k-means法とk近傍法について

今回から機械学習についても書いていこうと思います。全部を取り上げるとキリがないので自分が興味を持った分野のみを取りあげていく予定です。できる限り詳しく説明しますが、それでも抜けている所もあるのでご了承ください。
今回扱うのはk傍法とk平均法です。pythonで機械学習をやったことがある方ならkmeansだったりKNeighborsClassifierとかで使用したことがあると思います。
名前は似ていますが決定的な違いがあります。それはなんでしょう。
・k近傍法とk平均法の違い
正解はk近傍法は教師あり学習なのに対してk平均法は教師なし学習だと言うことです。k近傍法は教師あり学習の中でも分類という学習に属し、k平均法は教師なし学習のなかのクラスタリングという学習に属します。分類とクラスタリングどちらも言葉が似ていますが、違いとして正解ラベルがあるかどうかです。
例えばりんごとレモンを分けるとします。今回はりんごとレモンと正解ラベルがあるのでk近傍法を使用します。もう一つの事例をみます。例えば果物が何種類かも分からない状態があったとします。それらの中で類似した果物をグループ化するのがk平均法、クラスタリングです。
・k近傍法
ではまず先にアルゴリズムが非常にシンプルなk近傍法について紹介します。
そのアルゴリズムはデータセットの中から一番近い点(最近傍点)を見つけてくるというアルゴリズムです。機械学習のKNeighborsClassifierにはn_neighborsというパラメータがあります。これは何個のデータを参照するかと言うことを示しています。例えば1を選択した場合データセットの中から一番近い点を参照します。3つなら三つといった感じです。言葉で説明するより実際にデータを見た方が早いと思います。
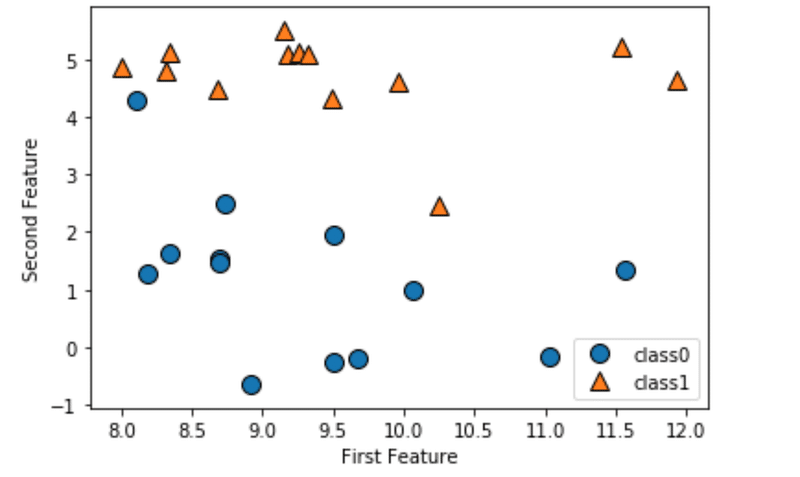
仮にデータセットが次のようにあったとします。
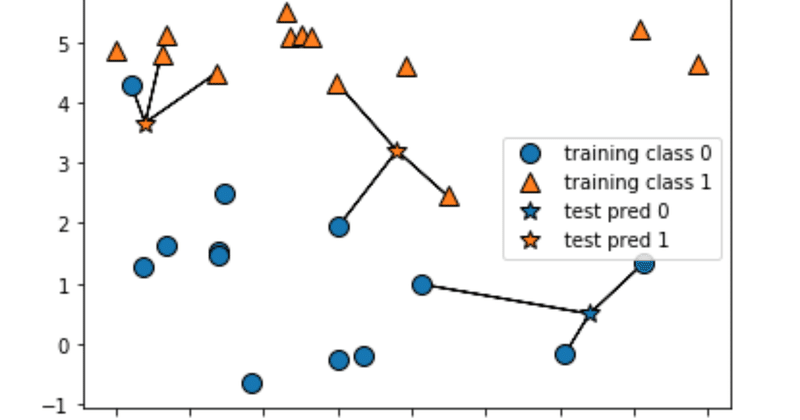
ここでn_neighbors=1と指定するとtrainデータから一番近い点を参照してくれます。
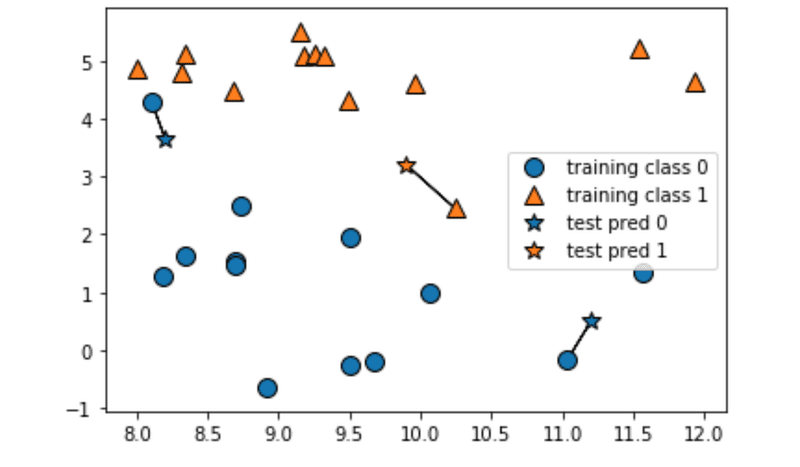
