モジュール分割

本ドキュメントの利用は、https://github.com/kae-made/kae-made/blob/main/contents-license.md に記載のライセンスに従ってご利用ください。
プログラムは複数のテキストファイルに分割して記述します。プログラムを記述したテキストファイルは、コンパイラによって実行プラットフォーム上で実行可能な形式に変換され、複数のテキストファイルから生成されたコンパイル結果は更にグルーピングされてパッケージ化(以下、ライブラリと記載することにします)され、実行プラットフォームにそのグループ化されたライブラリ単位でロードされて、プログラムに記述されたロジックが実行されます。

Python や JavaScript など、スクリプト言語と呼ばれているプログラミング言語で記載されたプログラムは、そのプログラムの実行時に都度、実行プラットフォーム上で実行可能な形式に変換されながら、処理されていきます。スクリプト言語にしろ、コンパイルされる言語にしろ、実行中に複数のライブラリを使いながら処理が行われます。

プログラミング言語によって、それぞれ形式は異なりますが、スクリプト言語の読み込み、あるいは、コンパイルされたライブラリがロードされた時に、最初に実行するエントリポイントの定義方法が決まっており、その定義に従って記述されたロジックから処理が始まります。

ロジックは、関数やメソッドと呼ばれる単位でまとめられ、データ構造の定義とともに、テキストファイルに記述されます。
一つのテキストファイルには、複数の関数、メソッド、データ構造定義を含むことができます。
プログラミングにおいて、設計したデータ構造やロジックからプログラム化した記述をどのように分割し、まとめるかは非常に重要な問題です。ソフトウェア開発においては、この善し悪しが、開発・保守・運用コストに影響を与えます。十数人で構成される開発チームが3チーム以上で開発するような中・大規模プロジェクトの場合は、影響は特に大きくなります。
本稿では、適切に分割されたまとまりを“モジュール”と呼び、ソフトウェアを適切に管理可能な断片に分割することをモジュール分割と呼ぶことにします。
例えば、C言語の関数や構造体、C++のメソッド、クラス定義、C++やC#、Javaなどの名前空間やクラス定義、テキストファイル化した単位、複数のテキストファイルをコンパイルしてリンクしたライブラリ等、全てに対してモジュールという言葉を使います。
このままモジュールについて説明を進めると、混乱しそうなので、モジュール分割を、“論理的な分割”と、“物理的な分割”の二つに分類して話を進めます。
論理的な分割
論理的な分割は、設計したデータ構造とロジックを、例として紹介した関数や構造体、クラス、名前空間等、プログラミング言語のセマンティクスを構成する概念を使って定義された単位に分割することです。論理的なモジュール分割の場合、その良し悪しは、はるか昔に提案された、凝集度と結合度という尺度で評価できます。
凝集度
1. 偶発的
2. 論理的
3. 一次的
4. 手順的
5. 通信的
6. 逐次的
7. 機能的
結合度
1. データ
2. スタンプ
3. 制御
4. ハイブリッド
5. 共通
6. 内部
それぞれの項目の詳細は読者にググりに任せます。凝集度は数字が高いほど良いといわれていて、結合度は数字が低いほど良いといわれています。結合度については、筆者の経験上、いかなる場合も、レベル1のデータ結合を満たすようにモジュールを論理的に分割するべきです。レベル2以上の結合については、アンチパターンということでやってはいけない例として理解するとよいでしょう。
一方、凝集度についてですが、凝集度の説明を見ると、一つの関数やメソッドについての指針と解釈できます。よって、それぞれの関数やメソッドについては、レベル7機能的凝集で分割すべきでしょう。ただし、プログラム実行の開始点であるエントリポイントを記述する関数やメソッド、スクリプト言語の場合は、その性質上、レベル6の逐次的凝集が許容されます。
