大規模言語モデル・ロボットを起点とするラボオートメーションに向けた状況整理

(以下、下書きをGPT-4が校正したものです)
はじめに
化学分野、特に研究の自動化において、大規模言語モデルやロボットの利用は、未来のラボオートメーションを変革する可能性を秘めています。
Prompt engineering of GPT-4 for chemical research: what can/cannot be done?
研究者の方々とディスカッションを重ねる中で、「将来、科学者が不要になるのでは?」という半ば冗談めいた質問を受けることがあります。遠い未来において、これが現実のものとなる可能性は否定できません。
しかしながら、実際の研究の進行においては、より深掘りした議論が必要不可欠となってきます。例えば、「AIとロボットが大活躍する"将来"はいつなのか?」、「その実現に至るプロセスはどのようなものであるか?」といった点について、現状を踏まえながら、解像度を高めて考察を進める必要があります。
本記事では、頭を整理する一環として、2023年10月時点での、私の視点に基づく状況分析と展望に関するメモをまとめています。参考文献などは特に記載しておりませんので、その点についてはご了承ください。
GPT-4の現状と課題
GPT-4の驚きと「幻滅期」
執筆時点で最高性能を誇る大規模言語モデル(AI)は、OpenAIのGPT-4です。ペーパーテストでの高得点、膨大な知識の保有、そして英語やプログラミングにおける卓越した能力など、多くの人々を驚かせる性能を発揮しています。
2023年3月の公開直後は、一部のコミュニティではまさにお祭り状態となり、世界が劇的に変化するのではないかという高まる期待が感じられました。ところが、本記事の執筆時点である10月においては、ChatGPTを超える、あるいはそれに匹敵する“キラーアプリケーション”は登場しておらず、技術の普及には当初の想定以上に時間がかかるのではないかという視点が主流になりつつあります。
これは、GPT-4をはじめとする大規模言語モデルが出力する情報に多くの誤り(ハルシネーション)が含まれていたり、推論能力が人間に及ばなかったり、扱うことのできる情報がテキスト(や画像)に限られているなど、いくつかの制約が顕在化しているためです。
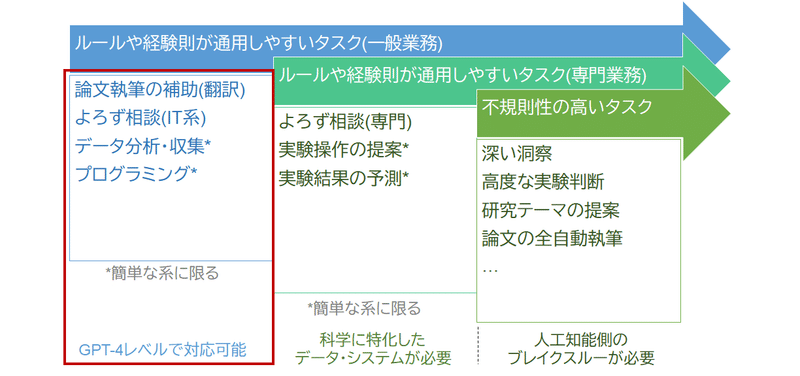
手放しでオススメできるGPT-4の用途は何か?
筆者はGPT-4を頻繁に利用していますが、最近、ChatGPTに対して行う質問のジャンルが著しく偏っていることに気づきました。これは、特定のジャンルを除けば、GPT-4が実用レベルの回答を示さなかったことを示唆しています。
筆者が無条件で他者に推薦できるGPT-4の使用ジャンルは、「英語」と「IT分野」です。
英語
GPT-4の英語能力は卓越しており、TOEICスコア900点超えの筆者(非帰国子女の日本人としては上位?)のそれを凌駕しています。
最近執筆した論文では、日本語で下書きを作成し、それをGPT-4に英訳してもらう形で原稿を完成させました。作業時間が大幅に削減されただけでなく、論文の査読時にレビュアーから「英語が下手」というフィードバックを受けることもなくなりました。
