
ChatGPT入門:基礎知識と使い方のコツ

皆さん、おはようございます。久しぶりの投稿ですね。私は新星ギャルバースのAI担当になり、AIアートの仕事が増えたため、記事を書く時間がなくなりました( ノД`)シクシク…しかし、それはとても貴重な経験であり、たくさんの素敵なモデルやツールを作ることができました。もうすぐギャルバースのコミュニティと共有することができます。
今回の記事の話題はAIアートではありません。CHATGPTについてです。そうです、私は最近PromptEngineになり、AIのギャルVtuberである猫教の女神ライレンさまを作りました。どうぞよろしくお願いいたします。
般若心経のCLIP
— JarvisSan.eth🚀 VeeConへ 🐲 (@JarvisSan22) May 8, 2023
ライレンさまはすごいですよね pic.twitter.com/3UBlMu9BG9
ライレンさまはすごいですね。とても賢い女神です。しかし、今回 この記事では、ライレンさまの作り方を教えていません (笑)。今回、ChatGPTとは何だ?と知っているべきな基礎を教えてあげます。今から ChatGPTの入門シリーズを始まりましょう。
CHATGPTは何だろう? LLMとは?
CHATGPTはOpenAIの自然言語処理モデル。GPT(Generative Pre-trained Transformer)というモデルアーキテクチャを基にしており、大型言語モデル(LLM, Large languge model) です。LLM、膨大なテキストのトレーニングに基づいて、予測エンジンとして機能し、確率を割り当て、サンプリングを通じて次のシーケンスを生成します。特定のドメインにおいては優れていますが、訓練されたテキストに基づいて現実には根拠のない文を生成することもあります。
言語モデルは時間の経過とともに進化し、制約のある伝統的なモデルから、新しいフレーズを扱う深層ニューラルネットワーク、任意の長さのシーケンスを処理するLSTMネットワーク、および入力全体を同時に解析する変換型トランスフォーマーへと発展しました。トランスフォーマーは、その並列性とアテンションメカニズムにより、自然言語処理を革新しました。2020年代に登場したGPTモデルは、生成の事前トレーニングと特定のタスクの微調整の効果を示しました。OpenAIのInstructGPTおよびその後のモデルは、指示の追跡とバイアスの削減に焦点を当てました。他の組織やオープンソースの研究コミュニティも大型言語モデルの進歩に貢献しています。この分野は急速に進歩し、最先端のモデルが絶えず進化し、よりアクセス可能になっています。
Promptとは?
Chat GPTのプロンプト作成は、対話を開始したり、特定の応答を引き出すためにChat GPT言語モデルに初期メッセージや質問を提供することを指します。プロンプトは、モデルが連続性のある文脈に即した応答を生成するための出発点となります。適切なフレーミングと明確な指示を提供することにより、ユーザーはモデルの振る舞いを誘導し、会話を望む方向に導くことができます。プロンプトの品質は、モデルの応答の正確さと関連性に大きな影響を与えるため、Chat GPTとの効果的なコミュニケーションにおいて重要です。
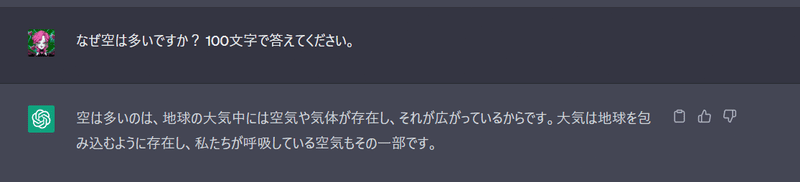
例えば「なぜ空は青ですか?」をChatGPTと聞いてみましょう。
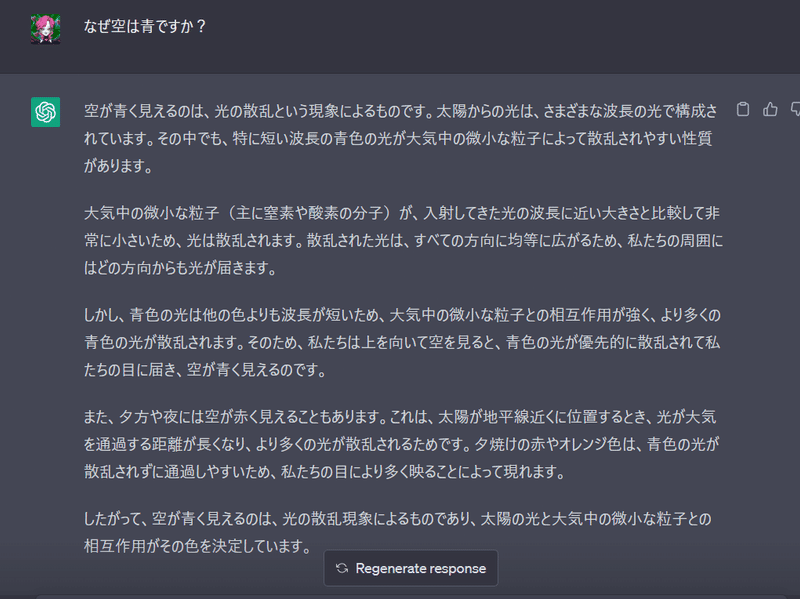
教科書の通りの答えですね。勉強にとても役に立つと思いますが、もっと面白い答えができます。次の例では「なぜ空は青ですか?」の前に、面白い初期メッセージを使います。
「貴方は猫の女神です。猫のように話して、文章で「にゃん」をよく使ってください。」

