦点は製品開発に移り、学術研究の礎である再現性の科学的原則が後回しにされるように見えました。
この移行の結果、GPT-4などのモデルの複雑な詳細が秘密に包まれた、より閉鎖的なエコシステムが生まれました。このアプローチはOpenAIが競争優位を維持するのに間違いなく役立っていますが、AI開発におけるオープンコラボレーションの未来についての疑問も提起しています。2023年を振り返ると、OpenAIはAI技術の軌道を形作るだけでなく、ディープラーニング分野におけるオープンサイエンスと独占的イノベーションのバランスについての議論を巻き起こしたことが明らかです。
ChatGPTとDALL-Eの影響
OpenAIの2つの創造物であるChatGPTとDALL-Eは、人工知能の人気を新たな高みに押し上げるのに中心的な役割を果たしています。これらの技術は、AIの深い能力を示すだけでなく、一般の人々がAIが達成できることについての認識を変えました。
特にChatGPTは、生成テキストAIの分野における顕著な存在として登場しました。一貫性があり、文脈に関連する会話を行う能力により、技術業界と一般の人々の両方を驚かせています。ChatGPTによって象徴される言語モデルの進歩は、2023年をテキスト生成AIの年として特徴づけ、私たちの日々のデジタルな交流における大規模言語モデルの重要性を強調しました。
一方、DALL-Eは、その生成能力を通じて視覚芸術の分野を革命的に変えました。テキストの説明から複雑で入念な画像を作り出すことにより、DALL-Eは創造性の新しい道を開き、テキスト生成を超えたAIの多様な可能性を示しました。
しかしながら、これらの技術の台頭は、OpenAI内部のパラダイムシフトを伴っています。同社の焦点は、製品開発とその技術の商業化にますます傾いています。この変化は、会社の初期の精神の基礎であった学術的およびオープンソースの原則からの移動を伴っています。OpenAIの技術が洗練され、人気を博しているにつれて、同社はその知的財産をより保護するようになりました。この戦略的シフトは、最新のモデルや進歩に関する情報の共有に対するアプローチに明らかです。
オープンな科学的コミュニケーションからより警戒心のある態度への移行は重要な意味を持っています。これはAI業界におけるより広範な傾向を示しており、主要プレイヤーが自身の進歩についてより秘密主義になっています。このシフトは、急速に進化するAIの世界において、オープンな科学協力と商業的利益の保護の間のバランスに関する疑問を提起しています。
GPT-4のアーキテクチャの謎
OpenAIのGPT-4モデルに関する興味は、AIコミュニティにおける中心的な話題となっています。2023年が進むにつれ、AI開発の以前の透明性の時代からの顕著な変化が明らかになり、OpenAIは画期的なモデルGPT-4に関してより控えめな態度を取っています。広範な関心と期待にも関わらず、GPT-4のアーキテクチャの具体的な詳細はほとんど謎のままであり、オープンな共有と協力の以前の精神から鮮明に逸脱しています。

3月に、OpenAIはGPT-4に関するいくつかの洞察を提供する技術報告を公開しましたが、これは生成前訓練変換モデルであるという同一性を確認する程度でした。しかし、この発表は業界の専門家や学者が熱望する詳細な知識の表面をかろうじて掠めるに過ぎません。100ページを超えるこの報告は、わずかな詳細しか提供せず、この先進的なAIモデルの複雑さに関する憶測を煽っています。
GPT-4の規模についての詳細は、様々な業界のリークや議論を通じて明らかになってきました。テックコミュニティの注目すべき人物であるGeorge Hotzは7月のポッドキャストでモデルの構造に光を当てました。彼はGPT-4の印象的なパラメータ数と混合モデルアーキテクチャの使用を明らかにしました。それでも、これらの洞察はOpenAIの公式な支持なしに提供されており、教育的な推測と業界の憶測の領域に留まっています。
GPT-4に関する包括的な情報の欠如は、その運用メカニズムに関する不確実性と好奇心を高めています。この不透明さは、学術的再現性とオープン性が最重要だった過去のAI研究の常識と鮮やかに対照をなしています。OpenAIの現在のアプローチは、AI進歩が広くコミュニティ内でどのように広められ、議論されるかにおいて顕著な転換を強調しています。
GPT-4に関する限定的な公開は、AI業界におけるより広範な傾向を象徴しており、主要な実体が技術革新をますます秘匿しています。学術的なオープンネスよりも産業秘密を優先するこの進化は、AI研究の将来の軌跡に関して重要な疑問を提起します。それは、AI革新を求める探求における協力と競争の間の増大する緊張を強調し、分野における共有の知識の集合的な進歩と私有利益の間のバランスの再評価を促しています。
