GPT-4Vによる化学論文データマイニングのプレプリント: Image and Data Mining in Reticular Chemistry Using GPT-4V

はじめに
表記のプレプリントを読んだ際のメモです。(批判的に読んでますので注意)
図はすべてpreprintからの転載です。
アブストラクト
この研究は、科学研究における人工知能の利用が新たな頂点に達したことを示しています。具体的には、視覚機能を強化した大規模言語モデルであるGPT-4Vが、ChatGPTやAPIを通じて利用可能になりました。この研究では、GPT-4Vが金属有機フレームワークに関する複雑なデータを、特にグラフィカルな情報源からナビゲートし、採掘する顕著な能力を実証しています。
具体的な方法としては、346件の学術論文を6240枚の画像に変換する自動プロセスを経て、これらの画像を自然言語のプロンプトを使用してGPT-4Vで分類し、分析することです。この方法論により、GPT-4Vは、窒素等温線、PXRDパターン、TGA曲線など、MOF特性評価に不可欠な主要なプロットを正確に識別し、解釈することができました。これは、精度とリコールが93%以上であり、プロットから重要な情報を抽出するこのモデルの熟練度は、データマイニングにおけるその能力だけでなく、網目化学のための包括的なデジタルデータベース作成を支援する潜在能力を強調しています。
さらに、選択した文献から抽出された窒素等温線データを使用して、200以上の化合物について理論的および実験的な多孔性値を比較し、特定の不一致を強調し、計算データと実験データを統合することの重要性を示しました。この研究は、AIが科学的発見とイノベーションを加速し、計算ツールと実験研究の間のギャップを埋め、より効率的で包括的、そして包容的な科学的探究の道を開く可能性を浮き彫りにしています。
タスク1 グラフの種類の判別(Fig2)
与えられたグラフがどのような種類のデータなのかを判別するタスクを最初に試みたようです。
例えばFigS1にプロンプト+画像と応答の例が書かれています。

どのような測定に関するグラフなのか、化合物の名前、x,y軸のラベルとスケールなどは読み取れているようです。
たくさんのグラフを与えて、それがどのような種類の計測データなのかを判別させたのがFig2です。

