
AWS re:Invent 速報(Dr. Swami Sivasubramanian (VP-Data&AI) キーノート @ ラスベガス

2023-11-29(Wed)
AWS re:Invent 2023 -
Dr. Swami Sivasubramanian (VP-Data&AI)
キーノート
Wed, Nov 29, 2023 8:47AM • 1:30:32
Data + GenerativeAI + Humans

世の中には大量のデータが存在していて、今はまさに生成AIがそのデータを活用できる時代になってきている。今の時代は、3つの要素が融合している時代。
データ:人間にとって最も価値のある媒体
生成AI:データと人間を直接繋げるのが生成AIの役割
人間:最終的に人間に価値が提供できる事が最重要

AWSの考える、生成AIを作るのに必要な要素
複数のファウデーションモデルを選択できる事
データのプライバシーが保護されてる事
使いやすいツールの整備でアプリ開発が容易である事
MLインフラが上記の目的達成を実現するために作られている事
Generative AI

AWSの提供する生成AIは、3つのレイヤによって提供する
最初のレイヤーは、生成AIのインフラとトレーニングや推論を行う環境
2つ目のレイヤーは、ファウンデーションモデルやLLMでアプリ開発をするためのツール群
3つ目のレイヤーは、容易に生成AIを利用したアプリが提供されている環境
Amazon Bedrock

AWSの生成AIのソリューションの中核を担うのは、Bedrock

一つのプラットホームの上で、複数のファウンデーションモデルが提供されてる事が重要なポイント
Anrthropicのサポート

[ 新発表 ] Anthropic Claude 2.1が新たにこのファウンデーションモデルのファミリーに追加
200Kトークンをサポート
Hallucinationの大幅削減(約半分に)
プロンプトの構築が容易になり、作業工数が25%削減
Meta社のLlama 2のサポート

[ 新発表 ] Llama 2 70Bのサポートも発表。従来のLlama 2よりはるかに規模の大きいタスクに対応可能
Amazon Titan

AWS独自のファウンデーションモデルの紹介:
Amazon Titan - Text Embeddings
ベクトルデータベースのサポート
Amazon.comでもこのファウンデーションモデルが採用されている。

Amazon Multi-Modal Embeddings
テキスト、イメージの統合的にembeddingができ、マルチモーダル(文字+画像)の検索ができるようになる

Amazon Titan Text Lite:
Amazon Titan Text Express:
文字情報のembeddingに特化したツール。
より精度の高い結果を出す
特にText Liteは非常に安く、早く処理ができる
チャットやドキュメントで文字情報のみの場合に有効

Amazon Titan Image Generator:自然語の投入によるイメージの生成
広告業界などで広く使われてる
自然のプロンプトで完成度の高いイメージ生成を行う
全ての生成イメージはウォーターマークが埋め込まれる
生成されたイメージは、著作権侵害で訴えられてもAWSが保証する

重要なポイントは、全ての生成イメージはウォーターマークが埋め込まれている事がポイント。これは著作権を保護するために必要な対応。

すでに顧客数は、1万社を超えている。

SAPでは、Concur(同社の旅費精算システム)で導入済み

Georgia Pacific社はグローバルな紙/パルプ業者で、IoTシステムにBedrockを導入してる

United Airlines社では、自然語で飛行機の遅延情報を確認し顧客サポートの向上に活用してる

Intuit社も顧客の一つで、そこでの導入事例を紹介したい。
Intuit社 事例紹介

Intuit社のVP of AI、Nhung Ho氏
Intuitは1億を超える顧客/企業にサービスを提供
2019年にAI主導の企業に変換することを決定、HRと税務処理にAIを活用する事に注力
AWS上にデータを全て集約して、データレイクの運用を実施
SageMakerを使って企業内のAIのシステムの開発を実施
65億のMachine Learning Prediction/日
企業は5億個/コンシューマには6万個のデータポイント
ユーザに対して年間、8.1億のAI処理数

Intuit社は独自の生成AIシステム、GenOSを開発、AWS上で稼働。
4つの柱で構成されている。

GenStudioと呼ばれる生成AIのアプリ開発とテスト環境

GenRuntimeはその開発したアプリの稼働環境

GenUXは開発したアプリの統一したUXを提供するためのツール
3rdパーティのアルゴリズムを使用するので、UXが非常に重要

Intuit Assistは生成AIアシスタントサービス
TurboTax, QuickBooks, MailChimp等、全製品でサポート
Fine Tuning
生成AIアプリが自社に固有のサービスを提供するためにも自社の顧客とビジネスに関する知識を十分に持っている事が重要で、これがFine Tuningのプロセス。
データをラベル付けされたデータセットにし、付属コンテンツを追加した上でトレーニングを行うプロセスをAmazon Bedrockが実施。

