
AWS re:Invent 2023参加報告(前編)ーAWS re:Invent 2023で感じた生成系AIの盛り上がり

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でシステム開発を担当している小笠原啓です。
ラスベガスで開催されたAWS最大のグローバルカンファレンス「AWS re:Invent 2023」に参加しました。
本記事では、AWS re:Invent 2023 参加報告として本記事と次回で2回に分けて、興味深かった発表を紹介したいと思います。
記事を読んで、カンファレンスや研究内容への興味、また弊社への興味を持っていただけたら幸いです。
AWS re:Invent 2023について
AWS re:InventはクラウドプラットフォームのトップシェアであるAWSの世界最大のグローバルカンファレンスです。
2023年は11月26日から12月1日まで米国ラスベガスで開催されました。
現地の参加者だけでも50,000人を越え、セッションは2,000以上が行われる、とても大きなカンファレンスです。
最新機能の発表や、グローバルでのベストプラクティスが共有され、基調講演をはじめ、金融機関の登壇も多いカンファレンスとなっています。今回は、そのなかでも話題が豊富であった生成系AIについて紹介いたします。
生成系AIは話題の中心
AWS re:Invent 2023でも生成系AIは話題の中心であり、AWSのCEOであるAdam SepliskyのKeynoteでも生成系AIが多く取り上げられました。
現地参加をしていると、参加したセッションや会場の雰囲気からre:Inventの参加者たちの生成系AIに対する興味、感心の高さを感じました。セッション参加者のなかには「とにかく生成系AIをキーワードにセッションを検索して予約した」という方もいるほどでした。
私は複数の生成系AIが関連するセッションに参加しましたが、いずれのセッションでもwalk-upというキャンセル待ちのような仕組みを利用して参加を試みる人たちが開場前に長い列を作っていました。
AWSも利用者の期待に応えて、生成系AIに関連する多くのサービスを提供しています。AWSはそれらのサービスをGenerative AI Stackという3つの階層で整理しています。

from AWS re:Invent 2023 - Keynote with Dr. Swami Sivasubramanian
一番下の階層はインフラストラクチャです。機械学習専用チップのTrainiumやInferentia、また分析基盤のSagemakerなどがこの階層に含まれます。
中間層は生成系AIをアプリケーション開発にもちいるためのサービスであるAmazon Bedrockを含みます。
そして最上位の階層はAWSが生成系AIを利用して開発したサービスのAmazon Qや Amazon CodeWhispererを含みます。
以降では、個人的に印象に残ったAmazon Bedrockおよびインフラストラクチャに関するサービスと発表内容を中心に紹介します。
複数のモデルを利用できることがAmazon Bedrockの強み
生成系AIを利用したアプリケーションを開発する場合、多くは Amazon Bedrockを利用します。
Amazon Bedrockの特徴の1つは、多数のFoundation Modelが使えることです。
Amazonが提供するAmazon Titanをはじめ、Metaが提供するLlama、Anthropicが提供するClaudeなどが利用できます。
それらの中でもAWSはClaudeの発展に大きな期待を寄せているように感じました。
AWSのCEOであるAdamのKeynoteには、AnthropicのCEOであるDario Amodeiが登場し、近日中に Claude2.1 がAmazon Bedrockで利用できるようになることを宣言しました。
また私が参加したWorkshopではTitanではなくCladue2 を使うものもありました。
AdamのKeynoteでの宣言を聞き、自社独自のモデルに拘らず、問題解決に適切な方法を提供するというAWSの柔軟な姿勢を感じるとともに、Claudeに対する期待の大きさを感じました。