クラスの定義については、カプセル化するデータ構造はそのクラスの役割に適した変数のみで、かつ、クラスのメソッド群から操作される(あるいは継承するクラスで操作される)変数だけに限り、カプセル化するメソッドも、クラスの役割に適した操作であり、かつ、直接操作する変数群は、引数で渡される変数とそのメソッドのスコープ内でのみ存在する変数以外は、カプセル化されたデータ構造の実装である変数群のみに限る、様にモジュール分割を行います。データ構造やロジックを実装する場合、クラスに対するものと、クラスを雛形にプログラムのロジックで生成されるインスタンスに対するものの2種類があることを忘れないでください。前者はそのクラスの全てのインスタンスがロジック内で参照するような固定値や動作を規定する設定変数、全インスタンスがそれぞれの状態に関係なく共通して持つロジックや、クラスという概念に結び付いたロジックやデータ構造です。「概念モデリング教本」で概念情報モデルに対する“問合せの操作”を実装する場合は、存在する全インスタンスを保持する集合変数と、その集合変数から全インスタンス、あるいは、条件に合致したインスタンスを取り出すメソッド(インスタンスの生成・削除のメソッドも含まれます)を、クラスの変数、メソッドとして定義することになります。後者は、概念クラスの特徴値や、特徴値の読み書きや振舞のアクション群が、それぞれインスタンスレベルの変数とメソッドとして実装されることになります。
※ C言語や C++ の場合、結合度の制約は場合によっては緩和しても構いません。メモリや MCU が安価になった昨今、もっと高級なプログラミング言語も使えるのに敢えて C・C++ を使うということは、メモリ量や処理時間に対する制約が厳しいプロジェクトであると考えられます。この場合では、メモリ効率、処理効率の為にあえて、レベル6の内部結合を使う事もあり得ます。
凝集度や結合度の他にも、ソフトウェアの品質を測る様々なメトリクスがありますが、実際の開発ではあまり教条主義的な対応をせず、柔軟にケースバイケースで対応できることも重要なスキルの一つです。
「概念モデリング教本」の流儀に従った開発では、この様な状況についても、概念モデルの何に対して制約を課すか、どのようにプログラミングするかを明確に設計できるので、一般的に非推奨と呼ばれるプログラミングスタイルをとっても、比較的安全なソフトウェアが開発可能です。
※ ついでということで、ちょっと横道にそれますが、C言語はオブジェクト指向言語ではないのでオブジェクト指向プログラミングは不可能だと一般的には認識されていると思われます。しかし、オブジェクト指向プログラミングは、しょせんデータと操作をカプセル化したものなので、構造体と関数ポインタを使えば、C++ や C#、Java のクラス定義っぽいものを定義可能です。関数ポインタが指す関数を都度都度変えてやれば、みんなが大好きな多態(Polymorphism)っぽいことも可能です。勿論、オブジェクト指向言語で可能な、private や public、protected など、変数のアクセススコープが無いので、完全なカプセル化とはいいがたいですが、何度もくどく繰り返して恐縮ですが、「概念モデリング教本」で解説している開発プロセスであれば、特に問題ないでしょう。
クラスの定義については、一部例外的なものがあるので補足しておきます。例えば三角関数や指数関数、対数等の数学的な関数や、一連のセキュリティに関する操作、特定のファイルフォーマットを操作するのに便利なユーティリティ的なロジック群など、データ構造は共有しないものの、同じ概念や役割を共有するロジック群をそれぞれのメソッドに分割して、一つのクラスのメソッドとして定義するのも一般的なやり方なので、モジュール分割のひとつの指針として覚えておいて損はありません。
最後に名前空間ですが、これは、「概念モデリング教本」で解説したドメインと一致させた分割が適しています。
物理的な分割
論理的な分割は、以下の3つのレベルに分類されます。
- 論理的に分割されたモジュールのテキストファイルへの配置
- 複数のテキストファイルのコンパイル結果をまとめたライブラリへの分割
- 実行可能なプログラムへの分割
テキストファイルへの配置
論理的に分割されたモジュールのテキストファイルへの配置の推奨方法は、採用したプログラミング言語によって変わります。C言語や C++ の場合は、データ構造とロジックを元に実装した構造体やクラス、関数やメソッドの宣言(declaration)をヘッダーファイルに、構造体を元にした変数や、関数・メソッドの実装の定義(definition)をソースファイルに、と分割して配置するのが一般的です。C言語の場合は、意味的に関連が深い構造体や関数群をまとめて、一つのヘッダーファイルとソースファイルの組にまとめます。C++ も含めて、場合によっては、一つのヘッダーファイルに対するソースファイルが複数のファイルに分割されていても構いません。