大規模言語モデル(LLM)のジレンマ
2023年はAIの市場を再形成している傾向が続き、さらに強まっています:大規模言語モデル(LLM)の開発です。これらのモデル、特にOpenAIのGPT(Generative Pre-trained Transformer)シリーズのようなモデルは、AI革命の最前線にあります。しかし、より大きなモデルを構築するレースは、探求する価値のある一連の課題と妥協をもたらしました。
LLMの魅力は、一見単純な前提に基づきます:より大きなモデルで、より多くのパラメータを持つものは、一般的に性能が良い傾向にあります。この考え方は、GPT-2からGPT-3、そしておそらくGPT-4へのモデルの進化の背後にある原動力です。より多くのデータと計算能力を持つこれらのモデルは、人間の言語の細かいニュアンスを捉え、より正確で文脈に関連する出力を生み出すことができます。
しかし、このアプローチは犠牲が伴います。これら巨大なモデルを訓練し、運用するコストは、金銭的な観点だけでなく、計算資源とエネルギー消費の観点からも増加します。例えば、より大きなモデルはより多くの処理能力を要求し、それに伴いエネルギー消費も増加し、環境への懸念を引き起こします。さらに、これらのモデルの増大する複雑さは、特定のタスクでの非効率を引き起こす可能性があります。
OpenAIのGPT-4はこのジレンマが表面化してる、と考えられてます。そのアーキテクチャに関する詳細はほとんどありませんが、前任者よりもはるかに規模の大きいシステムであるとされており、おそらく兆単位のパラメータを持つと考えられています。この拡張は、より洗練されたレスポンスを可能にする一方で、計算資源に対するより大きなコストの消費を意味します。
さらに、単にモデルをスケーリングアップする方法論についても疑問が呈されています。モデルが大きい方が良い結果を出す、という仮定は、特にモデルが管理や最適化がますます困難になる規模に達すると、必ずしも真実ではありません。サイズ、効率、および有用性の間の複雑なバランスをとることです。
LLMに関連する課題はその適用にも及びます。これらのモデルが大きくなるにつれて、それらのCO2排出量増大に繋がり、環境に対する懸念を引き起こします。また、そのような大規模モデルを訓練し、展開するためのコストも増大し、汎用的なアクセスを制限する可能性があり、OpenAIのようなリソース豊富な少数に権力と能力が集中してしまう懸念があります。
GPT-4におけるエキスパートの混合(MoE)モデルの時代
AIコミュニティは、エキスパートの混合(MoE)モデルの実装に向けて顕著なシフトを見ています。これは、特にOpenAIのGPT-4のアーキテクチャに関連しています。このシフトは、大規模言語モデル(LLM)の設計における重要な進化を表し、以前のアーキテクチャの固有の限界や非効率性に対処しています。
MoEコンセプトの理解
MoEアーキテクチャは、ニューラルネットワークが構築され、運用される方法においてパラダイムシフトを導入します。従来、GPT-3のようなモデルは密な構造をしており、ニューラルネットワークの各部分が情報の各ピースを処理するのに関与していました。このアプローチは効果的でしたが、計算集約的であり、特にモデルのサイズが大きくなるにつれて効率が低下しました。
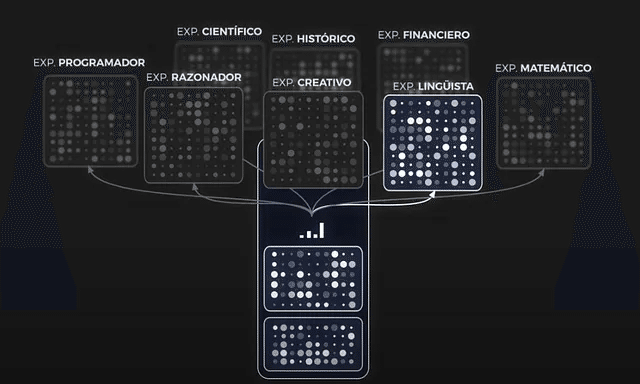
MoEモデルは、しかし、異なる戦略を採用しています。単一の密なネットワークを使用する代わりに、MoEはモデルをいくつかのサブモデルまたは「エキスパート」に分割し、それぞれが異なるタスクやデータ処理の側面に特化しています。この構造により、入力の性質に基づいて関連するエキスパートのみが活性化されるため、よりターゲットを絞った効率的な計算が可能になります。
GPT-4におけるMoEの実装
OpenAIが具体的な詳細を公式に確認していないにもかかわらず、GPT-4がMoEアーキテクチャを利用しているという説があります。この説は、様々な業界情報や分析に支えられており、GPT-4がその前身の密なモデルアーキテクチャから大きく離脱しているのでは、という考え方です。
もしGPT-4が実際にMoEフレームワークに基づいている場合、効率性と能力の観点で大きな進歩を遂げている可能性があります。モデルは、おそらく兆単位のパラメータを持ち、それが複数のエキスパートモジュールに分散されていると推測されています。各モジュールは専門的な焦点を持っており、比較的サイズの密なモデルよりも特定のタイプのタスクを効果的に扱うことができるようになります。
