[Excel Tips] Power pivot からワークシートへデータを取り出して動かす

Excel の Power Pivot は手軽に大きなデータを取り扱うことができるツールですが、これだけで完結させるにはなかなかテクニックが必要です。そこで、Power Pivot からデータを取り出してワークシートで使うための小技を紹介します。
なお、ここでは Power Pivot 自体の解説はしませんが、ご存じない方は、Excel のピボットテーブルの後ろに本気のデータベースが配備されているツールと思えばいいです。本気のデータベースなので、Excel の最大行数百万を超えるデータを入れてピボットテーブルを動かすことができます。Excel 2016 以降では標準装備されています。
サンプルデータ
サンプルデータは、レンタルバイクの利用履歴データです。と言っても実際のデータではなくて、乱数シミュレーションによって仮想的に作ったデータです。データの作り方についてはまたいつか。このデータには、自転車が拠点を離れた時刻、戻ってきた時刻、拠点のid、利用分、利用時間、利用金額が記されています。各拠点は場所によって保有台数と利用頻度に違いがあります。このデータを Power Pivot に入れます。
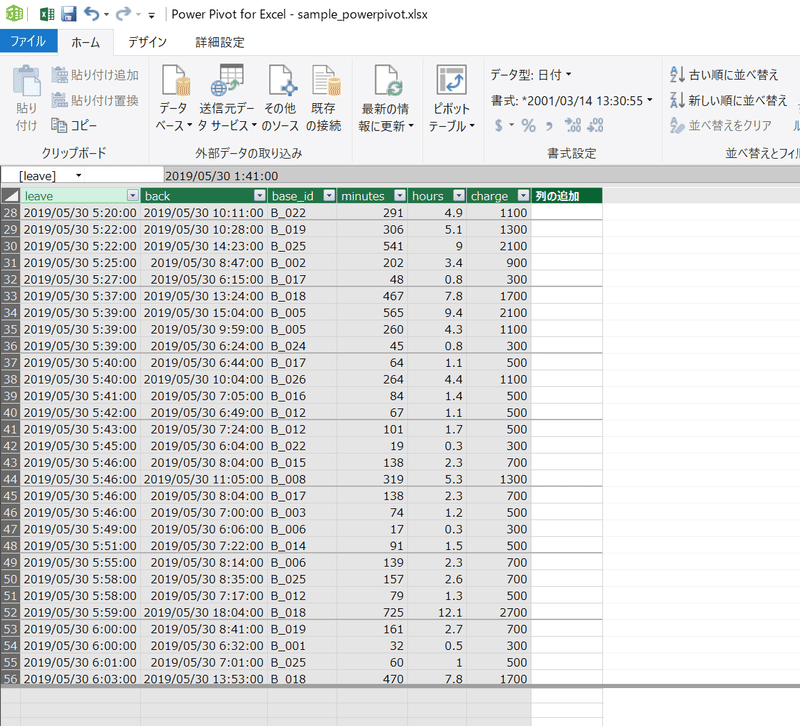
なお、サンプルデータはサンプルなので約4000行程度しか作りませんでしたが、実際には数百万~数千万あっても Power Pivot は動いてくれます。
ピボットテーブルにデータを持ってくる
データの用意ができたので、次はピボットテーブルにデータを持ってきます。操作は従来のピボットテーブルと変わりません。なお、後の作業のためにピボットテーブルの左側を少しあけておいてください。
例として、利用分毎に利用者がどれだけいるかを観察しましょう。このデータには利用分が掲載されているので、利用分を縦に、利用者数(レコード数)を値にしたピボットテーブルを作ります。具体的には、ピボットテーブルのフィールドリストにて、行にminutesを、値にもminutesを入れて、値の方の「値フィールドの設定」を個数に変更します。
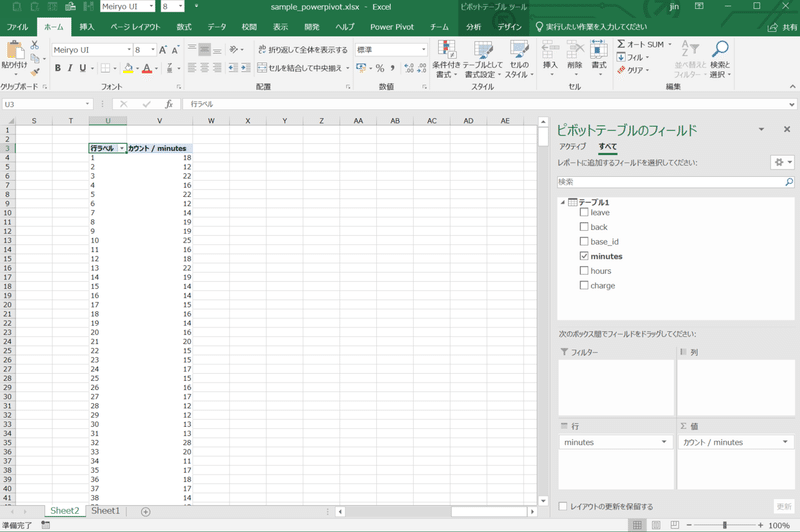
これをグラフにしようと思うと、通常はピボットグラフを挿入するのですが、

ピボットグラフは使うのがいちいち面倒で、なかなか思い通りのグラフを描くことができません。例えば今のデータですと、横軸の「分」がラベルになっていたり、そもそも分単位ではなくて10分単位にしたいとか、5分単位にしたいとか、そういう融通が利きにくい。一方で、ではこのピボットテーブルのデータをさらに集計すればよいかというと、これを値でコピペしてしまうと、「ソースを一元化すること」で書いたように、後々のメンテナンス性が失われてしまいます。