また、論理的に分割されたモジュール内で幅広く使われるような構造体や関数、マクロの定義などは、まとめて一つのヘッダーファイルに定義して、複数のソースファイルから読み込まれる(include)できるようにします。ヘッダーファイルへの分割配置については、C言語や C++ の標準ライブラリのヘッダーファイルを参考にするとよいでしょう。
C言語や C++ のコンパイルは、ソースファイル毎に行われます。ソースファイル毎に字句解析・構文解析が行われてマシンコードに変換されていきます。そのため、複数のソースファイルで include されているヘッダーファイルは、何回も字句解析・構文解析が行われることになります。
※ 以降、煩雑なので、ヘッダーファイル、ソースファイルの両方の意味を含む用語として、“ソースコードファイル”を使う事にします。
C# や Java の場合は、一つのクラスを一つのソースファイルに配置するのが原則です。この場合、クラスの宣言(declaration)と定義(definition)が同じファイルに共存することになります。あるソースファイルで定義されたロジックで別のソースファイル内で宣言されたクラスを参照可能な場合、参照される側のクラスのメソッドの実装の定義が、参照する側のロジックから丸見えになります。参照される側のクラスの実装の定義を隠蔽したい場合は、参照される側のクラスのメソッド群が利用可能なインターフェイスを定義し、その宣言を別のソースファイルに配置し、参照する側はそのインターフェイスにのみアクセスするといった方法がとられます。この場合、インターフェイスの名前空間と、参照対象だったインターフェイスを実現(Realize)するクラスの名前空間は異なるものにしなければなりません。
一クラス、一ソースファイルと冒頭で書きましたが、あくまでも原則であり、例外もあるので、実践では、基本原則を守ったうえでの臨機応変な分割を行います。
C# の場合、partial というキーワードがあって、一つのクラスで論理的に定義されている変数やメソッドをある観点毎に分割して、複数のソースファイルでそれぞれ定義することもできます。partial の仕組みは、実践上非常に便利な概念であり、一つのファイルに定義するとその便利さが失われてしまいます。
また、一クラス、一ソースファイルの場合は、同じ名前空間で定義されたクラス群はそれぞれ別のソースファイルに分割されることになりますが、場合によっては、同じ名前空間に定義されたクラス群を一つ、あるいは複数のソースファイルにまとめて定義することもあります。
いずれにせよ、複数人が参加するチーム開発においては、一つのファイルの担当者は唯一人にしておくことが重要です。
ライブラリへの分割
スクリプト言語の様に直接実行されるプログラム以外の、データ構造とロジックの実装が配置されたソースコードは、コンパイラによって実行プラットフォーム上で動作可能な形式に変換されます。コンパイルされたファイル群を、リンカーを使って結合すると、ライブラリファイルが出来上がります。ライブラリもまたモジュールの一種と、本稿では扱います。ライブラリファイルは、使用するプログラミング言語や OS によってフォーマットが異なります。C言語や C++ の場合は、実行ファイルを作成する時点で結合される静的ライブラリ(拡張子は Windows の場合:.obj、Linux の場合:.a)や実行中に動的に結合可能な動的ライブラリ(拡張子は Windows の場合:.dll、Linux の場合:.so)としてファイル化されて、利用可能な形で配布され、複数の実行ファイルに結合されて利用されます。また、Java の場合は Java Archive ファイル(拡張子は.jar)、C# の場合は、アッセンブリー(Portable Executable フォーマット)になります。C#の場合は、NuGet というサービスがあり、アッセンブリーファイルをNuGet対応のフォーマットでパッケージ化してインターネット上で公開でき、Visual Studio から簡単に開発中のプロジェクトに組み込むことができます。