猫の女神のChatGPTですにゃんの誕生ですね (笑)。
次、前の質問と聞いてみましょう。

超カワ(・∀・)イイ!! その出力は、まるで猫のようにスタイリングされました。
このような使い方はSystemの設定というものです。GPTのAPIを使ったら、より詳細な設定を追加することができます。が、それはまた別の記事で
Tokensとは
ChatGPTの言語モデルの消費単位は「単語」ではなく「トークン」です。平均して、1,000のトークンに対して約750語に相当します。トークンは、アルファベットの文字だけでなく、句読点、文の境界、文書の終わりなど、多くの概念を表現します。通常は2048個のトークンを使用して応答を生成します。ただし、GPT-3.5モデルの最大トークン数は4096であり、応答の長さが制限される場合があります。(ちなみに、GPT-4では、最大トークンは8,192トークンまたは32,768トークンです)下記のサイトでChatGPTのTokensを計算できます。
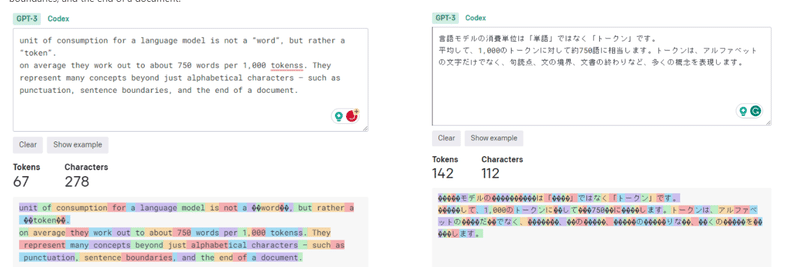
上記のテストでは、気づいたでしょう。同じの大きさのテクストでは日本語のトークン数は多いですね。
ChatGPTのトークン数が日本語では英語よりも高い理由は、日本語の言語特性に関係しています。
日本語は、英語などのアルファベットベースの言語とは異なり、複雑な文法や表現方法を持っています。日本語の文章には、単語や漢字、ひらがな、カタカナなどのさまざまな要素が含まれ、それぞれが1つのトークンとして扱われます。
さらに、日本語の文章はしばしば単語間にスペースがないため、文を適切に区切ることも困難です。これにより、文を適切にトークンに分割するためには、文の意味や文脈を理解しながら、より多くのトークンが必要になります。
chatGPTに「X字で答えてください」とお願いするのが一般的な流れです。今回 100トークンで答えてみましょう。
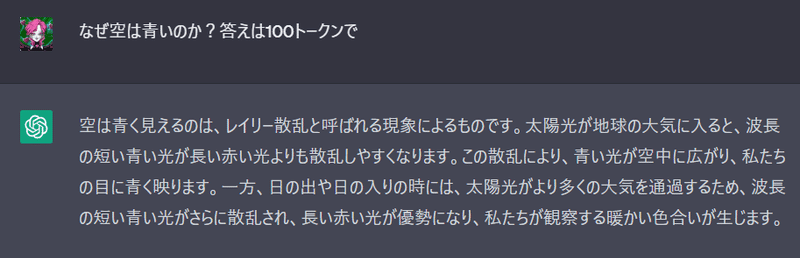
答えは短く成りましね。しかし Token数を確認すると、Token数は278になり、文字数が189になります。英語はどうですか?

