機械学習(ランダムフォレスト編)

必要なモジュールを読み込んでいきます
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as snsSicket-Learnからパッケージを読み込んでいます
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_irisirisのデータを読み込んでいます
iris = load_iris()
iris_dataframe = pd.DataFrame(data=iris.data, columns=iris.feature_names)
print(iris_dataframe.head())
iris_dataset = sns.load_dataset("iris")
sns.pairplot(iris_dataset, hue='species', palette="husl").savefig('seaborn_iris.png')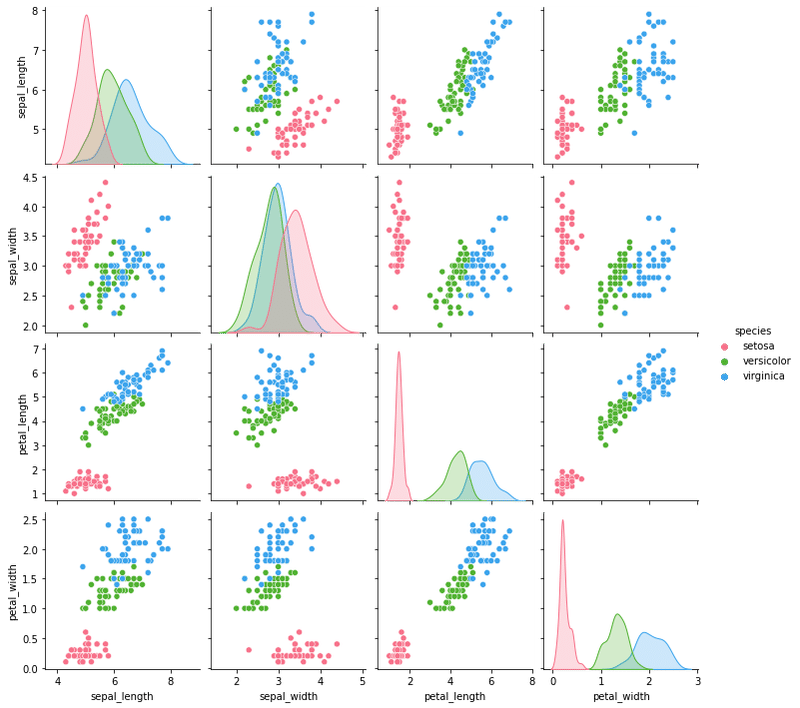
データをランダムに分割しています。
X = iris.data
Y = iris.target
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)ランダムフォレストで学習しています。
model = RandomForestClassifier(random_state=0)
model.fit(X_train,Y_train)検証用データで予測します。
predicted = model.predict(X_test)
expected = Y_test精度を確認しています。
accuracy_score(expected, predicted)
0.9736842105263158過学習がないか確認しています。
accuracy_score(Y_train,model.predict(X_train))
1.0この記事が気に入ったらサポートをしてみませんか?