通常のソフトウェア開発でよく使われるライブラリには、OS が提供する入出力やファイル操作などの基本機能をまとめたものや、ネットワーク通信に関するもの、文字列操作に関するものがあります。
ソフトウェア開発においては、ソースファイル群をどのように各ライブラリに配置するかを決めなければなりません。操作対象が同一のものをひとまとめにしてライブラリとして分割するのが基本ですが、実行プラットフォームやライブラリの配布方法、利用時のライセンス等も考慮した検討が必要です。
実行ファイルへの分割
実行ファイルは、コンパイラで実行形式に変換されたソースファイル群を結合したライブラリで、かつ、コンパイルされたソースファイル群の中に、プログラミング言語で規定されたプログラムのエントリポイントの定義を持つファイルです。スクリプト言語で記述されたソースファイルの場合は、そのソースファイルそのものを実行ファイルと見なして構いません。
実行ファイルは、実行プラットフォームの OS が提供するシェル上での起動、バックグラウンドで動作するサービス(Linux の場合はデーモン、Windows の場合は Windows サービスと呼ぶ)など、複数の形式で実行を開始できます。実行を開始したプログラムは、それぞれ“プロセス”と呼ばれる独立したメモリ空間を持つ処理の単位として OS 上で管理されます。実行中のロジックの中で、別の実行ファイルをロードして実行し新たなプロセスを生成することも可能です。
スクリプト言語で記述されたソースコードも、読み込まれた時点で字句解析・構文解析が行われて、実行可能な形式に変換されて実行されていく部分が違うだけで、プロセスが割り当てられて動くことに変わりはありません。
Linux や Windows の様な高機能な OS の場合は、複数のプロセスを同時に実行可能です。IoT ソリューションを構成する小型組込み機器の中には、HW リソースが少なく、ただ一つだけのプロセスのみ実行できるものもあります。
IoT ソリューションでは、クラウドサービス、現場側のサーバー、制御機器群と、様々な実行プラットフォームを持つコンピューティングリソースから構成されます。アプリケーションドメインの概念モデルは、プログラミング言語で記述されたデータ構造とロジックが実装として論理モジュールに変換されるときに、それぞれの概念や役割に応じて分割され、それぞれの断片が実行されるのにふさわしいコンピューティングリソースに分割されて配置されます。逆に言えば、与えられたハードウェア構成に対して、概念モデルのどこの部分をどのハードウェアに配置するかを決定しなければならないということです。この決定に当たっては、以下の3つのポイントを指針にします。
- そのデータを生み出す物理的な場所はどこか
- そのデータを変更した時に現実世界に働きかける物理的な場所はどこか
- その振舞を処理するのにふさわしい物理的な場所はどこか
クラウドサービスの配置先には、バーチャルマシン、マネージドサービス、あるいは、PaaS(Platform as a Service)と呼ばれる Cloud Native な実行環境が選択可能です。バーチャルマシンは、ユーザーの運用保守管理範囲から HW がなくなっただけのクラウド以前からのテクノロジーがクラウドと一般的に呼ばれる環境から使えるだけとも言えるので、運用、保守にかかるコストを更に本質的に低減したい場合は、OS やミドルウェアの管理も必要ないマネージドサービスの選択をお勧めします。IoT ソリューションを含む様々なビジネスシステムは、ユーザーに使われれば使われるほど、機能や性能に対する新しい要求が生じるものです。次々と生じる要求に対応するために、継続的にソリューションへの機能追加や機能改変が管理された状態で、継続的にできるようになっていなければなりません。加えてユーザーや IoT 機器が増えれば増えるほど、データ量と処理量は増えていくので、その増加に耐えうるスケーラビリティも必要です。これらのことも踏まえ、サービス側に配置するデータ構造とロジックの配置先を選択します。