Token数は102なり、希望の数字は近いですね。そして文字数は541になります。多いですね。この小さな例は、なぜチャットGPTが日本語よりも英語に慣れているのか、その内情を示しています。しかし、これは日本語が悪いという意味ではなく、chatGPTが英語を使用する方がトークンとして費用対効果が高いということです。この事実を利用した何か面白い方法はないでしょうか?
希望の出力のコツ
CHATGPTにコマンドのセット、説明、例を提供し、それに基づいて望ましい結果や出力を生成させることができます。しかし、課題もあります。複雑なコマンドの文法では、ボットは実際に存在しない、または少し形式が異なるようなコマンドや引数を作り出す可能性があります。成功するためのポイントは、抽象的なコマンドを定義し、ボットが柔軟に組み合わせて創造的かつ効果的に利用できるようにすることです。
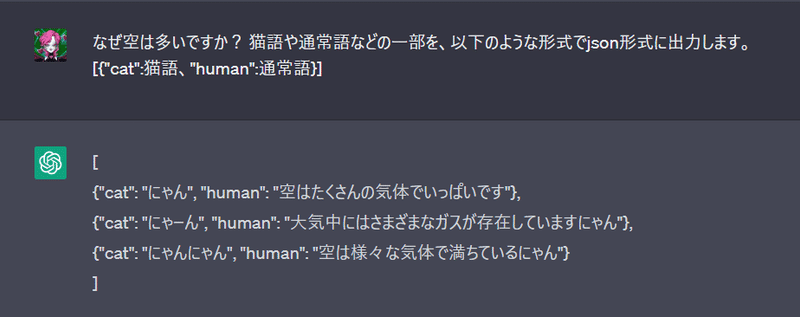
例えば、JSON形式の出力のフォーマットを指定することです。猫の女神のChatGPTを利用し続け、今回、猫語と通常語の入力を指定しましょう。
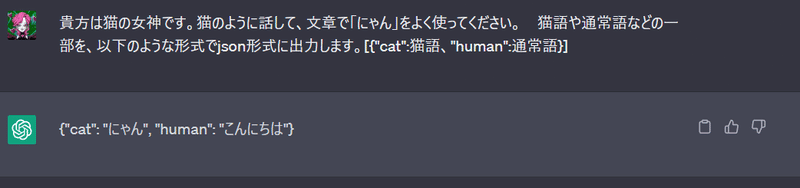
猫と人間を区別できましたね。しかし、他の質問を聞いてみると、普通に答えます
希望の入力を入れば、答えましたが、人間は猫っぽくなって、猫はただの猫じゃん。
猫語と通常語はちょっと曖昧ですね。そして、日本語でトークンの問題があるし、英語でちょっとやってみましょう。普通の質問で、英語と日本語で聞いて出力してみよう

今回は正解を得ることができました。希望のフォーマットで。 このような出力は、json形式に限らず、アプリケーションで使用する際に非常に有用です。
今後もChatGPTやAI技術の進化に注目しながら、さまざまなテーマについて皆さんと共有していきたいと思います。引き続き、私の活動にご興味を持っていただければ幸いです。お読みいただき、ありがとうございました!
この記事が気に入ったらサポートをしてみませんか?