そこで、このピボットテーブルからデータを引っ張ります。
先ほどあけておいた、ピボットテーブルの左側に、まずは minutes のカラムを作り、1から1440(一日=1440分)までの数字を入れます。そしてその隣に、レコード数を書き入れる場所を確保します。二行以上確保してください。例えば例ではP列をレコード数の列にして、1分目を4行目にしています。次に、P4セルに「=」を記入してから、ピボットテーブルの値を選択(例ではV4セルを押す)して、[return]します。

すると、P4セルの中に次の式が入ります。
=GETPIVOTDATA("[Measures].[カウント / minutes]",$U$3,"[テーブル1].[minutes]","[テーブル1].[minutes].&[1]")もちろん、この数式を自分で入力してもいいのですが、ややこしいところが沢山あるので、ピボットテーブル選択で入力するのが楽です。このGETPIVOTDATA関数は、文字通りピボットテーブルからデータを持ってくる関数なのですが、このままではさっき押した場所(例ではV4)の値しか出ません。そこで、この関数に細工を施します。
関数の一番最後に、
"[テーブル1].[minutes].&[1]"と書かれている箇所があります。これがピボットテーブルのどのアイテムを持ってくるのかを決めている箇所なのですが、これは実はただの文字列で、この関数は文字列を読み取って、持ってくる値を選んでいます。そのアイテムの場所が「1」、つまり、ピボットテーブルの中の、行ラベルが「1」の箇所の値をもってこいという指示になっています。そこで、この文字列を次のように変更します。
"[テーブル1].[minutes].&["&$O4&"]"「&」は、Excelではお馴染みの文字列結合記号で、$O4はO列のデータを指しています。Oに$がついているのは、O列は絶対参照するという意味で、4に$がついていないのは相対参照です。こうすると、先ほど「1」が入っていたところがminutes列のセル参照に代わるので、あとはこの式を下方向にコピペすれば、各分についてピボットテーブルからのデータをワークシート上に取り出すことができます。

ところで、これを下の方にスクロールしていくと、ところどころ「#REF!」が現れます。例えばこのサンプルですとminutesが258の場所で最初に現れますが、これはピボットテーブルの行ラベルに258が存在しないために起こるエラーです。実際にピボットテーブルを見てみると、258が飛ばされていることがわかります。GETPIVOTDATAの関数はあくまでもピボットテーブルに表示されたものを引っ張ってくる関数なので、表示されていない場所、つまり、行ラベルが欠けているところを取りに行こうとするとエラーになります。これをピボットテーブル側で回避しようとすると、例えばピボットテーブルのオプションで「データのないアイテムを行に表示する」としてもいいのですが、今回はワークシート側で、エラー行にはゼロを与えることにします。具体的には、隣の列に