機能追加や改変を行うということは、IT システム上に配置されたモジュールを置き換えることを意味します。処理のスケーラビリティに対応できるということは、ロジックが配置された実行プラットフォームの HW リソースを増減可能であることを意味します。マネージドサービスは、大抵この様なスケーラビリティに関する設定を持っていて、処理量と運用コストのバランスを見ながら調整可能です。モジュールの置き換えやスケーラビリティの対応には、Docke rを代表とするコンテナ技術や、大規模なコンテナ群の運用を支援する Kubernetes の利用も便利です。
より具体的な配置方法は、「チュートリアル」で紹介しているので、そちらも参照してください。
複数のプロセスが複数のプラットフォーム上で実行されるということは、マルチスレッドプログラミングの場合と同様、複数の実行スレッドが同時並行的に様々な場所で動いていることを意味します。それぞれのプロセスは、一つのITソリューションの構成要素であり、当然、プロセス間では、データのやり取りを通じたコラボレーションが生じます。このコラボレーションにおいては、マルチスレッドプログラミングの時と同様、リソースアクセスに関する排他や処理のデッドロックを回避する仕組みが必要です。
同一のプロセス内で同時並行的に動いていくスレッド群とは異なり、異なるプロセス間では、スレッドの時とは異なり、同じメモリ空間を共有することはできません。同一 HW の同一 OS 上で動いている複数のプロセス間では、OS が提供するプロセス間通信機構がこの問題を解決する手段として使用可能です。異なる HW に配置されたプロセス間は、ネットワーク通信機構を使います。プロセス間通信機構は Windows や Linux 系で若干名前が異なりますが、Socket、Named Pipe、Shared Memory、あたりは最低限使い方を覚えておくとよいでしょう。
モジュール間の通信に関するインターフェイスは、メッセージ駆動型アーキテクチャで使われる非同期通信を元にした設計を推奨します。
関数やメソッドをコールした時に、コールされた側の処理が完了するまでコールした側の実行スレッドが待つような場合を“同期(Synchronous)通信”、関数やメソッドをコールした時に、コールした側の実行スレッドが待たずに継続されるような場合を“非同期(Asynchronous)通信”と言います。コールされた側のモジュールの状態が変わらない(モジュールに実装されたデータ構造を構成する変数が、コール前、コール後で不変であり、処理の途中で別のモジュールの同期的通信を利用していない)場合は”同期通信”的なインターフェイスでも構いませんが、コールされた側のおジュールの状態が変わってしまうような場合は、このような状況が、排他制御が必要な状態やデッドロック状態が生じてしまうそもそもの原因の一つなので、“非同期通信”的なインターフェイスを定義するべきです。
※ 開発当初は、インターフェイスを通じた通信の結果、モジュールの状態が変わらない設計でも、開発が進むにつれ、あるいは、運用開始後の機能要件、非機能要件の変更により、モジュールの状態が変化するようになってしまうことは、まま、あることです。同期通信は非同期通信的なコラボレーションを実現することは不可能ですが、非同期通信は、同期的通信を代替できるので、最初からモジュールのインターフェイスは非同期的に設計する方が良いでしょう。非同期通信はメッセージ駆動型アーキテクチャを実現する一つの手段であり、「概念モデリング教本」で解説した状態モデルはメッセージ駆動型を前提にしたモデルなので、モジュール内のロジックを、状態モデルを使って設計しておくと、ストレスなく設計から実装への変換が可能です。
モジュールのインターフェイス
これまでの説明の中で、モジュールの“インターフェイス”という言葉を既に使ってきていますが、ここで、改めて、モジュールのインターフェイスについて言及しておきます。
