大規模言語モデル: Mixture of experts(MOE)のMixtral-8x7B-Instruct-v0.1で遊ぶ

1/17 ファインチューニングを追記
はじめに
GPT3.5と同等性能と評判のMOE、Mixtral-8x7Bを動かしてみます。
23年の12月頃に話題になったモデルです。
ポイントは、小型(7B)のモデルを8つ混合して使う点です。大型のモデルを一つ使うよりも、学習や推論を高速に行えるようです。
専門モデルを作って組み合わせるというアイデアは、超巨大LLMを作る予算がない人達にとっても希望です。
セットアップ
npakaさんの記事が参考になります。 transformersから呼び出すだけでOKです。
推論速度のチェック
モデルロード
以下のコードでモデルを読み込みます。
ビット数は適宜、変えましょう。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"mistralai/Mixtral-8x7B-Instruct-v0.1",
)
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mixtral-8x7B-Instruct-v0.1",
torch_dtype=torch.bfloat16,
#load_in_4bit=True,
device_map="auto",
trust_remote_code=False,
)16 bitで読み込んだら、96 GBほどVRAMを消費していました。
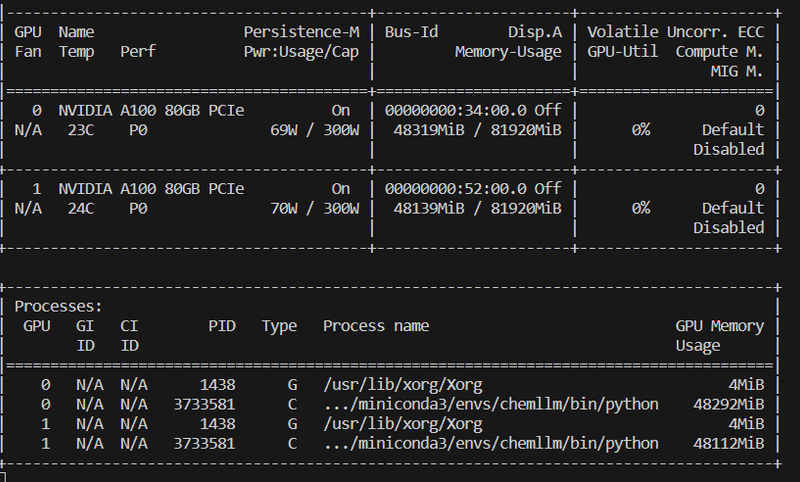
推論
pipelineで動かせます。
from transformers import pipeline
pipe = pipeline("text-generation", model=model,tokenizer=tokenizer,
)
pipe("Q: hello! how are you? A: ")一瞬で回答が返ってきました。
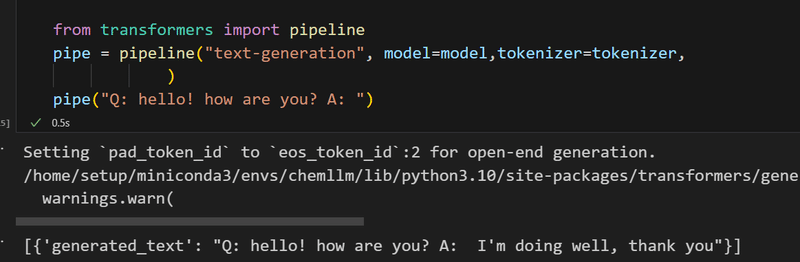
ただ、pipelineだと、短い回答しか返ってこない※ので、長めの質疑をやってみます。
※max_new_tokensで設定できた気がします
以下、別の目的で、逐次的にtokenを出力させるために書いたコードです。
今回は使いませんが、stop_wordsが1回以上、出てくる or double_stop_wordsが二回以上、出てくると、生成を停止する仕様になっています。
import re
import torch
import gc
from IPython.display import clear_output
from trl import AutoModelForCausalLMWithValueHead
def gen_text_stop_word(prompt,model,tokenizer,
device="cuda:0",
stop_words=["#Problem","#Reason","# Problem"],
double_stop_words=["#Prediction"],
stream=False,
#stream=True,
max_tokens=400,
):
gc.collect()
torch.cuda.empty_cache()
input_ids = tokenizer.encode(prompt, return_tensors='pt').to(device)
# 生成されたテキストを格納する変数
generated_text = ""
# トークンを一つずつ生成
for i in range(max_tokens):
# 次のトークンを予測
outputs = model(input_ids)
if type(model) is AutoModelForCausalLMWithValueHead:
#AutoModelForCausalLMWithValueHeadの場合
logits = outputs[0]
next_token_logits = logits[:, -1, :]
else:
next_token_logits = outputs.logits[:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1).unsqueeze(-1)
# 生成されたトークンを現在の入力に追加
input_ids = torch.cat([input_ids, next_token], dim=-1)
# 生成されたテキストを更新
generated_text = tokenizer.decode(input_ids[0], skip_special_tokens=True)[len(prompt):]
if stream:
if i%1==0:
clear_output()
print(generated_text)
# ストップワードのチェック
if any(stop_word in generated_text for stop_word in stop_words):
break
# 2回以上出現したらstopするwordのcheck
stop_flag=False
for check_word in double_stop_words:
count=generated_text.count(check_word)
if count>=2:
stop_flag=True
break
if stop_flag:
break
return generated_text
回答の結果
prompt="What's your hobby?"