DeepLやGoogle翻訳などの単なる翻訳ツールと比べたGPT-4の利点は、シチュエーションを指定できることです。ChatGPTに「英語で論文を書いています。次の文章を英訳してください」とお願いすれば、格式ある原稿が返ってきます。一方で、従来の翻訳ツールでは、カジュアルな英語と学術用途の英語を使い分けるのが難しく、誤訳も目立ちます。
IT分野(特にプログラミング)
IT分野、特にプログラミングにおけるGPT-4の能力とシステム関連の知識は非常に卓越しています。その力は広く認められており、プログラマーに愛用されている掲示板、Stack Overflowへのアクセス数が減少しているとの報告もあります。
人間に尋ねるよりも、AIに尋ねたほうが迅速である、というわけです。筆者自身も、Googleで検索する前に、まずはChatGPTに問い合わせを行うことがほとんどとなりました※。
※ただし、最新の大規模言語モデルの実装コードなどに関しては、GPTの知識がまだ追いついていないため、Googleで検索を行います。
GPT-4の得意なジャンルの共通項は何か?
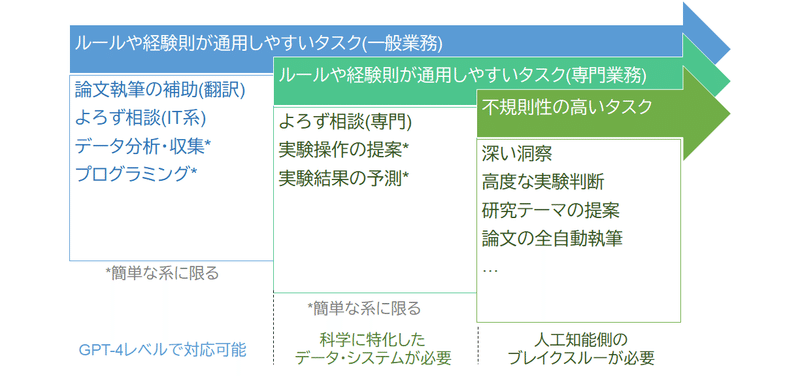
GPT-4が実用レベルのパフォーマンスを発揮する分野には、ある程度の共通点が存在します。それは、a. ルールや経験則が適用可能で、b. 大量の学習データが存在し、c. ユーザーよりも知識量が豊富であるタスク、といった特徴です。
先述した英語やプログラミングにおいては、a. ルール(文法)が存在します。そのため、多くのデータを供給すれば、AIはその法則を抽出することが可能となっています。また、b. 学習用のデータはウェブ上で大量に存在しています。さらに、c. 英語やプログラミングがあまり得意ではないユーザーが多いため、サービスとしての価値も高まります。
GPT-4に何ができないか?
翻って、「英語」と「プログラミング」を除く多くのジャンルでは、GPT-4が一貫した高性能を発揮する領域が(個人的には)見つかっていません。
GPT-4が公開された当初、私たちはもしGPT-4を上手く使えれば(例えば、AutoGPTなどを利用して再帰的に呼び出し続ければ)、それなりの研究活動が可能になるのではないかと期待しました。しかし、GPT-4の推論能力が、マインクラフトをほんの少し遊べる程度のもの(おそらく小学生プレイヤーに劣るレベル)であることが明らかになりました。
さらに、専門分野における知識に関しては、未学習の情報や誤答(ハルシネーション)が目立っています。
ここで、「GPT-4」にとって難しいタスクの共通点をいくつか整理してみましょう。まず第一に、高度で複雑な推論が挙げられます。一問一答形式の回答は得意なものの、より複雑な推論や長い会話では破綻が目立ちます(時に、高度な質問に答えられるよう思われた瞬間、小学生でさえも間違えない初歩的なミスを犯すこともあります)。
これらは、単純なルールや経験則で取り扱うのが難しい、不規則性の高いタスクです。大規模言語モデルの知能そのもの(推論・記憶能力)に制約があるため、回答が難しいと言えます。人工知能側のブレークスルーが必要とされています※。
※解決に向けた具体的な見通しは立っていません。
したがって、GPT-4から単なる延長線上に「人工知能が研究活動を自動化する未来が来る」と考えるのは、いささか乱暴な仮定かもしれません。