では次に3を設定してみます。そうするとtrainデータから三つの点を参照してくれます。少しデータを見ると違ったデータを参照してきているtestデータがあります。このように異なったデータを参照してきた際には多数派のクラスを選択することになります(左上のデータなら●が一つ▲が二つなので▲を採用みたいな感じ)
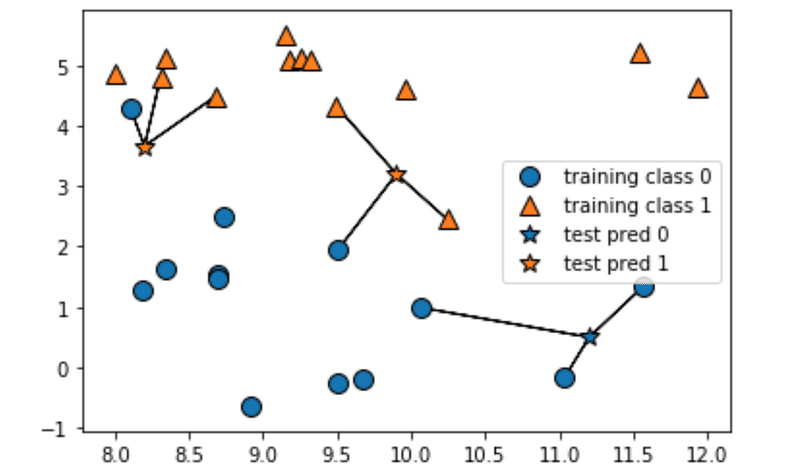
とてもシンプルなアルゴリズムですが、シンプルなゆえにデメリットも沢山あります。
・K近傍法の弱点
まず一つ目にあげるのが計算に時間がかかると言う点です。なぜなら全てのデータセットを参照して最も近い点を得ているからです。今回はシンプルなデータですのでその心配は入りません。またパラメータがn_neighbors以外に存在しないというのも問題です。これ以外の機械学習アルゴリズムには未知のパラメータ(回帰で言うなら傾き)など訓練データで学習して決定すれば、テストデータを用いて学習する際にはそのパラメータを渡してあげることで無駄な計算をする必要がなくなります。しかしk近傍法にはこのようなパラメータがないことから予測する際にも再度計算を行う必要性があります。
二つ目が実際に説明ができないからです。あくまで距離のみを用いて作成しているため、なぜそのような分類ができたのかを追求することができません。
そのような点から怠惰学習とも呼ばれているそうです。
では近傍法の説明が終わったところで次のk平均法の説明に移ります。
・k平均法
ではすっごいざっくりとk平均法のアルゴリズムについて説明します。
1.まずデータセットを用意してざっくりと代表点を定めます。
2.その次にデータセットの各点がどちらの代表点に属すか距離を用いて短い方を採用します。
3.その後作成したクラスタに属する点の重心を求めて新たな代表点を求める
4.3で作成した代表点を元にどちらに属すか決める
5.クラスタに属する点が変化しなくなるまで3.4.を繰り返す。