from AWS re:Invent 2023 - CEO Keynote with Adam Selipsky
また複数のFoundation Modelを利用できる点は、競合サービスといえるAzure OpenAIと異なります。
Azure OpenAIではGPT4という強力なFoundation Modelが利用できます。
2024年2月現在、マルチモーダル対応のモデルも利用できるようになるなどAzure Opne AIの進化も素晴らしいものの、GPT4以外の選択肢では、利用料金やTokenLimitの異なる同種のモデルを選択するぐらいの余地しかありません。
そのためAzure OpenAIでは、強力なFoundation Modelを問題に合わせて利用することが重要となります。
一方、Amazon Bedrockでは利用者は複数のFoundation Model中から任意にモデルを選択できます。
モデル選択ができることにより独自の課題に適したFoundation Modelを選択でき、生成系AIを自社の業務に活用する可能性が広がります。
そのため、問題解決に最適なFoundation Modelを探すような段階においては、Amazon Bedrockを利用する利点は大きいのではないでしょうか。
利用者に多くの選択肢を提供するというAmazon Bedrockの強みに磨きがかかることを、今後も期待しています。
RAGアーキテクチャを通じた生成系AIの利用促進
AWSのデータとAI分野におけるバイスプレジデントである、Dr. Swami SivasubramanianのKeynoteでは、多数の生成系AIに関連するサービスが発表されました。
サービス発表については、多数のデータストレージサービスでVector Searchの機能が提供されることが発表され、RAGアーキテクチャへの対応を強化するAWSの意図を感じました。
例えばAmazon Bedrockから利用できるVector Database としてAmazon Auroraなどが利用できることが発表されたほか、OpenSearch Service、DocumentDB、DynamoDB、RedisでもVectorSearchが利用できることも発表されました。

from AWS re:Invent 2023 - Keynote with Dr. Swami Sivasubramanian
ここで少しだけRAGについて説明します。
RAGとは「Retrieval Augmented Generation」の略語で、生成系AIを用いたアプリケーションの構築に利用されるアーキテクチャの1つです。
そしてRAGはFoundation Modelの知識不足を補完するために用いられます。例えば、社外秘情報など一般に公開されていない情報をFoundation Modelは学習していません。
そのような未学習の情報を必要とする回答や作業の代行を求めても、Foundation Modelは対応ができません。また、幻覚(ハルシネーション)といわれる事実と異なる回答をする場合もあります。
この問題を解決するために、下記の図のようにpromptに関連する情報をナレッジベースから取得、Foundation Modelに渡すことで不足した情報を補います。そのうえでFoundation Model にoutputを生成させる方法が「RAG」です。
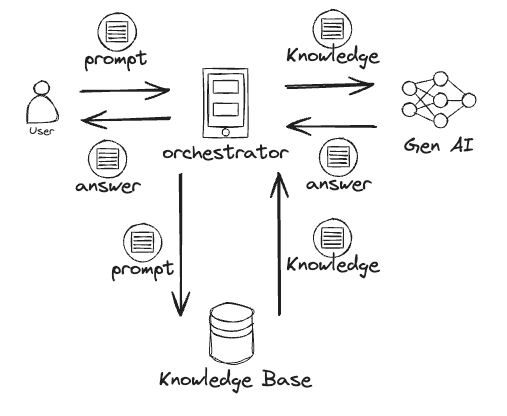
このRAGアーキテクチャにおいて、Vector Searchはナレッジベースからナレッジを検索する際に頻繁に用いられます。
Vector Searchは、promptとの類似度が高い結果を取得できるという特徴を持ち、全文検索では不可能なナレッジの取得を実現する方法です。このためRAGにおいて検索能力の強化を目的としてVector Searchは用いられます。
Vector SearchがAWSの既存のデータストレージで利用可能になれば、データストレージの既存の利用者は保存している情報を生成系AIで活用しやすくなります。
またRAGアーキテクチャを利用したアプリケーションを簡単に構築するサービス「Knowledge Base for Amazon Bedrock 」も発表されています。
本記事ではサービスの詳細は割愛しますが、興味のある方はぜひリンクからサービス内容をご確認ください。サービスの利用方法のほか、RAGアーキテクチャそのものへの理解も深まるドキュメントが提供されています。

from AWS re:Invent 2023 - CEO Keynote with Adam Selipsky
RAGは、モデルをpretrainし、fine-tuningせずに生成系AIを業務に活用するための有効な手段です。このため生成系AIを用いる場合に最初に検討されるアーキテクチャと言えます。
さまざまなデータストレージがRAGで多く用いられるVector Searchをサポートしたことをはじめ、RAGアーキテクチャを採用したアプリケーションの構築を助けるサービスを強化したという点に、RAGの活用を通じて生成系AIの利用を促そうとするAWSの狙いを感じます。
なおAWSには「Amazon Kendra」というEnterprise Searchに位置づけられる検索サービスがあります。
今回のre:Inventではあまりアップデートの情報がありませんでしたが、RAGの機能強化を考えると Amazon Kendraの今後の発展にも期待しています。
インフラストラクチャの強化
インフラストラクチャ層での注目のサービスは、「Amazon S3 Express One Zone」という新しいS3のサービスです。