GPT-4が難しく感じる第二の項目は、ルールや経験則が通用するものの、学習可能なデータがWeb上に少ないジャンルです。例えば、GPT-4は日英翻訳には得意でも、特定の少数民族の言語への翻訳は困難です。これは純粋にデータの不足から起きています。別の言い方をすると、経験則が通用しやすいタスクに対しては、適切なデータセットを準備・学習させることで、実用レベルのAIを作る可能性が高まります。
実験科学の分野を考慮に入れると、一般的な相談、実験操作の提案(ラボオートメーション)、(一部の)実験結果の予測などに、現水準のAIでもそれなりの性能を発揮できると期待されます。
既存の大規模言語モデルのフレームワークで何ができるか?
実験科学の分野において、現行の大規模言語モデル※がどのような貢献を果たす可能性があるか、例を挙げて考察してみましょう。
(※これは、推論能力だけを考えた時の話です。学習データをどのように準備すべきかという課題については、後述します。)

よろず相談
"よろず相談"とは、研究活動全般にわたる様々な問題に対するアドバイスや解決策を提供するタスクを指します。研究活動は新しい課題への連続的な挑戦でありますが、基礎的なスキル、思考法、そして経験則が存在しています。
実際、大学の研究室に長期間存在すると、学生の問題や相談の多くが、過去の事例と同じまたは類似していることが多いと気付きます。
研究組織は、年々変わる学生たちに対して、これまで積み上げてきた経験的知識を伝えているのです。これを大規模言語モデルによって(少なくとも部分的に)自動化できないか、というのが本着想です。
この過程の変化は、「プログラミングに関する問題を掲示板やウェブサイトで解決する」から「ChatGPTに尋ねる」へとシフトする流れのアナロジーとして、十分に考えられます。
さらに詳しく言うと、研究の世界では、「新しい研究アイデアも、実は多くが既に誰かが思いついていたものである」という経験則があります。もし研究アイデア類も大規模言語モデルに学習させることができれば、文字どおり、「研究のよろず相談」ができるChatbotが現実的になる可能性があります。
(※ハルシネーションに対処することは必要です。学習データを増やして回答の精度を上げる、出典に基づいた回答システム(RAG)の実装、回答内容の自己監査など、対策が考えられます。)
実験操作の提案
GPT-4の得意分野の一つは、プログラミングです。簡単なプログラムであれば、自然言語で指示を与えるだけで必要なソースコードを書いてくれます(例えばテトリスが有名です)。
そのため、科学実験の過程をプログラミングのタスクとして落とし込むことができれば、実験の自動化ができるようになります。
例えば、「◯◯を合成して」と依頼するだけで、実験レシピとロボット装置の制御プログラムを出力することが原理的には可能※となります。
(※しかし、実際の科学実験の過程は複雑であり、言語モデルが提案するプログラムが実際の装置で動作する保証はありません。具体的な実験装置や条件、さらには詳細なプロトコルの情報が必要になることが予想されます。)
実験結果の予測
大規模な言語モデルの登場以前から、実験結果の予測にAIは利用されてきました。マテリアルズ・インフォマティクスやバイオインフォマティクスの分野では、AIを活用して物質の性質や生物学的な情報を予測する研究が行われています。
データセットが十分に提供され、対象となる系の複雑さが制限されていれば、AIは非常に高い精度で結果を予測できる可能性があります。特に、DeepMindが開発したAlphaFoldは、タンパク質の3次元構造を予測することで著名です。この技術は、タンパク質研究の分野で革命的であり、多くの研究者から注目されています。
華々しい成果を上げてきた深層学習の延長線上にある大規模言語モデルは、実験結果を予測する上でも有力なツールとなりうる可能性があります。
ここでのポイントは、従来の予測モデルが純粋に与えられたデータセットだけから解析・予測を行っていたのに対して、言語モデルは「科学知識に基づく推論」が可能であるという点です。
科学知識という背景情報を活かして、少ないデータ数でも信頼性の高い予測を行う(few-shot learning)可能性があります。加えて、数値化が難しい特性や事象に対する分析・予測・提案も可能となります。
※注: 小さなデータベースをもとにした予測モデルの成否について
ただし実際問題としては、小規模データベースからの予測がうまくいくのは、ごく一部のケースに限られるかもしれません。例えば、「データ数は少ないが、科学知識や論理に照らせば高い確からしさで推察できる事象」については、言語モデルによるfew-shot learningがうまく機能する可能性があります。
一方で、「データ数が少なく、原理もよくわからない実験系」に対する予測性能は限定的であることが予想されます。AIが得意とするのは、法則やルールが明確で、人間が労力をかければ可能な作業の代行であり、人間にとっても理解が難しく、かつ観測事例が少ない事象の解析には必ずしも適していないかもしれません。
要するに、大規模言語モデルを含む大半のAIは、専門家に比べて知識・判断能力の両面で劣ることが多いと理解することが重要です。未知の現象に対してAIが人間以上の推測能力を持つと期待するのは、楽観的すぎる可能性があります。
大規模言語モデルと実空間の接続
データベースとモデル構築
前項では、十分な量のデータベースを学習させることができれば、現水準の推論能力を持つ大規模言語モデルであっても、研究のよろず相談や、自動実験システムの制御などを実現できる可能性について説明しました。ここでの実務上の課題は、a. データベースの構築方法、および b. モデルの構築方法、という二点に集約されます。
a. データベースの構築は、多くの方にとって最重要タスクとなります。特定のドメインに関するデータベースは、各専門の方々が主体となって作る必要があります。
特に、ラボオートメーションに関しては、ロボットアームなどによる実空間の制御やセンシング技術がデータベース構築と研究推進のキーとなるはずです。(加えて、組織内に蓄積された実験ノートや文書なども有益な情報源となる可能性があります)
b. モデル構築については、ゼロから基盤モデルを作る、データを追加学習(ファインチューニング)するなどのアプローチがあります。学習コストを考えると、ファインチューニングが有力な選択肢となります。ファインチューニングで知識をどこまで反映させられるかについては、執筆時点でAI業界でもopen questionのようです。このあたりについてはon-goingで研究が進められています。本記事ではこれ以上触れません。
以下、ラボオートメーション(自動化)について考察します。
どこを自動化するか?
広義のラボオートメーションには、AIとロボットによる全自動実験はもちろんのこと、AIナビゲーション型実験(意思決定のみAI)、遠隔操作実験(操作のみロボット)という半自動型の形態などが考えられます。