クラスタというのは作成されたデータの集まりのことを指します。scikit-learnのkmeansのメソッドでは予め作成するクラスタの数を指定する必要があります。2個クラスタを用意したい場合は2個の代表点の設定、といった感じになります。またこの代表点はランダムで設定されるため必ずしも最適なクラスタを作成できるとは限りません。データがシンプルな場合最適なクラスタを作成できるかもしれませんが、複雑になってくるとデータのチラバリ具合といった要因が発生するため難しくなってきます。
では実際にどのような処理が行われているのか数式を用いてみていきます。
まず(x,y)平面上の適当な点を{u_k}と置きます。(kは予め設定したクラスタ数。クラスタ数によって代表点uの数は変動します。)
その次にどの代表点に属すかという条件を次のように定義しておきます。

では次に現在の分類状況における二乗歪みを定義します。

下記のサイトから引用
https://data-flair.training/blogs/k-means-clustering-tutorial/
ではこの関数を最小化します。そのためには偏微分を行います。代表点uに対して偏微分を行います。その結果が下記の通りです。なぜuに対して偏微分を行うかというと、先程のJ関数中で歪みを左右するのはu(c)だからです。適当な代表点を取った場合はペナルティとしてJが大きな値を取ってしまいます。ここら辺は回帰問題の二乗誤差と似ているので、そちらを知っている場合は理解がしやすいかもしれません。
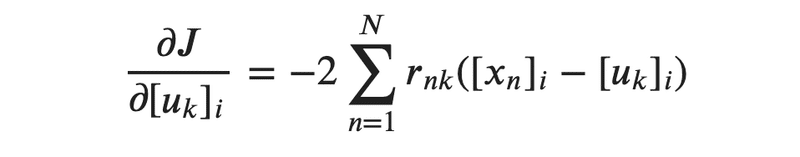
では次に新たに代表点を取り直すために重心を定義していきます。N_kとは代表点に属す点の個数を示しています。
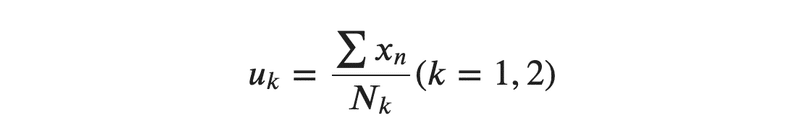
ここで先程の分類の条件をこの重心に加えます。
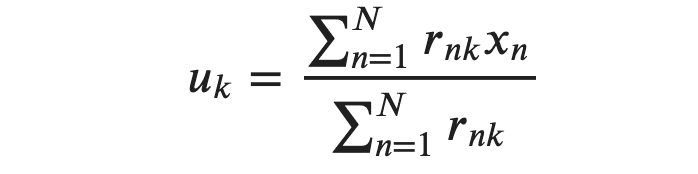
これによって求まったu_kを新たな代表点とし再度J関数を定義して重心を利用して新たな代表点を求める。この作業を繰り返していくとJの値が変化しなくなる極小値に達します。これがk平均法のアルゴリズムです。
以上でk近傍法とk平均法の紹介を終わりにします。クラスタリングには他にも沢山あるので後ほど紹介します。
・参考文献
ITエンジニアのための機械学習理論入門
pythonではじめる機械学習
この記事が気に入ったらサポートをしてみませんか?