gen_text_stop_word(prompt,model,tokenizer,stream=True)生成スピードは以下のとおりです。
16bit モデル
今更ながら、mistralai/Mixtral-8x7B-Instruct-v0.1 で遊び中です。32 bit(48x2 GBほどvram使います)で回してます。
— 畠山 歓 Kan Hatakeyama (@kanhatakeyama) January 16, 2024
小気味よい速さです。
MOEは日本勢でも何かcontributionができそうな、期待感を感じました。 pic.twitter.com/eedShAhN8n
4 bit モデル
先程のは16bitでした。
— 畠山 歓 Kan Hatakeyama (@kanhatakeyama) January 16, 2024
4bitはこちら。少し遅くなります。
VRAMは30GB弱でした https://t.co/FxlUfis704 pic.twitter.com/zBbxI0Sm8i
16 bitの方が、二倍以上は早い気がします。
また、llama 70bは16, 4 bitともに、驚くほど遅い印象があるので、Mixtral-8x7Bの良さを体感しました。
問題を解かせる
足し算
流石に余裕でした。

化学的な考察をさせる
5-amino-1,3-diphenyl-1h-pyrazoleという化合物が融点131℃を示す理由を考えさせます。
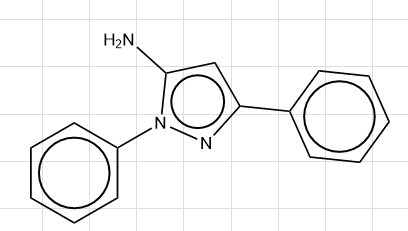
(このあたりのモチベーションについては以下の記事を参照)
プロンプト
Provide the quantitative Reason and Prediction so that a scientist, who does not know the melting point, can predict the value.
#Commands
- You must quantitatively consider how the melting point shifts, focusing on each functional groups.
- Actual value and Prediction must match each other.
- If Actual value and Prediction differ each other, rethink Reason.
- If Prediction does not contain numbers for each functional group effect, rethink Reason
#Example reason
#Name: Chloroform
-Dichloromethane has a melting point of -97.
-Chloro group: +33 (larger molecular weight)
#Prediction: -64
Data
#Name: 5-amino-1,3-diphenyl-1h-pyrazole
#SMILES: c1ccc(cc1)c2cc(n(n2)c3ccccc3)N
#Actual value: 131.0
#Reason: 結果
-Phenyl group: +50 (larger molecular weight)
-Pyrazole group: +10 (hydrogen bonding)
#Prediction: 161.0実際は131℃であるにも関わらず、161℃という予測になってしまいました。
GPT-4だと、もう少しくわしい考察をしながら、うまく辻褄合わせしてくれるので、流石に性能は劣るようです。
が、使いようはあるかなと思いました。
化学的な予測をさせる
上記の例と少し似てますが、GPT-4が作ったテキストをもとに、one-shotのプロンプトチューニングしながら理由付き予測をさせてみます。
プロンプト
You are a professional chemist. Predict the melting point of the following compound.
#Problem
##Name: (1,2,2,3-tetramethylcyclopentyl)methyl 4-aminobenzoate
##SMILES: O=C(OCC1(C)CCC(C)C1(C)C)c1ccc(N)cc1
##Reason: To predict the melting point of (1,2,2,3-tetramethylcyclopentyl)methyl 4-aminobenzoate, we consider the effects of various functional groups and structural features:
- Basic unit, cyclopentane has a typical melting point around -94°C.
- Methyl groups: Four methyl groups attached to the cyclopentane ring increase molecular weight and steric hindrance; each can contribute an estimated +20°C due to increased van der Waals interactions.