Amazon独自のファウンデーションモデルである Titan は、Fine Tuningの機能に加えて、Continued Pre-Training 機能も実装。後者は変更の多いデータ(トランザクション、価格、製品仕様、在庫状況、等)に対応するために継続的にファウンデーションモデルにデータ提供とトレーニングを行うための機能。

Fine Tuningの機能の機能はBedrockでサポートする他のファウンデーションモデルでもサポートされる。(Anthropicは将来)

社内のデータソースで最新のデータをAIシステムに投入するためには、Retrieval Augmented Generationと呼ばれる技術が必要(RAGと呼ぶ)。
通常、企業のデータはベクトルデータに変換して、専用のベクトルデータベースで管理する必要がある。
Knowledge Bases for Amazon Bedrock

RAG構築までの一連のワークフローを支援するツールとして、Knowledge Bases for Amazon Bedrock が機能発表されている。
ベクトルデータベース

ベクトルデータベースのサポートは次の通り:
Vector Engine for Amazon OpenSearch Serverless
Redis Enterprise Cloud
Pinecone
Amazon Aurora (将来)
MongoDB (将来)

Bedrockを使った生成AIアプリの作り方は、次のステップを通りよう、設計されてる。
ファウンデーションモデルの選択
自然語でInstructionsを指定し、Action Groupの追加(APIスキーマの設定)
稼働環境のLambda Functionsの指定
アップロードする関連するデータソースの選択

これらの一連の作業を実施するためのツールとして、Agents for Amazon Bedrock が発表されている。

デモアプリ
事例として、Do It Yourselfのアプリを一つ作ってみた。
自然語を使って、バスルームのアップグレードを行うアシスタントアプリを開発
どのような改造をしたいかを指定することでアシスタントが手順をもってアドバイスをしてくれる。

まずはバスルームのイメージ図を収集し選択

対話型のセッションを通してイメージの絞り込みを行う

デザインを選択した後、そのイメージを作るために必要な部品などのリストを収集

店に通わず、各部品のレビューも参照できる

引き出しのハンドルの選択の際にもBedrockは指定したデータソースをナレッジベース化して在庫の確認、等を実施

バスルームのアップグレードに必要なデータが全て揃うことになる。

さらに高度なアプリを開発したい人に対しては、AWS Generative AI Innovation Center というAI/MLのスペシャリストがアドバイスを提供するサービスが提供される。
Custom Model Program for Anthropic Claude

特に来年早々からは、Anthropic Claudeをベースとしたアプリケーション開発サービスが提供開始される。エキスパートによるサポートに加え、企業の独自のデータをどのように生成AI化するかについて支援します。

当然、こういったアプリの開発運用にはコンピューティングリソースが必要で、AWSは13年、NVIDIA社と協業して高性能のGPUを実装したクラウド環境を提供してる。
Amazon SageMaker

ソフトウェアとしては、AWSはSageMakerを使った開発、トレーニングを支援するツールやワークフローを提供し、Stability AIやHugging Faceのファウンデーションモデルをサポートしてる。

ファウンデーションモデルはトレーニングに大きな労力とノウハウを要する。
データの収集
処理するためのクラスターを生成
モデルのトレーニングを分散して行う
モデルの最適化のチェック
分散環境におけるハードウェアのメンテナンス
Amazon SageMaker HyperPod

このプロセスをスムーズに進めるために、SageMaker HyperPodを提供開始
モデルのトレーニング時間を40%削減
分散トレーニングの環境が設定されていて数千個規模のGPUによる環境が簡単に運用可能
マネージドサービスなのでコストの最適化、MTTRが保証される

perplexity社の事例紹介
これ以外に、SageMakerに関する新機能の発表はいっぱい行われている。


Arvin Srinivas, perplexity社のCEOが登壇。
perplexityは、対話型のサーチエンジン
シンプルな質問から始まって、対話型で深い分析を行う支援を提供。
プロンプトエンジニアリングが必要が無い点がポイント。
現在、AWS上で全てを稼働させている。

最初はBedrock+Anthropic Claude2を使ってモデルのトレーニングを実施。
Claude2経由で大規模なファイルのアップロードが可能になり、クローズド型の他LLM上のWrapper以上の能力をつける事が可能に

次は、Llama 2やMistralなど、複数のモデルを実装しオーケストレートし、個々にトレーニングをしている。複数モデルの実装とトレーニングの際に、Amazon SageMakerとHyperBotが非常に容易である事がわかり採用をした。