論理的なモジュールは、全て、そのモジュールに配置されたデータ構造とロジックを利用するための、データ型、関数やメソッド、及び、そのシグネチャ、データ交換時のプロトコルの定義を持っています。それらは、物理的なモジュールの実装を記述したテキストファイルで宣言されていて、その宣言を使いながらコードを記述していきます。また、コンパイラは、利用している側のソースコードをコンパイルする際に、その宣言を使って実行プラットフォーム上で実行可能な形式に変換していきます。物理的に分割されたライブラリファイルや実行ファイルは、それぞれが配置され実行される実行プラットフォームの形式に従ってインターフェイスを利用可能にします。ソースコード上の記述は単なる関数コールでも、も物理モジュールの配置によっては、プロセス間通信やネットワーク通信が使われる場合もあります。実行モジュールがWebサービスとして配置される場合は、REST API(Representational State Transfer API)と呼ばれるインターフェイス形式で公開されるのが一般的です。この場合、利用する側は、HTTPによるネットワーク通信を介してインターフェイスを利用することになります。また、この様なインターフェイスの口を、サービスのエンドポイントと呼びます。この形式のインターフェイスは、IoTソリューションのサービス側でよく使う形式なので使いこなせるよう習得しておくことをお勧めします。
モジュールのインスタンス
多分、誤解している読者は少ないと思いますが、物理的なモジュールのライブラリファイル、及び、実行ファイルと、実際に実行プラットフォームに配置されて動作しているものの違いについて、念のため、言及しておきます。
実行ファイルへのライブラリのリンクは、そのライブラリファイルそのものではなく、ライブラリファイルの中身のコピーが作られて結合されます。また、実行ファイルが、実行プラットフォームに配置されるときに、その中身のコピーが実行プラットフォームのメモリ上にロード(配置)されて処理が行われます。同一の実行を元に作られたメモリ上の複数のコピーを同時並行的に動作させることも可能です。つまり、実際に動いているのは、物理モジュールを雛形にして作られたコピーであり、物理モジュールそのものではないという事に留意してください。これは、普段からパソコン上で Word やPower Point を複数立ち上げて作業をしている Information Workerには、「何を当たり前のことを」と思われるような説明ですが、ITシステム開発において、モジュール分割やモジュールの配置を検討している際には、案外忘れられがちです。ITシステム運用時の、実際に動いているサービス群の構成図を書くときに、モジュールと配置されて実際に動作しているモジュールのコピーを混同している例を多く見ているので、敢えて、ここで言及しています。
マネージドサービスも、サービスそのもの(これも一種のモジュールと呼んでいいでしょう)と実際に配置されて動作するサービスインスタンスの区別がついていないケースもよく見かけるので、注意してください。
Docker の場合、同じ Docker Image から複数の Docker Container を作って配置し、動かすのも、同一の物理モジュールのコピーを複数実行プラットフォームに配置するというのと同等です。これは要求が増えたときの処理能力向上させる仕組みの一つでもあるので、覚えておいてください。
モジュール間の依存
これまで説明してきた通り、ソフトウェアは複数のモジュールから構成されることになります。複数のモジュールは共通の問題を解決する解を構成するので、必然的にモジュール間の依存が生じます。依存とは、あるモジュールが別のモジュールが定義しているデータ型や関数、メソッドの宣言、及び、それらを通じて交換するデータ構造の定義(これらを総称してインターフェイスと呼んでいます)を利用することです。

C言語や C++ では、データ型や関数・メソッドの宣言をヘッダーファイルに記述し、関数やメソッドの実装の定義をソースファイルで記述するという物理的なモジュールへの分割が可能です。宣言を利用するソースファイルはその宣言が記述されたヘッダーファイルを include することにより参照ができるようになっています。C# や Java では、using や import を使って別のファイルで宣言された名前空間のデータ型やメソッドを参照できます。それらの結果として、物理的にファイルとして分割されたモジュール間に依存関係が発生します。

図表記では、依存する側から依存する側に矢印を描くことにより、依存を表現します。
モジュール分割においては、必ず、依存方向は一方向にしなければなりません。また、3つ以上のモジュールの間で依存の循環が生じないようにします。

