
RAGの実装はエージェント化へ進化

元データ: RAG Implementations Are Becoming More Agent-Like | by Cobus Greyling | Apr, 2024 | Medium
基本的なRAGの実装にはいくつかの脆弱性があり、これらの弱点に対処する取り組みが進むにつれて、RAGの実装はエージェント的なアプローチに進化しています。
はじめに
ジェネレーティブAIフレームワークの進化によって、良いデザインとされるものへの普及が広がっていることは興味深いです。
例えば、プロンプトエンジニアリングの進化ですが、プロンプトは変数を注入するためのプレースホルダーを備えたテンプレートに進化しました。
この進化はさらにプロンプトチェーンにつながり、最終的には多数のツールを備えた自律エージェントの開発に至りました。これらのツールはエージェントが必要とするように組み合わせて使用されます。
同様の軌道で、RAGフレームワークも注目すべき変革を遂げています。
最初は基本的なRAGセットアップが十分とされていましたが、現在ではRAGスタックに追加の知的機能を統合する傾向が高まっており、RAGアーキテクチャにさまざまな要素を組み込む動きも見られます。
RAGの標準に何が問題なのか?
まず、RAGアーキテクチャにおいて、プロンプトの構造がますます重要になっており、Chain-of-ThoughtなどのテクニックがRAGの実装のために導入されています。
単にプロンプトに文脈参照データを注入するだけでは不十分であり、現在はパフォーマンスを最適化するためにプロンプトの表現や文法に大きな注意が払われています。
次に、RAGは2つの主要な側面で静的な特性を示すことが認識されています。
RAGはしばしば会話の文脈を考慮せず、直近の対話を超えて全体的な考慮に拡張することができません。
さらに、取得に関する意思決定プロセスは通常、適応性に欠ける静的なルールによって支配されています。
第三に、最適化されていない取得や余分なテキストに関連する不要なオーバーヘッドが増えている現状があり、望ましくないコストや推論の遅延が発生します。
第四に、最良の応答を決定するために多段階のアプローチや分類器が使用されたり、ユーザーのリクエストを分類するためだけに複数のデータストアを利用することがあります。これらは、しばしば特殊なタスクのためにモデルを訓練するために注釈付きデータに依存しています。
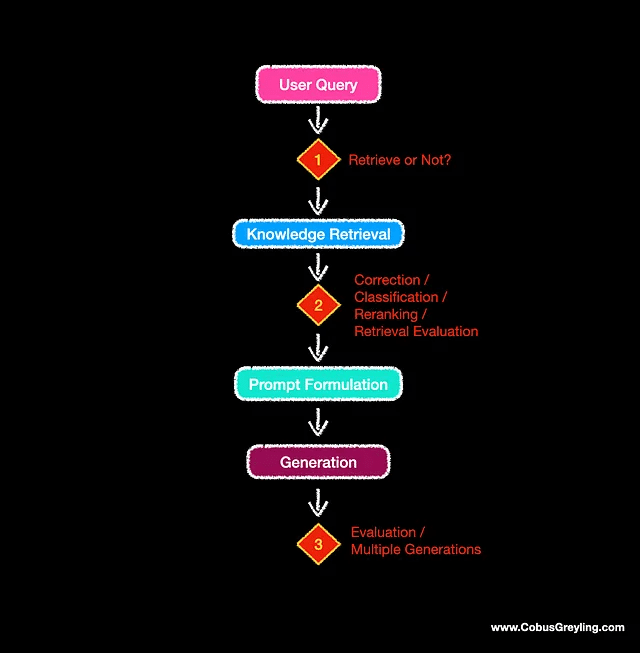
画像は、RAGアプローチにおける3つの重要な意思決定ポイントを示しています。最近発表された多くの論文は、RAGパイプラインのこれら3つの領域を解決することに焦点を当てています。
いつデータを取得し、どこから取得するかを知ること。
取得したデータの評価、修正、または少なくともある種の品質チェックを実行すること。
最後に、生成後のチェックを実行する必要があります。一部の実装では、複数の生成が実行され、最良の結果が選択されます。また、生成された結果に対して真実のチェックを行うフレームワークもあります。
Agentic RAG
以下のアーキテクチャは、LlamaIndexのチュートリアルから導き出したもので、彼らがエージェンティックRAGと呼ぶものです。これは、RAGがエージェントのようなスタイルで実装されているものです。
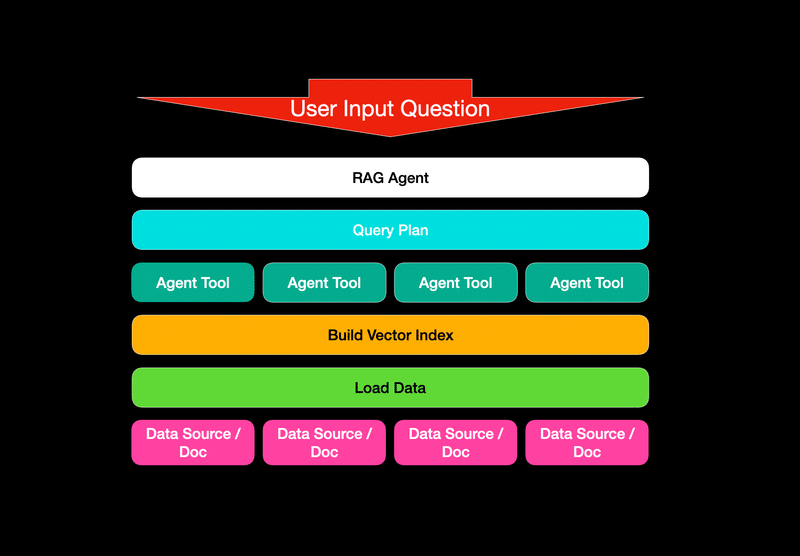
各ツールは、説明された文書または文書セットに関連しています。各ツールの説明により、エージェントはどのツールを選択するか、またはどのツールを組み合わせるかを知ることができます。
ユーザーのクエリは、複数の文書にわたる質問が提出されることがあります。複雑な質問がなされ、エージェントは異なる文書にアクセスする異なるツールを統合して質問に答えます。
例えば、複数のエージェントがそれぞれ数ヶ月にわたる財務諸表をカバーしています。RAGエージェントに、3ヶ月間の利益(収益から費用を差し引いたもの)を計算するように求められた場合はどうでしょうか?
標準のRAG実装では、複数の文書にわたるこのような複雑なユーザークエリを計算することができず、別途、合成および処理する必要が出てきます。
この記事が気に入ったらサポートをしてみませんか?