かなりの高精度が出ています。
一方、Figureのタイトルだけを与えれば、言語だけでもclassificationはできそうなので、画期的な進歩、という感じではない気がしました。
(この道の専門家も一瞬で判別できます)
タスク2: グラフの分析
[要約]
窒素等温線のプロットを含むページの詳細な解釈と分析に、GPT-4Vを使用することに焦点を当てました(図S15参照)。GPT-4Vは窒素等温線を認識するだけでなく、各プロットから主要な記述子を抽出し報告するように導かれました。これらの記述子には、図の番号、化合物名、著者によって報告された表面積または孔容積値、吸着-脱着曲線のヒステリシスの存在、等温線の飽和プラトー、および図を包含する境界ボックスの推定(図3参照)が含まれます。
GPT-4Vの窒素等温線分析の精度を検証するために、選択した論文内の窒素等温線を含む200以上のページからの応答を手動でレビューしました。この評価は、6つの記述子のそれぞれについて個別に行われました。その結果、図の番号(96.67%)、化合物名(90.42%)、および多孔性分析(98.33%)について高い精度レベルが示されました。一方、ヒステリシスの存在、飽和プラトー、境界ボックス推定といった他の3つの記述子は、一般的に満足のいくパフォーマンスを示し、76.25%から84.58%の範囲でした。
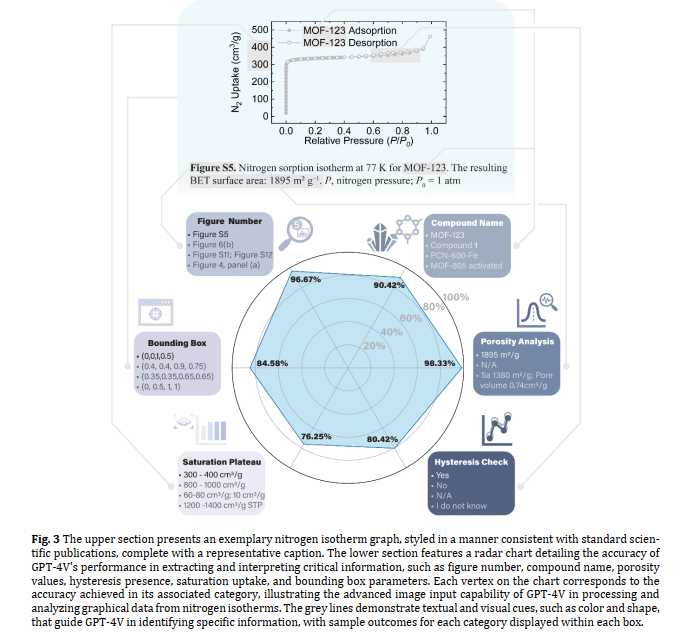
グラフの構成要素をそれなりの精度で読み取れる、ということでした。これも、一般的に言われるGPT-4Vの性能からすると、想定内です。
一方、データベース構築では体感で99%くらいの精度が必要です。
加えて、本質的に重要なのはプロットの読み取りです(以下参照)。
データベース構築
この研究においては、プロットの読み取りを人力で行ったようです。WebPlotDigitizerという、知る人ぞ知るツールです。
このツールを使い、MOFと呼ばれる多孔性材料のデータベースを構築したようです。
論文では、実測値と計算値の違いを比較して、実測データを取ることの有用性を主張しています。(GPT-4Vは特に関係ありません)
[要約]
この研究では、GPT-4Vを利用して包括的なデジタルデータベースの構築を加速しました。特に、非デジタル形式で提示される窒素等温線プロットを含むページからのデータを抽出し、WebPlotDigitizerのようなツールで精密に処理しました。抽出されたデータはデータベースに体系的に格納され、CoRE MOFデータベースと照合されました。これにより、理論値と実験値の比較が可能となり、化合物の特性に関する新たな洞察を提供しました。この研究は、データ駆動型科学的探究の促進と、網目化学分野での新たな発見やイノベーションの加速を示しています。
この研究は、計算結果のみに依存する材料選択が、実験結果と大きく異なることがあるため、時に誤解を招く可能性があることを示しています。実験で得られた非多孔性化合物は、データセット内の貴重な否定的データポイントとして機能します。計算手法と実験データを組み合わせることで、研究者は網目化学におけるより包括的な洞察を得ることができます。さらに、GPT-4Vの能力を活用して、窒素等温線だけでなく、他の等温線や重要なプロットも含むより多くの実験データを検索することで、望ましい特性を持つ高性能化合物の発見と開発が進むと考えられます。この過程で、プロンプトの巧みな作成とDSPyのようなツールの活用が重要です。DSPyは、言語モデルの指導を自動化し、研究の精度と範囲を拡大するための重要な進歩となるでしょう。
感想
ちょっと厳し目のコメントですが、正直、「うーん…」という感じでした。
GPT-4Vでグラフ中のラベルetcを読み取れるのは、わりと多くの人の知るところです。
過去に、一万件ほど、地獄のデータマイニングをやったことがあります。
https://pubs.acs.org/doi/10.1021/jacs.9b11442
その時の経験に基づくと、データマイニングの構成要素と大変さは、今回GPT-4Vが行った箇所とは、全く別のところにあります。
読むべき論文の選択: 結構大変
読み取るべきグラフの選択: ちょっと面倒
グラフにかかれている材料情報の認識: 超大変
例: 略称XYZで示される材料の構造は一体何なのか?
論文を丹念に読み込まないと正確に理解できない
重量組成とモル組成を変換したりしなければならないケースも有り
合成・測定条件はどのようなものであるか?
プロットの読み取り: 大変
手作業
グラフ中の構成要素の認識(ラベル名など): 瞬時
今回位のGPT-4Vのタスク
一連の作業に間違いがないかの確認: 大変
あまりにも大変なので、国の研究所(NIMS)なんかだと、データマイニング専門の職員がいらっしゃるようです。
今回のタスクは、専門家だと瞬時に終わる系の仕事なので、あえてGPT-4Vを使うまでもないのかなーという印象でした。
この記事が気に入ったらサポートをしてみませんか?