HyperBotを使ってトレーニング工数のスループットが2倍に改善された。
AWSの顧客サポートも非常に役立った。


現在これらの機能はすべてGAとして発表してる。
Strong Data Foundation

生成AIを開発運用するために不可欠なのは、汎用性が高いデータファウンデーションが不可欠。
AWSはその点が強み:

データソース
Aurora
RDS
DynamoDB
MSK
OpenSearch Service
分析
Redshift
S3
EMR

データを運用するツールも必要
QuickSight
そして、SageMakerとBedrockはAI/MLのツールとしてAWSのデータファウンデーションを支援するツール群の人として位置付けられる。

AWSはベクトルデータと実情報を一緒に管理する戦略を取っていて、そのメリットは下記の通り:
使い慣れてるデータベースツールでベクトルデータも同時に管理可能
新たなベクトルデータベースの導入によるライセンスや管理コストを避ける事ができる
ユーザに対する高い性能が提供可能
ベクトルデータベースと実データベースの間の同期や移動が必要ない
ベクトルサーチ

今年の初めの発表ではpreviewではあったが、正式にGAとしてリリース。
Amazon OpenSearch Service
Amazon OpenSearch Serverless
Amazon Aurora PostgreSQL
Amazon RDS for PostgreSQL
Amazon DocumentDB(ドキュメントデータ)
Amazon DynamoDB via zero-ETL
Amazon MemoryDB for Redis
Amazon Neptune(グラフデータ)
Zero-ETL機能

AWSは従来から zero-ETL を主張している。
ETL工数はデータストア間で最も時間と労力がかかるもので、これをいかに削減する事がシステムの開発工数に大きく関係している。
Redshiftを主軸として、今年の最初に発表したAurora MySQLのzero-ETLに加え、DynamoDB、PostgreSQL、RDSもサポートを発表。
Amazon OpenSearch Service zero-ETL integration with Amazon S3

これらに加えて、OpenSearch ServiceとS3との間のzero-ETLのサポートを発表。
Amazon DataZone

昨年、Amazon DataZoneを発表し、AWS環境内のデータ共有やガバナンス管理などを可能にするツールを提供。
Amazon Clean Rooms


さらにデータ分析のニーズを拡張して、複数の異なる組織/企業がAWS上でデータ分析のコラボレーションをできる環境を提供開始。これがAWS Clean Roomsと呼ばれるサービス。
データプライバシーは確保しつつ、異なる組織同士でデータモデルの比較、統合ができるようになる。
医療業界専用のClean Roomも提供予定。
Booking.com事例紹介

Booking.comのCTO,Rob Francis氏の登壇
同社のサイトで実装してる生成AIの紹介

Booking.comは:
150PBのデータ量
2800万の物件を提供
世界54カ国を対象
5万2千のレンタカーロケーション
数千に及ぶアトラクションの紹介

LLMはLlama 2を採用、SageMakerを介して、対話型のアプリを開発。

予約の作業を自然語の入力で簡単にできるように開発。この時点で留意している点。
旅行の予約に関する入力だけを抽出(関係ないデータは排除)
プライバシーに関わる個人情報は排除

ユーザにとって、判断の基準として顧客レビューも重要なリソースで、それもSageMakerを通して知識ベースとしてJSON形式で入力
Amazon Q
Amazon Qと呼ぶ、AIアシスタントを発表

対話型のQ&Aシステム
企業のデータ、コード、システムを理解
役職(ロール)によってインタフェース(提供情報)が変わる
セキュリティとプライバシーは最重要視
Amazon Generative SQL in Amazon Redshift

特にコーディング作業において、SQLの生成をAmazon Q経由で自動化しRedshiftに統合する機能を提供開始

ETL処理もデータパイプラインの構築で工数の多い作業だけど、ここにもAmazon Qが自然語でデータ統合パイプラインの構築ができる機能がニーズとして高い。
Amazon Q Data Integration in AWS Glue

その機能を提供するのが、今回発表するAmazon Q data integration in AWS Glue。
データインテグレーションジョブを早く作れる
チャット画面を通してトラブルシュート
データインテグレーションに対するヘルプも充実

例えば、自然語で次の指示を出す事ができる。
S3からデータを読み込む
知識情報(Knowledge Records)を(ベクトルかも含めて)抽出
Redshiftに結果を書き込む
Amazon Q導入事例