いずれの形態においても、適切に実験環境をセンシング・記録する環境を整えれば、人間を遥かに凌ぐ精度で実験系を記述できるようになる※と期待しています。
※注: 記録するのが面倒な実験因子≒腕やノウハウ
手作業での実験の問題点の一つは、再現性です。実際、実験論文の相当数を、他者が再現できないという問題がー研究者の間では半ば常識としてー語られています。
再現性を確保できない理由は多岐にわたりますが、その中の一因として、実験プロセスを正確に記録・報告できていない点が挙げられます。
化学合成における具体例を挙げると、使用するガラス器具のサイズ(例: 50 or 500 mLフラスコ)を変更するだけで、液体の対流状態が変わり、結果として収率などが変動します。
しかしながら、実験で使用したガラス器具を詳細に記録することは非常に手間がかかり、そのために実験ノートに記載しない研究者もおり、また論文の実験項で報告されるケースは稀です。
同様に、試薬の添加タイミング(正確な時分秒)や方法、撹拌速度なども実験結果に影響を与えます。これらの未明示の実験因子はしばしば、「実験の腕前やノウハウ」という言葉で取り繕われますが、科学の再現性を考慮する視点では、これらはむしろ避けるべき要素であると言えます。
AI、ロボット、コンピュータは、従順かつ堅実に実験操作や結果を記録・制御することができるため、科学実験のプログラミング化により、再現性の問題を解決する手段となる可能性があります。
全自動実験
全自動実験とは文字通り、科学実験をAI・ロボットによって代行させるタスクを差します。