from AWS re:Invent 2023 - CEO Keynote with Adam Selipsky
S3は耐障害性に優れ、分析業務においてもデータの保存に最適なオブジェクトストレージです。
今回の発表されたExpress One Zone はそのS3において、ハイパフォーマンス ストレージクラスに位置づけられるものとなります。
1桁ミリ秒でのアクセスを可能にする一方、通常のS3に対して50%ものコスト削減が見込める機能とされます。このストレージクラスはSageMakerやAmazon EMRなどの分析サービスから利用することができ、機械学習のモデルの構築にも利用することができます。
生成系AIを用いたアプリケーション開発においても、自社でpretrainやfine-tuning を行い、Custom Modelを構築・利用することも増えてくるでしょう。
自社での構築を検討する際、Custom Modelの構築にかかる時間、金銭的な費用が課題となってきます。
AWSを利用してモデルを構築する場合、費用の大半は利用している計算リソース、EC2インスタンスの利用時間に基づいて決まります。このためその利用時間を短くすることは、Custom Model構築の費用の削減につながります。
課題となる費用の解決策として、今回発表されたS3 Express One Zoneを利用することが挙げられます。
S3 Express One Zoneを利用により、学習データの読み込みが高速化され、それに伴いEC2の利用時間も短縮され、ひいてはCustom Model構築に際する費用削減が期待できます。
またAWSにはすでに学習用のチップとしてTrainium、推論用のチップとしてInferentiaが提供されています。
今回のre:Invent 2023にて、学習チップの「Trainium2」 が新たに発表されました。

from AWS re:Invent 2023 - CEO Keynote with Adam Selipsky
Trainium2は、機械学習アクセラレータと呼ばれ、100Billion以上のディープラーニングの学習用に最適化されたチップです。従来のTrainium1に比べて4倍高速に動作し、エネルギー効率も2倍になっているとされます。
このTrainium2が搭載された新たなEC2インスタンスのTrn2インスタンスは今後発表予定です。
このようにFoundation Modelの利用にとどまらず、Custom Modelの構築に関連する技術も進化しています。AWS上での生成系AIの活用はますます進んでいくことを実感しました。
ユースケース探しの旅がつづく
今後もAWS上での生成系AIに関連するサービスは進化していくことが期待できます。
個人的には生成系AIを利用するAmazon Bedrockのサービスの進化のほか、Custom Modelの構築と利用を見据えたインフラストラクチャ層の機能強化に特に期待をしています。
一方で、利用者である我々もこうした進化を享受するために「生成系AIをどのよう活かすか」というユースケースを見つける必要があります。
re:Inventのセッションの中には「Beyond chatbots」と銘を打たれたセッションもありました。
生成系AIを「質問に答えてくれるChatbot」としてだけ利用する状況を打破する必要性を訴えるセッションであったと思います。
How to deliver business value in financial services with generative AI というセッションでは、金融業界の企業がどのよう生成系AIを用いてビジネス価値を実現したかという内容を共有しています。
事例と挙げた会社で、デジタルアシスタントに既存の作業を代行させ、従来の作業コストを大幅に軽減したなどの成功事例が紹介されています。

from AWS re:Invent 2023 - How to deliver business value in financial services with generative AI (FSI201)
またAWSでは、生成系AIのユースケースを紹介する専用サイトも設けています。
ユースケースなどの情報を活かし、ビジネス価値を最大化するような生成系AIの利用方法を探し当てることが、利用者に求められています。
私自身、生成系AIをプログラミングの補助で利用したことがありますが、コードの提案、既存コードの解説やテストコードの生成に活用することで明らかにプログラミングの質が向上したことを感じています。
今後はさらに、システム開発に関連する各種ドキュメント、システム構成図やAPIの設計図、ユーザーマニュアルの作成などに活用したいと思っています。
今後、マルチモーダル対応で、且つToken Limitが大きいFoundation Modelを利用すれば、これらのドキュメントをコードの変更に合わせて自動更新することもできるのではないか、と期待をしています。
今後も積極的に、生成系AIを学び活用していきたいと考えています。
最後までご覧いただきありがとうございました。
関連記事
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちらにお願いします。
Technology & Development Division
Dev2 Lead / Senior Engineer
Kei Ogasawara