
Nvidia GPU 環境でllama.cppを試したメモ

前準備
RTX3090 を1枚とGTX1070 1枚載せた自作のマシンでやります
DDR4のRAMを128GB以上積んでます
使うモデルは下記でwgetで落としておきました
https://huggingface.co/TheBloke/Llama-2-70B-Orca-200k-GGUF
Ubuntu22.04 上でMacと同じ環境を作っておきます
https://github.com/ggerganov/llama.cpp
nvidia-cuda-toolkitはこちらのUbuntu22.04の手順にしたがってインストールしておきました
nvcc -V でバージョンを確認しておきます
:~/git/llama.cpp$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Mon_Oct_24_19:12:58_PDT_2022
Cuda compilation tools, release 12.0, V12.0.76
Build cuda_12.0.r12.0/compiler.31968024_0ついでにnvidia-smiも確認しておきます
古いGPUもあります。RTX3090とGTX1070の2枚刺してるのでどちらも認識はされています
~/git/llama.cpp$ nvidia-smi
Sun Aug 27 14:22:02 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:17:00.0 On | N/A |
| 0% 55C P8 12W / 151W | 69MiB / 8192MiB | 11% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce ... Off | 00000000:65:00.0 On | N/A |
| 46% 59C P5 49W / 350W | 1723MiB / 24576MiB | 31% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+一応condaとかで環境も作っておきます。
condaもインストール済みの前提とします
Condaインストール
curl -sL "https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh" > "Miniconda3.sh"
bash Miniconda3.sh仮想環境の構築とパッケージのインストール
~/git/llama.cpp$conda create -n llama-cpp python=3.10.9
~/git/llama.cpp$conda activate llama-cpp
~/git/llama.cpp$python3 -m pip install -r requirements.txt
環境ができたら今回はcublasを有効化してビルドします
make clean && LLAMA_CUBLAS=1 make -jビルド時に私はエラーが出たのですが
nvcc -Vの結果当初はcuda toolkitの11.5の古いバージョンが入っていたので12.0の方を読むように.bashrcを編集しました。
下記のようにcuda-12の実行ファイルのパスをexportするようにしておきました。
# set PATH for cuda 12 installation
if [ -d "/usr/local/cuda-12/bin/" ]; then
export PATH=/usr/local/cuda-12/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
fi実行
では実行します。GPUへのオフロードのレイヤーを示すオプションは-ngl 32としてみました。
:~/git/llama.cpp$ ./main -t 10 -ngl 32 -m ./models/TheBloke/Llama-2-70B-Or
ca-200k-GGUF/llama-2-70b-orca-200k.Q2_K.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Instructio
n: Write a story about llamas\n### Response:"結果
### Instruction: Write a story about llamas\n### Response:
There once was a llama named Lulu, who lived in the mountains with her family. Lulu loved to explore and go on adventures, but her mommy and daddy always warned her to stay close to home. One day while grazing in the meadow, Lulu saw something shimmering in the distance. It was a beautiful rainbow!
Lulu couldn't resist the temptation to see the rainbow up close, so she decided to leave the meadow and walk towards it. As she got closer, the colors of the rainbow became more vivid and Lulu felt a sense of wonderment. She had never seen anything like it before!
Suddenly, Lulu heard a loud roar in the distance. It was a big, scary lion! Lulu knew that lions were dangerous animals and could hurt her, so she turned around and started to run back home as fast as she could.
On her way back, Lulu realized that she had gone too far from home. She was lost and didn't know which direction to take. She started to panic and called out for help. Her mommy and daddy heard her cries and came running towards her. They were so relieved to find their little Lulu safe and sound.
From that day on, Lulu learned the importance of staying close to home and listening to her parents' advice. She also realized that adventures can be exciting, but it's always better to have someone you trust with you. And so, Lulu continued to explore the mountain meadows, but always kept her mommy and daddy close by her side. [end of text]
llama_print_timings: load time = 4089.40 ms
llama_print_timings: sample time = 174.85 ms / 354 runs ( 0.49 ms per token, 2024.57 tokens per second)
llama_print_timings: prompt eval time = 5307.12 ms / 17 tokens ( 312.18 ms per token, 3.20 tokens per second)
llama_print_timings: eval time = 168267.10 ms / 353 runs ( 476.68 ms per token, 2.10 tokens per second)
llama_print_timings: total time = 173821.66 ms物語の続きを書いてくれました。RTX3090 の環境で2.10 tokens/s で動きました。
-ngl 80としてみましょう
~/git/llama.cpp$ ./main -t 10 -ngl 80 -m ./models/TheBloke/Llama-2-70B-Orca-200k-GGUF/llam
a-2-70b-orca-200k.Q2_K.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Instructio
n: Write a story about llamas\n### Response:"### Instructio
n: Write a story about llamas\n### Response: Once upon a time, there was a big, fluffy animal called a llama. It lived in a beautiful green field with lots of other animals like cows and sheep. The llamas had long necks and soft woolly coats that they used to keep warm in the cold weather.
One day, a little girl named Lucy went to visit the llama farm with her mommy. She saw all the llamas playing together and making funny noises. Lucy thought they were so cute and she wanted to pet one!
Lucy's mommy helped her find a friendly-looking llama and asked its owner if it was okay to give it a gentle pat. The owner said yes, so Lucy gently patted the llama on its soft woolly coat. The llama made a funny noise, and Lucy couldn't stop laughing!
After they played with the llamas for a while, Lucy's mommy took her to the gift shop where she could buy a little stuffed toy llama to remember her visit. Lucy was so happy because now she had her own fluffy friend to cuddle and play with at home.
And that's how Lucy became friends with the llamas, and they all lived happily ever after in their beautiful green field. [end of text]
llama_print_timings: load time = 5995.11 ms
llama_print_timings: sample time = 140.40 ms / 281 runs ( 0.50 ms per token, 2001.38 tokens per second)
llama_print_timings: prompt eval time = 870.07 ms / 20 tokens ( 43.50 ms per token, 22.99 tokens per second)
llama_print_timings: eval time = 48451.17 ms / 280 runs ( 173.04 ms per token, 5.78 tokens per second)
llama_print_timings: total time = 49519.01 ms結果
5.78Tokens/s まで速度があがりました
RTX3090 vram24GB 以上のGPUを搭載したゲーミングPCや同等以上の性能を持つノートPCではllama.cppを用いることでかなり実用的な速度で70Bのモデルを使用可能なことが明らかになりました。
おまけ
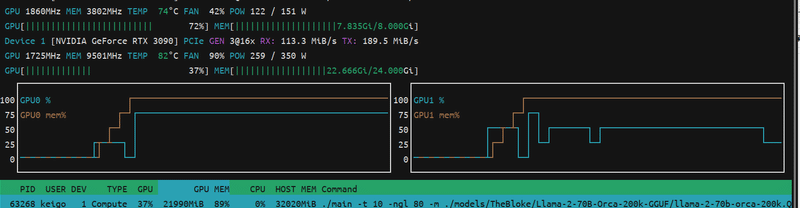
GPUのメモリは推論中100%に張り付いていました。
RTX3090もGTX1070もこれ両方使ってるっぽいですね
参考
https://kubito.dev/posts/llama-cpp-linux-nvidia/
この記事が気に入ったらサポートをしてみませんか?