=IF(ISERR(P4),0,P4)を入れて下にコピペします。これで、分毎のレコード数集計値を、ワークシート関数を使って持ってくることができました。
繰り返しになりますが、なぜ隣にあるピボットテーブルの値を持ってくるだけでこんな面倒なことをするかと言えば、データソースの一元化、そして、「動くExcel」の準備だからなのですが、それはまたあとで。
集計単位を変更する
さて、ワークシートに持ってきて何が嬉しいかというと、ここから先はワークシート関数を自在に使って集計できる点です。今、データをざっと観察すると、分の区切りが細かすぎ、ギザギザしすぎていてよくわかりませんでした。そこで、集計する時間の単位を変えてみます。
J列に、0から10ずつ増加させる列を作ります。但し、この単位「10」を後から変更できるように、単位の値もワークシート参照にします。例では、J2に10を記入、J4には0を記入した上で、J5には
=J4+$J$2を記入して下へコピペします。J2の値を変更すれば、刻み幅が5分にも10分にも20分にも変化します。
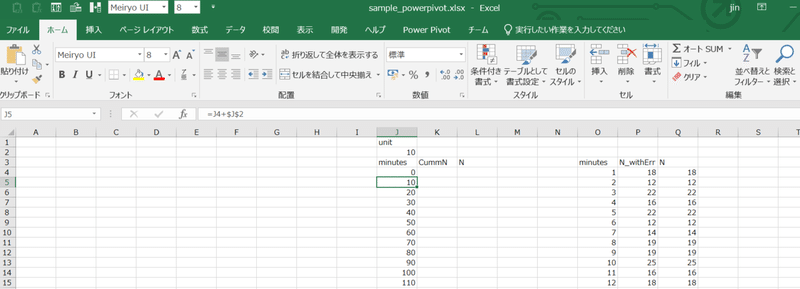
次に、「ソースを一元化すること」の中でヒストグラムを作ったときのように、Q列を集計していきます。まずは累積列を
=SUMIF($O$4:$O$1443,"<="&$J4,$Q$4:$Q$1443)で作成して、これを差分します。これで、10分毎の集計データができましたので、あとはグラフに落とすだけです。グラフもピボットグラフではなく通常のExcelのグラフを使えるので、自由度はこれまでと同じです。
なお、小技ですが、棒グラフを挿入する際には、横軸になる列の列名を削除してから選択→グラフ挿入すると、勝手に横路比べる扱いしてくれるので楽です。つまり、J3に「minutes」が書かれている状態でJ3:K292を選択して棒グラフを挿入すると、J列も値だと思って二つの棒グラフが挿入されてしまうのですが、J3を空白にしてから同じ範囲を選択、グラフを挿入すると、J列はラベルとして扱われます。その後、K列は累積値が入っている列なので、これをL列に変更します。グラフを押すと現れる紫や青のわくをマウスで掴んでずらせばOKです。
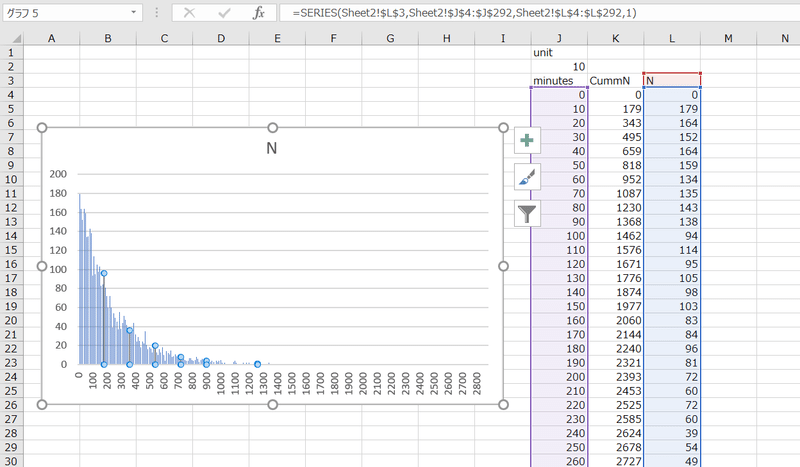
このように、グラフの中の棒の部分を一回クリックすると、どのデータを表示しているかのわくが出てきます。この枠はマウスで掴んで移動できるので、K列からL列にずらすことができます。