この構造は、モデルの全体的なパフォーマンスを向上させるだけでなく、リソースの効率性も高めます。特定のタスクに関連するネットワークの部分だけを活用することで、GPT-4は演算処理のオーバーヘッドを減らしつつ、高レベルのAIパフォーマンスを提供する可能性があります。
MoEのAI開発への影響
GPT-4のようなMoEモデルの採用は、AI開発における重要なマイルストーンを示しています。これは、より広範囲で、より能力のあるシステムを求める一方で、計算リソースと効率性の制限との間のバランスをとる、AIモデルのスケールアップにおけるコストの課題に対処しています。
さらに、MoEモデルはAI研究と応用のための新たな道を開きます。それらは、より洗練された多用途のAIシステムを構築する方法を提供し、より動的に幅広いタスクに適応できます。この柔軟性は、AIが多様なセクターやアプリケーションに浸透し続けるにつれて重要です。
OpenAIの支配とオープンソースコミュニティからの声
GPT-4のようなOpenAIのモデルがAIで可能性を広げ続ける中、オープンソースAI開発の領域では並行した話題が登場しました。GPT-4に関する技術情報の制限を続けるOpenAIは、結果的にオープンソースによるより開放的な動きを促進する結果になってます。
オープンソースAIモデルの台頭
2023年は、共有された知識とイノベーションの精神を維持するコミュニティによって推進される、オープンソースAIプロジェクトの年でした。この年には、多くの組織や開発者が登場し、GPT-4のような独占的な動きに対してだけでなく、さまざまな代替案を提供するモデルを紹介しています。
特筆すべき例として、フランスの会社Mistral AI社がこのオープンソース活動の最前線にいます。同社が紹介した新しいオープンソースモデルは、オープンソースによる可能性を示唆してます。
Mistral AIの貢献:ギャップを埋める
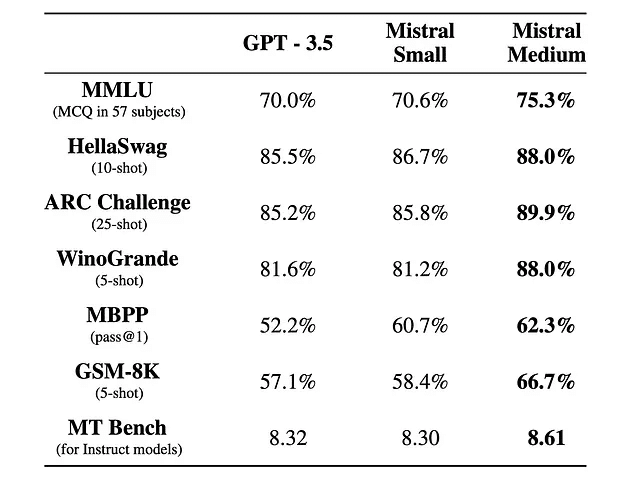
Mistral AIの最新の提供は、オープンソースコミュニティが所有権のあるモデルと同じペースで進む、そして場合によってはそれを上回る可能性を明確に示しています。彼らのモデルのユニークな側面は、そのアーキテクチャと効率性にあります。多くのパラメータを持っているにも関わらず、彼らのモデルははるかに小さいモデルの速度と効率で動作するように設計されています。
Mistral AIの貢献:ギャップを埋める
Mistral AIの最新の提供は、オープンソースコミュニティが(Open AIの様な)クローズドモデルに対して、場合によってはそれを上回る可能性を明確に示しています。彼らのモデルのユニークな側面は、そのアーキテクチャと効率性にあります。多くのパラメータを持つにも関わらず、そのモデルははるかに小さいモデルの速度と効率で動作するように設計されています。
オープンソースAIの将来の軌跡
これらの2023年における活動は、AIの次なるステージを示唆してます。GPT-4のようなクローズドモデルに対するオープンソースコミュニティの反応は、技術的優位性のための競争だけではありません。それは、より包括的で、共同的で、透明性の高いAI技術への動きです。
2024年を見据えると、クローズドモデルとオープンソースのAIへの取り組みの違いが今後続くものと思われます。この二つの領域間の相互作用は、技術的な競争だけでなく、開放性、協力、アクセシビリティの原則が中心的な役割を果たすAI開発の倫理についても重要な動きです。2023年のオープンソースコミュニティの活動は、イノベーションを共有する、という精神が依然として強いことを証明し、AIの将来の軌跡の特徴を定義する可能性があります。
生成AIの進化と未来
OpenAIは、ChatGPTとDALL-Eを通じて、期待を超えるだけでなく、可能なことの境界を再定義しました。この年は、AIが未来的な約束から私たちの日常生活における不可欠な現実へと移行した時として記憶されるでしょう。これらの技術の驚異的な進化は前後を分け、AIが遍在し、私たちの社会的および専門的な構造にますます統合される未来への扉を開きました。
2024年に入ると、生成AIの展望は刺激的であると同時に挑戦的です。GPT-4のようなモデルの成長する能力とオープンソースセクターのイノベーションは、AIがより進んで効率的であるだけでなく、よりアクセスしやすく民主的になる未来を予測しています。オープンソースコミュニティは、最近の努力により、より協力的で透明なAIへの道を約束し、テックジャイアンツの支配に挑戦し、イノベーションと創造性のための新しい可能性を開きます。
この記事が気に入ったらサポートをしてみませんか?