- Benzene ring attached via ester linkage: The aromatic ring contributes to an increase in molecular weight and rigidity; estimated contribution is +80°C.
- Ester group: Ester functionality typically raises the melting point due to polar interactions and possible hydrogen bonding if protic solvents are present or intramolecularly; estimated contribution is +40°C.
- Amino group on the benzene ring: The amine can engage in hydrogen bonding, raising the melting point further. Its effect might be less pronounced due to intramolecular interactions with the ester group; estimated contribution is +20°C.
Combining these effects in a qualitative manner leads to the predicted melting point.
##Prediction: 74.0
#Problem
##Name: 2,3-Dichloroquinoxaline
##SMILES: Clc1nc2ccccc2nc1Cl
##Reason: 出力
- Basic unit, quinoxaline, has a typical melting point around 80°C.
- Chlorine atoms: Two chlorine atoms attached to the quinoxaline ring increase molecular weight and steric hindrance; each can contribute an estimated +20°C due to increased van der Waals interactions.
- Nitrogen atoms in the quinoxaline ring: Nitrogen atoms can engage in hydrogen bonding if protic solvents are present or intramolecularly; estimated contribution is +10°C.
Combining these effects in a qualitative manner leads to the predicted melting point.
##Prediction: 110.0正解は152℃のところ、予測は110℃でした。
値はややズレてますが、化学的な考察は妥当でした。
また、分子物性の予測訓練を明示的に行っていないモデルにしては、上出来の予測だと思います。
LoRAファインチューニングをする(1/17追記)
概要
以下の記事で進めている、化学系のテキストを予測させるタスクでファインチューニングしてみました。
汚いですが、コードはこちら。
実装
標準的な、transformers, peftライブラリ上で動きます。
ただし、どの層にadapterを付けるかについては、ある程度真面目に考える必要がありそうです。
モデル構成などについては、以下の記事が参考になります。
モデルをチェックします。
print(model)
#結果
PeftModelForCausalLM(
(base_model): LoraModel(
(model): MixtralForCausalLM(
(model): MixtralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MixtralDecoderLayer(
(self_attn): MixtralFlashAttention2(
(q_proj): Linear(
in_features=4096, out_features=4096, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(k_proj): Linear(
in_features=4096, out_features=1024, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(v_proj): Linear(
