強化学習 と 深層強化学習 の 解説

JDSC データサイエンティスト 伊藤泰輔

強化学習
強化学習は、ゲームの攻略、ロボットの制御、自動運転、物流の最適化などに使われるAIです。そして、これはAIが迷路の進み方をしている様子です。
動画を見ると、AIは、ゴールを探して行ったり来たりと、試行錯誤をしています。そして、次第にゴールまでの道筋を学習していく様子が見てとれます。
AIは、Qテーブルという表の数値(Q値)を学習しています。
行動が最適かどうかを知るには、その状況における行動の価値を計算する、というわけです。これをQ値と言います。
Q値(行動価値)が高い方向に進んでいくと、目的地(ゴール)にたどり着けることになります。

Qテーブルの数値は、AIが学習するにつれて変わっていきます。
学習とは、Q値の値を書き換えていくことです。
最初は下図のように、どちらに進んでよいかわからない状態なので、AIはランダムに行動します。そして情報を集めながら、Qテーブルの値を書き換えていきます。Qテーブルの数値が全体的に正しくなれば、AIは確実にゴールにたどり着けるようになります。

動画の仕組み
ここで、改めて動画の仕組みについても少し解説しておこうと思います。
動画では、ピンク色の〇(エージェント)が動いているように見えましたが、これは、静止画をパラパラ漫画のように動かすことで動いているように見えます。

Q値の更新式
強化学習を勉強されているかたのために、Q値の更新式について解説します。数式が苦手な方は、この部分は読み飛ばしていただいて結構です。
強化学習の勉強をされているかたは、強化学習の本などを見ると、以下のような「Q値の更新式」を目にすることがあるかと思います。
Q値の更新式


〇ポイント
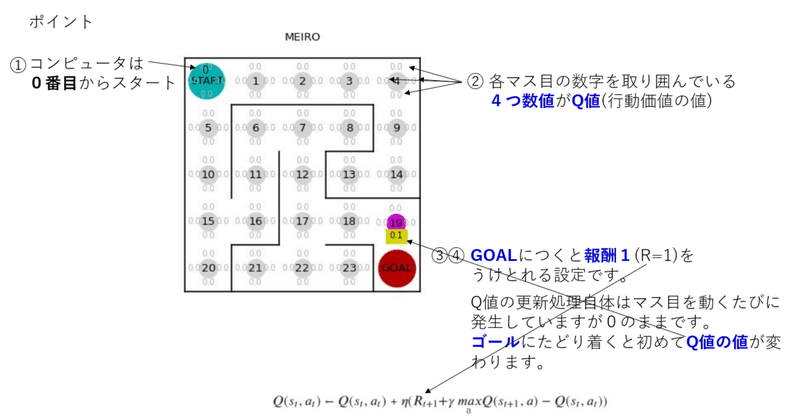
①コンピュータは、0番目のマスからスタートします。
②各マスの数字を取り囲んでいる4つの数値がQ値(行動価値)です。
③Q値の更新処理自体は、エージェント(ピンクの〇)が動くたびに行われます。
④Q値の更新式において、rはRewardで報酬を表していて、ゴールにたどりつくと報酬1を受け取れる設定になっています。
エージェント(ピンクの〇)がゴールにたどり着くまでは、Q値は0のままです。ゴールで報酬1を受け取ることで初めて、Q値は更新されます。
これを踏まえて、もう一度、動画を見てみましょう。
エージェント(ピンク色の〇)がゴールにたどり着いた瞬間に、Q値の値が変化している様子がみえると思います。
以前の話ですが、私自身、数式を見ながら考えていて、たぶん、このように動くのだろうなとは想像したのですが、いっそのことプログラムを書き換えて自分の目で確認してみようと思い立ち、作ってみた動画です。こうしたことを踏まえたうえで動画を見直していただけると、既に強化学習を勉強されているかたにも、新たな気づきがあると思います。
深層強化学習
では、深層強化学習に進みましょう。
これは、breakout(ブレークアウト)というブロック崩しのゲームです。
これは(強化学習ではなく)深層強化学習のモデルで処理しています。
いわゆるディープラーニングのモデルです。
深層強化学習のAIが、ボールをきれいに打ち返しています。
人工知能がゲームをできるなんて面白いですね。そしてうまいです。
では、どのような仕組みで、このことを実現しているのでしょうか?
解説していきたいと思います。
深層強化学習のモデルは、「画像のピクセル値の数値」を入力して、
「左に動くべきか・右に動くべきかの数値」を出力しています。
深層学習と深層強化学習の比較
深層学習と深層強化学習を比較してみましょう。