C言語は通常、関数や構造体の宣言をヘッダーファイルに、関数本体や構造体による変数定義をソースファイルに記述します。C++ は、クラスの宣言をヘッダーファイルに、クラスメソッドの実装をソースファイルに記述します。どちらの言語でも、利用したい関数やクラスのヘッダーファイルをinclude で読み込んで、関数やメソッドコールのコードを記述します。この依存関係は一方向になっているのが判るでしょう。

また、C# や Java の場合、interface を使えば、メソッドの実装を、利用する側のモジュールに依存させることなく、メソッドの宣言が可能です。また、interface の別のクラスによる実装や、あるクラスを別のクラスで継承するような宣言も、依存関係という観点からすると、全て一方向であり、これらをうまく使いこなすことにより、モジュール間の依存方向を一方向に保てます。

ちなみにライブラリの場合、interface を使うと、プログラム実行時の動的なライブラリのロード・アンロードが可能になります。
同様なことはC言語でも関数ポインタを使えば実現可能です。
今、モジュール A とモジュール B の二つのモジュールが存在し、双方向に依存しているものとします。この場合、仕様変更や機能追加などで、A のモジュールに変更が生じると、その影響を受けて、B のモジュールにも変更が生じる可能性があります。また、B のモジュールに変更が生じると、依存しているモジュール A にもまた影響が出る可能性があります。結果的に、どちらのモジュールに対する変更も一仕事になってしまいます。
モジュール A のみがモジュールBに依存している場合は、モジュール A を変更してもモジュール B には一切影響がないので、モジュール A の変更は自由出来ます。モジュール B を変更する場合には、モジュールAも影響を受けるので変更しなければなりませんが、モジュール A の変更はモジュールBの変更に一切影響を及ぼさないので、モジュール B の変更においては、モジュールAの変更は一切考慮しなくて構わないので、依存が双方向の場合に比較して、開発・運用・保守に有利なわけです。
モジュール分割の際の依存方向については、もう一つ考慮すべきポイントが存在します。それは、依存される側の変更頻度が、依存する側の変更頻度より低いように分割しなければならないということです。頻繁に変更が生じるモジュールに依存しているモジュールの場合、依存している側のモジュールの変更のたびに影響を受け、何らかのアクションをしなければならなくなります。

モジュール分割の際の一つの目安として活用してください。
レイヤー型のアーキテクチャ
大規模システムでは、アプリケーション要件に近い処理を行うモジュール群を上の方に、HWやインフラに近い要件を扱うモジュールを下の方に、ネットワークやデータベースなどのミドルウェアを中間に配置して、システムを階層的に構成するレイヤー型のアーキテクチャを採用するのが一般的です。レイヤー型のアーキテクチャの場合の依存方向は、もちろん、“上から下へ”が鉄則です。もし下層のモジュールが上層のモジュールに依存しているなら、それはレイヤー型のアーキテクチャではないので、モジュール分割、配置の見直しが必要です。

ここで、一つ疑問が沸きます。モジュール間の依存は、依存される側のライフが依存する側のライフより長い方が良いという基準を用いると、ITシステムの目的であるそれぞれの組織の問題を解決するアプリケーションのライフは、ミドルウェアやインフラのライフより短いことになるが、必ずしもそうではないのではないかという、疑問です。他にも、HW やインフラ、ミドルウェアは、ユーザー組織以外の外部のベンダーが提供するものなので、レイヤー型アーキテクチャを採用するということは、つまり、特定の業者にベンダーロックインされることを意味するのではないか、という危惧を抱く読者もいるかもしれません。
ベンダーロックインされることの是非はさておき、レイヤー型のアーキテクチャの図に描きこまれるモジュールは物理モジュールであることを念頭に、モジュール間の依存を少し詳しく見てみると、上のモジュールが依存するのは、正確には、下のモジュールのインターフェイスであり、下のモジュールの中身の実装は、下のモジュールのインターフェイスを実現するものであることが判ります。つまり、下のモジュールの中身の実装は、下のモジュールのインターフェイスの定義に依存していて、かつ、各ベンダーが提供しているのは、モジュールの中身の実装なので、実は、上のモジュールは、各ベンダーには直接は依存してはおらず、結果的にベンダーロックは発生しえない事を意味します。
