APIを使ってみよう(Google Vision API)

この記事で、GoogleドキュメントのOCR機能を使いました。
でも、Googleドライブにアップして、Googleドキュメントで開く、というのを毎回実行するのは手間です。
画像を渡したら、文字認識した結果だけ返してくれればいいんだけど。
もっと自動でできないもんかね?
という感じに、プログラムの「一部機能だけが欲しい」といったことはありませんか?膨大な機能の中の、一部だけが使いたい。付随する機能はいらん、と。
そこで、プログラムの提供側が「こんな風に呼び出してくれたら、一部分だけ実行してあげるよ」と、用意してくれるのがAPIです。※API→「Application Programming Interface」
GoogleドキュメントのOCR機能を切り出した部分のAPIは、
Google Vision APIとして提供されています。
ドキュメントも提供されており、使い方とサンプルコードもあるので、使ってみましょう。
書いてある通りにやってれば、そんなに困ることはありません。
(英語はがんばって読む。)
文字認識させて、固まりの単位で文字として出力。合わせて、位置情報も取得。ということをやってみます。
この画像を入力にして。。。

このコードを書いて。。。
static void Main(string[] args)
{
Environment.SetEnvironmentVariable("GOOGLE_APPLICATION_CREDENTIALS", 認証用ファイルのパス, EnvironmentVariableTarget.Process);
// Load the image file into memory
var image = Google.Cloud.Vision.V1.Image.FromFile(画像ファイルのパス);
DetectDocumentText(image);
}
private static void DetectDocumentText(Google.Cloud.Vision.V1.Image image)
{
ImageAnnotatorClient client = ImageAnnotatorClient.Create();
TextAnnotation text = client.DetectDocumentText(image);
//ページ単位の処理
foreach (var page in text.Pages)
{
//ブロック単位の処理
foreach (var block in page.Blocks)
{
//ブロックの位置情報を取得
string box = string.Join(" - ", block.BoundingBox.Vertices.Select(v => $"({v.X}, {v.Y})"));
//ブロック内の全文字をつなげる
var value = string.Join("", block.Paragraphs.SelectMany(p => p.Words.SelectMany(w => w.Symbols.SelectMany(s => s.Text))));
//認識結果を表示
Console.WriteLine($"Block {block.BlockType} at {box} word {value}");
}
}
}
実行!
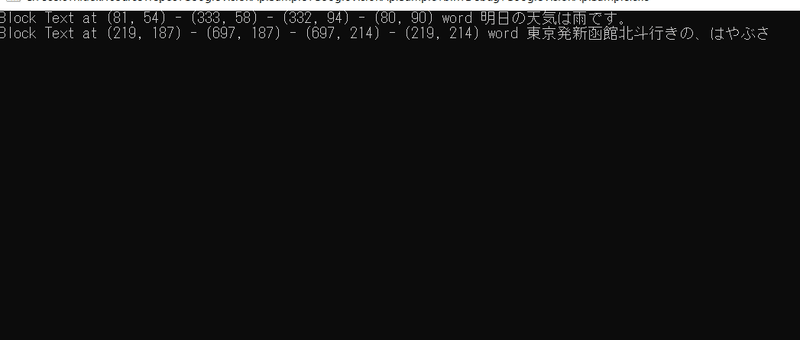
Block Text at (81, 54) - (333, 58) - (332, 94) - (80, 90) word 明日の天気は雨です。
Block Text at (219, 187) - (697, 187) - (697, 214) - (219, 214) word 東京発新函館北斗行きの、はやぶさ
はいい感じ。
位置情報も取れるのなら、あんなことやこんなことに使いようはありますね。
いろいろ使ってみよう。。。
この記事が気に入ったらサポートをしてみませんか?