深層学習の画像認識AIでは、画像データを読み込んで、シマウマの確率を出力しています。
それに対して、深層強化学習のゲームAIの場合には、ゲーム画面のピクセル値のデータを読み込んで、「左に動かすか、右に動かすかの数値」を出力するように学習しています。
breakout(ブロック崩しゲーム)の場合、エージェントは、下にあるバーです。ボールを落とさないように打ち返します。
報酬は、ゲームの得点です。
画像認識AIも深層強化学習も、ニューラルネットワークで処理している部分は同じような感じです。
深層学習(教師あり学習は、正解である教師データを、人間が作成して与えましたが、深層強化学習では、AIが自ら探索し、報酬を得られた得られなかったという情報を集め、そこから正解である教師データを計算して自ら作成していきます。
深層学習と深層強化学習の違いは、「学習の枠組み」の違いとも言えます。
改めてbreakoutの話に戻りましょう。
深層学習のモデルが各場面・各場面で出力する4つの数値は、以下の順番に対応しています。(コンピュータは0番目から数えます。)
0番目 : 何もしない
1 番目: ボールを発射 (=スタートボタンのこと。ボールが落ちてしまったときに再開するために使います)
2 番目: 右へ移動
3 番目: 左へ移動
そして、ブロック崩しの動画も、1秒間に5枚から30枚程度の画像(フレーム)をパラパラ漫画の要領で高速で動かすことで動いているようにみえます。
深層強化学習AIも、1枚1枚の画像ごとに左に動くか右に動くかを判断しています。それを高速につなげることで、ボールを打ち返しているようにみえるのです。簡単に言うとこういうことです。
(モデルによっては、直近何枚分かの画像をもとに、次の行動を決めるといったように時系列の要素を加味しているモデルもあります。)

なぜ強化学習ではなくて、深層強化学習か?
図の中でも少し触れていますが、迷路の場合、マスの数は24個(24マス)なので、Qテーブルは24行ですみますが、ゲーム画面の画像は、ピクセル値という数字の配列なので、ボールの位置やブロックの状態などによって、膨大な組み合わせができてしまいます。
強化学習だとQテーブルが膨大に長い行数になってしまし、実装できなくなってしまうため、深層強化学習を使います。
画面の画像という高次元のデータを、ニューラルネットワークによって、次元圧縮する、という使い方をします。
ニューラルネットワークは、ゲームの局面という縮約した情報(特徴量)を抽出しています。このことが「状況を認識する」ということに対応しています。

パックマン
では、最後に、よりリアルなゲーム環境として、パックマンを深層強化学習で処理している様子をお見せします。
深層強化学習のAIが、パックマンのゲームをしています。
(厳密には、OpenAIのMsPacmanは、有名なパックマンの後継のゲームなのですが、ゲーム自体はパックマンゲームと非常によく似ています。)
(そして、このブログに載せられる動画の容量が少ないため、時間が短いですが、 是非、ご覧ください。)
ブロック崩し(breakout)では、バーを左右に動かすことができましたが、パックマンは、上下左右に動けるので、0 上、1右、2下、3左 のように出力の選択肢を増やしたモデルですが、基本的な仕組みは、同じような感じです。

終わりに
深層強化学習AIの内部のメカニズムについて、少しイメージができましたでしょうか?
強化学習は、ゲームAI、ロボット制御、自動運転、物流・倉庫の最適化など現実に使われ始めているAIです。
次回の更新は6月上旬を予定しています。もう少し深層強化学習の解説を行う予定です。
お楽しみに。
JDSCではデータサイエンスの力によって日本を変えたい仲間を募集しています!ご興味を持ってくださったらカジュアルにお話しましょう!(by tech blog 編集部)
この記事が気に入ったらサポートをしてみませんか?