全自動の実験が比較的進展している分野として、バイオ・創薬系や一部の無機材料系が挙げられます。
一方で、私の専門である有機合成系では、フロー合成装置を一部で使用しているものの、まだ全自動化には程遠い状況です。この差異は、主として実験操作の複雑性と、分野ごとの文化(カルチャー)に起因しています。
例を挙げれば、バイオ系の場合、ロボットアームでマイクロピペットを適切に制御するだけで、一定レベルの実験が可能になります(注意:これは一定の偏見を含むかもしれません)。
また、Opentronsのような自動ピペッティングマシンも既に商用化されています。それとは対照的に、有機合成の場では、多くの複雑で特異な形状を持つガラス器具が頻繁に用いられます。
これらのガラス器具の形状は、五本の指と双腕を持つ人間に最適化されていますが、これが現在主流のロボットアームでの対応を難しくしていることは容易に推察できます。
また、合成されたサンプルを自動的に計測するメカニズムも必須となります。この領域の困難さについては、将来的に別の機会に詳細に記載する予定です。
さらに、探索フェーズの実験では、不測の事態に遭遇した際、実験操作を柔軟に変更する必要が往々にしてあります。この点においても、実装可能な研究はまだ始まったばかりであるという印象を受けます。
とはいえ、完全な自動化がもたらすインパクトは非常に大きく、自動化によってプロセス、構造、物性が関連付けられたデータが得られるようになります。このようなデータを世界中で蓄積・共有することによって、実験科学は飛躍的な進歩と再現性を得ることができる可能性があります。
AIナビゲーション型実験
ラボオートメーションにおける最大の障壁は、おそらくロボットです。AIモデルはムーアの法則に従って急速に進化していますが、ロボットアームの進化が同様に継続的であるとは限りません。この現状を考慮すると、「人間ロボットアーム」(すなわち、実験作業員)を使用するという選択肢が、経済的に合理化される可能性があります。

五感、二本の足、そして滑らかに動く十本の指を有する高性能なロボットアームは、研究レベルでさえ実現されていません。もし商用化されたとしても、初期フェーズではおそらく一台あたり数千万円以上の価格設定になるでしょう。一方で、時給1000円程度で「人間ロボットアーム」を雇うことが可能です。
このため、AIシステムに完全に従いながら実験を行うアシスタントを雇うという選択肢が現実的になる可能性があります。これが非現実的な話のように聞こえるかもしれませんが、Googleマップやカーナビでは、単にAIの指示に従うだけで目的地に到達できます。
ARメガネを使用して指示と記録を行い、マルチモーダルAIを活用することで、この方式は原理的に実現可能と思われます。ファストフード店におけるマニュアル業務のアルバイトなど、すでに定型性の高い業務から実用化の可能性を探ることができそうです。
遠隔実験
AIナビゲートされた実験の対立案として考えられるのが、遠隔実験です。これは、視覚や高度な状況判断に基づく制御を人間の脳で実行し、実験操作はロボットアームによって行う方式です。医学分野では、遠隔医療としてすでに実用化されています。

遠隔実験は、移動コストや安全性が懸念される状況で利点を発揮します。操作者(例えば、専門の医師)が高価である場合や、大型計測設備のようにコストがかかり、簡単に移動できない設備を操作する際にも有用です。さらに、放射光など危険な設備で実験を行う状況でもその価値を発揮します。
一方で、VRゴーグルを通して実行する形態も提案されていますが、操作が予想以上に複雑であるという声もあります。操作装置とロボットメカニズムの精密な構築が、スムーズな実験遂行の鍵となります。
遠隔実験のもう一つのメリットは、実験操作に関するデータの蓄積が可能であることです。人間によって行われる実験のプロセスをAIに学習させることで、将来的には実験操作を自動化する道が開かれる可能性があります。
まとめ: ラボオートメーションの展望
大規模言語モデルやロボット技術の現状と将来性を考慮して、大胆かつ慎重に、ラボオートメーションに向けた基本的な検討を進めていくことが極めて重要です。

完全な自動実験に焦点を絞るのではなく、部分的に人間の四肢や脳を活用するオプションも持つことが、柔軟かつ実用的なアプローチとなると考えられます。

この記事が気に入ったらサポートをしてみませんか?