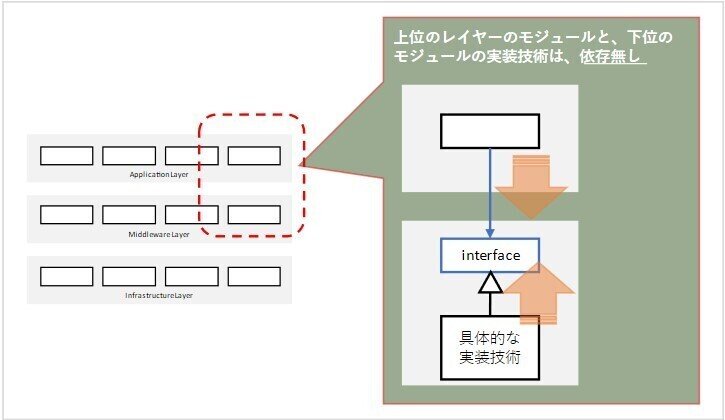
それぞれのレイヤー間で、上側のモジュールが依存するのが下側のモジュールのインターフェイスであるということは、レイヤー型のアーキテクチャの本質は、実は、モジュール構成ではなく、どの様なインターフェイスを層状に配置するかにあるといえるでしょう。
IT 技術の歴史を振り返ってみれば、例えばデータベースでは、ベンダーによらない標準のクエリー言語である SQL があり、ODBC や JDBC といったベンダーの差異を吸収するインターフェイス標準が使われてきたり、ネットワーク通信では、OSI の7階層モデルや、TCP/IP、UDP/IP、HTTP 等といった標準プロトコルが使われてきています。C や C++ では、stdio や pthread など、様々な HW、OS で共通に使える標準ライブラリが提供されています。これらは、下側のモジュールのインターフェースとして利用可能です。
まとめると、レイヤー型のアーキテクチャによるモジュール構成設計は、それぞれの階層ごとに、特定のベンダーに依存しないデファクトの標準インターフェイスを上手く使って、モジュール群を階層化して配置するのが本質であるといえます。
※ 以上の議論は、システム構築に当たって適切な設計を行ったうえでモジュール分割、モジュールの階層的な配置を行った場合にのみ適用可能な内容です。適当に手を抜いた設計しかなされていない場合には通用しないのでご注意ください。
※ あくまでも筆者の個人的な見解ですが、敢えて、ベンダーロックインされたシステムを構築するのも生き残り戦略の一つではないかと思っています。ベンダー側に主導権を握られたくないというのが、ベンダーロックインされたくない主な理由だと思いますが、提供する側のベンダーからすれば、ちょっとしか利用しない小口ユーザーよりたくさん使ってくれる大口ユーザーを優遇するのは当たり前の話です。むしろ、たくさん使う大口ユーザーになって、ベンダー収入の大きな割合を占めれば、ユーザー側が主導権を握れることになります。複数のベンダーのサービスや技術・製品をつまみ食い的に、小口利用して全てのベンダーに対して不満を持つより、特定のベンダーと組んでシステムの開発・運用・保守をやった方が、建設的ではないでしょうか。
様々なモジュール構成
マイクロソフトが公開している「アーキテクチャスタイル」は、これまで言及してきたレイヤー型アーキテクチャを含む様々な構成スタイルを解説しています。レイヤー型以外のアーキテクチャスタイルも、基本的に、インフラストラクチャー、ミドルウエアという階層の上位のレベルのスタイルなので、大きな枠組みとしてはレイヤー型アーキテクチャ前提のスタイルであるといってもいいでしょう。
このドキュメントも含め、Azure アーキテクチャセンターは、クラウド上のソリューションを構築する際のアーキテクチャ設計に関する様々な記事が公開されていて、非常に参考になるので、読み込むことをお勧めします。
ドメイン間の依存性
ここでは参考までに、概念モデルのドメインの依存について言及しておきます。
「概念モデリング教本」では、アプリケーションドメイン、サービスドメイン、インフラストラクチャドメインを紹介しています。あるドメインに対して構築した概念モデルは、別のドメインには一切依存関係がありません。あるのは、モデル化対象の現実世界のモノやコト、概念や役割と、概念モデルの定義への依存だけです。概念モデルの実装への変換方法を検討するプロセスでも、ドメインを記述する概念モデルの要素間の対応付けが基本であり、一方向の依存しか存在していません。
![]()
この依存関係においては、IT システムの目的であるそれぞれの組織の問題を解決するアプリケーションの世界と、実装技術の世界のライフは無関係です。どちらもそれぞれの事情で変化し、それに伴って IT システムの実装が修正される、という当たり前の事実が淡々と語られている図といえるでしょう。また、ドメインは独立した存在なので、ドメインモデルの作成は、原理的に、同時並行的なモデル構築が可能です。
次の章では、モジュール分割を行う際にも有用な、「フレームワーク」について解説します。
この記事が気に入ったらサポートをしてみませんか?