in_features=4096, out_features=1024, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(o_proj): Linear(
in_features=4096, out_features=4096, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(rotary_emb): MixtralRotaryEmbedding()
)
(block_sparse_moe): MixtralSparseMoeBlock(
(gate): Linear(
in_features=4096, out_features=8, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=8, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(experts): ModuleList(
(0-7): 8 x MixtralBLockSparseTop2MLP(
(w1): Linear(in_features=4096, out_features=14336, bias=False)
(w2): Linear(in_features=14336, out_features=4096, bias=False)
(w3): Linear(in_features=4096, out_features=14336, bias=False)
(act_fn): SiLU()
)
)
)
(input_layernorm): MixtralRMSNorm()
(post_attention_layernorm): MixtralRMSNorm()
)
)
(norm): MixtralRMSNorm()
)
(lm_head): Linear(
in_features=4096, out_features=32000, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=32000, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
)
)
)
adapter層をつけられそうな箇所を指定していきます。
target_modules= [
"lm_head", #最終的な出力
"q_proj", #以下、attention関連
"k_proj",
"v_proj",
"o_proj",
"gate",
#"w1","w2,"w3", #mlpの重み。 こちらを入れると、lora層の生成に2-3分?、時間がかかるので注意
]peftモデルを定義します。
from peft import LoraConfig, get_peft_model
peft_config = LoraConfig(
task_type="CAUSAL_LM", inference_mode=False, r=r, lora_alpha=lora_alpha,
lora_dropout=0.1,
target_modules=target_modules,
)
model = get_peft_model(model, peft_config)adapter層の確認をしていきます。
#層の表示
for name, param in model.named_parameters():
print(name)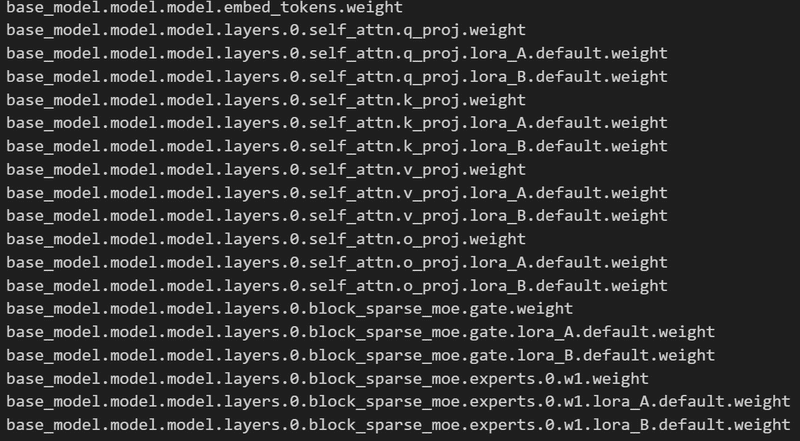
訓練はtransformersのTrainerで普通に行なえます。
学習の様子は以下の通り。
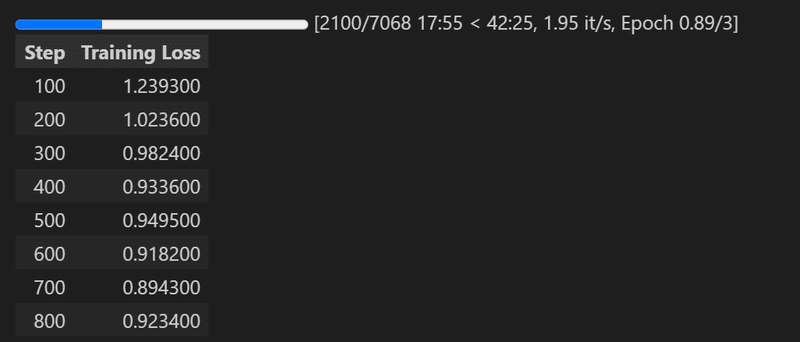

MLP層(w1,2,3)を入れなければ、15分ほどで学習できたと思います。
結果
分子構造から融点を予測させるためのテキストをファインチューニングしました。今までで一番良い性能が出ました!
MLP層はadapterに入れたほうが良さそうです。
ファインチューニング前
→ 殆ど予測ができなかったので、割愛
ファインチューニング後(前述listのw1,2,3層以外を学習)
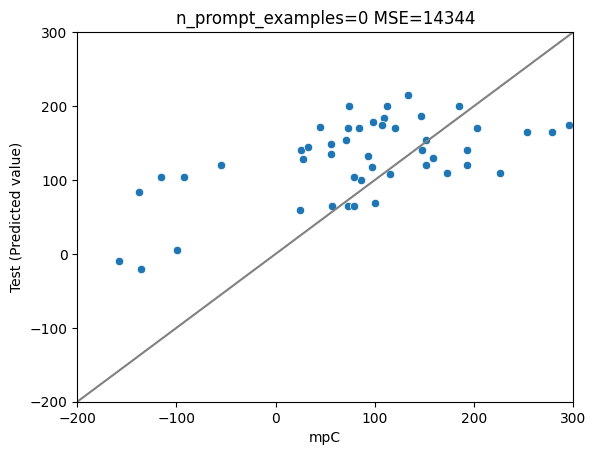
ファインチューニング後(前述listの全層を学習)
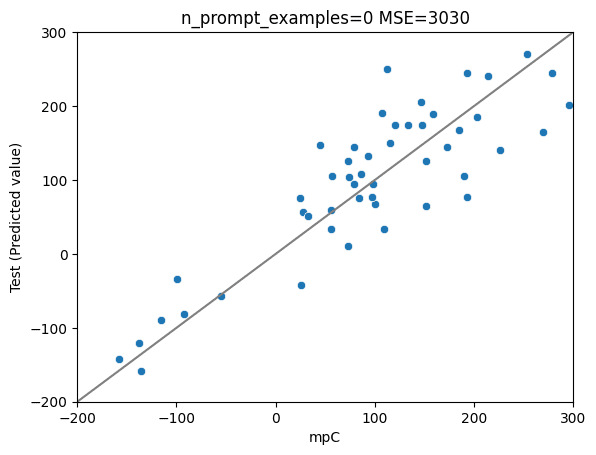
MSE: 3030
MAE: 45
R2: 0.74

考察
llama2-7bは、考察は正しくても、ちょくちょく計算ミスをおかしたりするので、基礎力が足りない印象があります。
きちんとチェックはできていませんが、Mixtralは基礎力が高めの印象がありますので、予測性能が上がったのだと思います。
まとめ
このモデルは高速かつ、それなりに賢いことがわかりました。
わりと使い道がありそうなので、引き続き活用検討していきます。
この記事が気に入ったらサポートをしてみませんか?