Shannon Kalisky, Senior Product Manager at AWSによるAmazon Qに関するプレゼン。

飛行機の予約の変更のアプリの開発。

まずは大量の異なるデータをまとめる必要がある。
荷物に関するデータはS3
顧客データ、フライトスケジュール、飛行機の運行状況はすべてRedshift
支払い情報、顧客の属性情報のデータはAurora
天候に関するデータはKinesisにストリーミングされる

従来の手法であればETLパイプラインの構築に数週間かかってしまう。

S3上のデータは自動的にRedShiftに同期される
AuroraからRedshiftへのデータ移行はZero-ETL機能でリアルタイムで行われる
KinesysからのデータはRedshift Streaming Ingestion機能でRedshiftに移行

Redshiftにデータを集約させてから、Amazon Qでインサイトのダッシュボードを作る

飛行機の予約変更の処理時間が格段に短くなったので、飛行機の予約変更に要する時間が大幅に短縮した事がわかる分析結果を整理したExecutive SummaryのダッシュボードをAmazon Qを使って作る。

また、経営者向けにAmazon Qを使って、このアプリによるデータストーリー(Data Story)を作らせる。カスタマイズが容易である事が大きな特長。


パラグラフの内容を箇条書きに変更することもAmazon Qで簡単に。
また、このデータストーリーを組織内に共有も可能。
トヨタ自動車の導入事例

運転の安全性を確保するためにAIを活用してる。
例えば事故に会った時に、緊急対応車に対して必要なデータを自動的に提供できる仕組みを開発。
そのためには日頃から数百万台の自動車から自社のプラットホームに対してペタバイト級のデータを収集してる。
この大量のデータを処理するためにはクラウドは不可欠で、AWSに実装している。
この実装により、イベントが起きてから3秒でコールセンタから連絡を取る事が可能になってる。
最近ではBedrockによるマネージドサービスによってオーナーマニュアルを知識化し、生成AIによるアシスタントの開発も行っている。
Human Input

生成AIシステムの最も重要な要素は人間による情報のインプット。
Model Evaluation and Selection

モデルの評価と選択のプロセスが最も人間のフィードバックが必要とされる領域
ユースケースに最も適したモデルを選択することによって精度や性能を最適化できるが、データサイエンスのノウハウと多大な処理時間が必要になる。

まず最初に、データセット選定と評価の際のクライテリアを明確化する必要がある。

その後は、人間による評価のワークフローを決める必要がある。

最後はその評価を行うためのツールをビルドするステップ。
Model Evaluation on Amazon Bedrock

Model Evaluation on Amazon BedrockのPreviewを発表。ユースケースに最適なファウンデーションモデルの評価を比較、選択が可能になる。
キュレートされたデータセットとユーザが定義したメトリクスで評価を自動化
AWSのエキスパートによるワークフローのワークフローのレビュー
メトリクスやモデルの性能をレビューしやすくするレポート
SageMaker Studioでもサポートされている。
Udacity経由でAWSの生成AI教育コース

現時点で100以上のAIとMLのコースを提供中
PartyRock

無償でノーコードのAIアプリ開発環境の提供

リリース以降,既に数千ものアプリケーションが開発されている。

Bedrockで提供されるファウンデーションモデルがサポートされる。
今日から、Titan Text ModelとExpressとLiteがサポート。
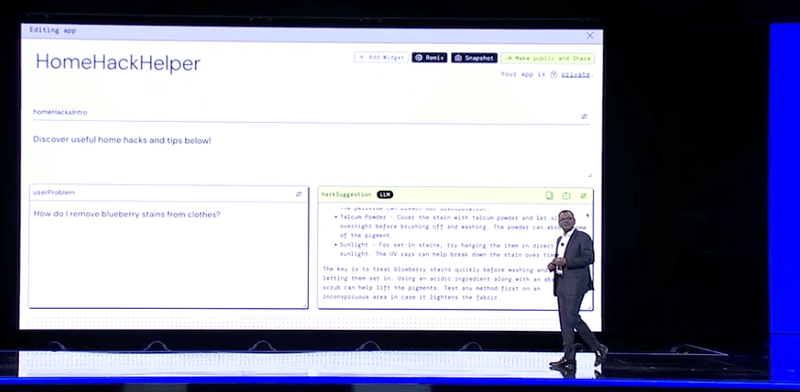
アプリ開発にはAWSのアカウントは必要なし。

ビルドボタンを押し、アプリの機能の概要を入力

複数のプロンプト技術を比較して最も適切なエンジンを選択できる

チャットボット、などのLLMベースのWidgetも追加可能

チャットボット経由でファウンデーションモデルを比較して最適なモデルを選択できる

完成したアプリはインターネットに公開する事ができる。
この記事が気に入ったらサポートをしてみませんか?