ここから、J2の値を動かすと、集計分の単位を動かすことができます。5分や10分ではまだギザギザ感が残りますが、20分程度にするとそこそこ見やすくなっていそうですので、20にしてみます。ここで、棒グラフの横軸だけは実は自動で変わってくれないのが不便です。そこでもう一工夫します。
F4, G4にそれぞれ次の式を入れて下にコピペします。
=IF(L4=0,NA(),J4)
=IF(L4=0,NA(),L4)そして、F3:G292を選択した後、散布図グラフを挿入します。
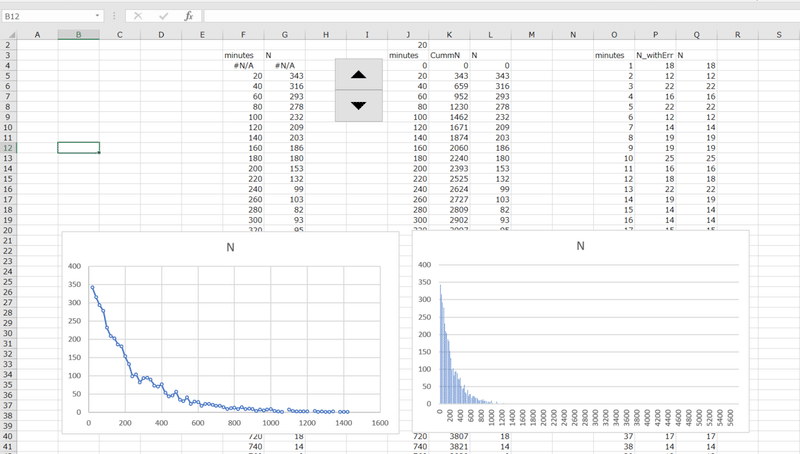
すると、集計する単位分数を変えても見かけがうまく追従してくれるグラフを描けます(左側)。件数のヒストグラムなので、本来は棒グラフで表示するのが適切なのですが、これしかないので諦めます折れ線を見ながら棒グラフを想像してください。散布図では、値がNAのところは読み飛ばすので、このように表示できるというわけです。なお、J2にはフォームコントロールでスピンボタンを挿入してみました。
さらに動かす~拠点別の可視化と切り替え
もう一踏ん張りします。
ここまで可視化できたら、次は「拠点別だとどうなっているだろう?」と思いますよね。では、拠点別データを可視化してみましょう。
ポイントは、ピボットテーブルを使っているところです。ピボットテーブルにカーソルを持っていくと、ピボットテーブルのフィールドリストが出てくるので、base_idを右クリック→スライサーとして追加を選択します。

するとスライサーが出てくるので、B_###で表示されている拠点名を押してみてください。拠点別の分数ヒストグラム(およびその散布図グラフ)が表示されます。これだけで、拠点別の可視化ができ、さらに、すべてのグラフが拠点選択の操作に連動して変化します。
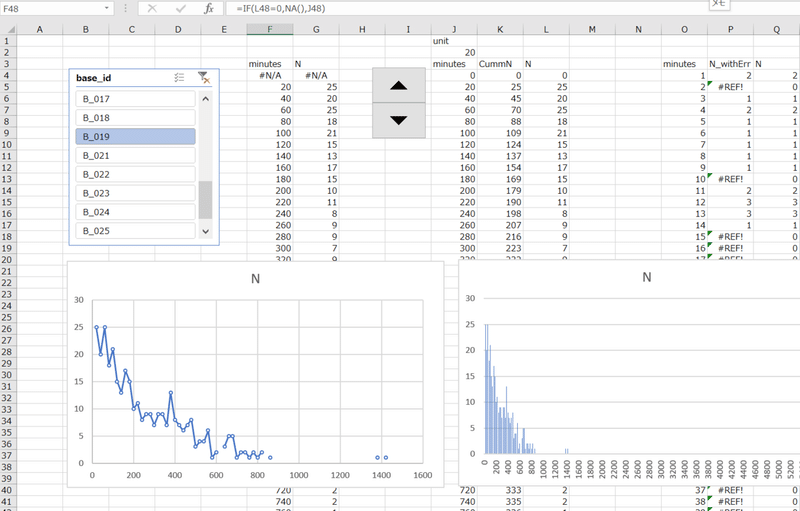
左上がスライサーです。B_019を選択すると、B_019のデータのみが集計されて表示されます。スライサーはただのフィルタで、ピボットテーブルの集計値がフィルタされて表示されると言うだけの機能です。スライサーの右上の漏斗に赤いバッテンを押せばフィルタが解除されます。
このように、ピボットテーブルのデータを、ワークシート関数を使って持ってくるようにしておくと、ピボットテーブルのデータの変化(今回はスライサーを使って変化させた)に追従するワークシートを作ることができます。スライサーは最も使えるピボットテーブルの機能なので、これを使わない手はありません。
おわりに
Excel の弱点である大量データの部分を Power Pivot に肩代わりさせて、しかしワークシート関数の便利なところも使う方法を紹介しました。やはりここでも、データエンジニアリングの基本は「データソースの一元化」と「動くExcel」です。サンプルファイルを下に貼っておきます。
この記事が気に入ったらサポートをしてみませんか?