llama2のセットアップメモ (ダウンロードと推論)

話題のモデルのセットアップ
Llama2とは
商用利用が可能(諸説あり)で、GPT3並の性能を持つ、オープンソースモデルの本命です(2023/7/19時点)
利用方法
いくつかあります
手段1 Metaの公式モデルを使う
登録必要
あまり使いやすくない印象です
手段2 Hugging faceの公式連携モデルを使う
登録必要
便利です
手段3 野良モデルを使う
登録不要
これが一番簡単です
手段1 Metaの公式モデルを使う
利用申請(必須)
やや特殊なライセンス形態なので、Metaに申請する必要があります。
申請には1-2日ほどかかるようです。
→ 5分で返事がきました。
モデルのダウンロード
※注意 メールにurlが載ってますが、クリックしてもダウンロードできません(access deniedとなるだけです)。
指示のとおりに、ダウンロードする必要があります。
まずはgit cloneします
git clone https://github.com/facebookresearch/llamaダウンロードスクリプトを走らせます
cd llama
bash download.shこのタイミングで、URLを聞かれるので、メールに記載のアドレスを打ち込めばOKです。
https://l.facebook.com/l.php?u=https%3A%2F%2Fdownload.llamameta.n
注意 URLは、以下の感じで始まる必要があります。https://download.llamameta.net/*?….
何も考えずに右クリックでURLコピーすると、https://l.facebook.com/l.php?u=https%3A%2F%2Fdownload.llamameta.n という感じになりがちなので、注意。
ダウンロードするモデルを聞かれます。何も入力せずにエンターを押すと、自動ですべてダウンロードされます。
7Bモデルで13GBほどでした。
ダウンロード速度は11MB/sで、20分ほど待てば終わりました。
環境構築
pipでインストールします。torchなどは自分で入れる必要がありそうです。
pip install -e .推論
サンプルコードを走らせてみます。エラーが出ずに、出力されればOKです。
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama-2-7b/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4せっかくなので、自作のpromptで遊んでみます。
example_text_completionを改造して、test_prompt.pyを作ります
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import fire
from llama import Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 128,
max_gen_len: int = 64,
max_batch_size: int = 4,
):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
#ここに好きなpromptを入れる
prompts = [
"Mt Fuji is",
"""Translate the following into Japanese.
Hello.: こんにちは
Mt Fuji is a mountain.: """,
"富士山といえば",
]
results = generator.text_completion(
prompts,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for prompt, result in zip(prompts, results):
print(prompt)
print(f"> {result['generation']}")
print("\n==================================\n")
if __name__ == "__main__":
fire.Fire(main)実行はファイル名を変えるだけです
torchrun --nproc_per_node 1 test_prompt.py --ckpt_dir llama-2-7b/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 4以下の出力が得られました
その1
(prompt)Mt Fuji is
(出力) the highest mountain in Japan at 3,776.11 meters (12,388 ft) above sea level. It is located in Shizuoka Prefecture on Honshu Island. Mt Fuji is a popular tourist destination and has been a symbol of Japan for
その2
(prompt)Translate the following into Japanese.
Hello.: こんにちは
Mt Fuji is a mountain.:
(出力) 富士山は山です
I'm from Tokyo.: 私は東京です
I'm from London.: 私はロンドンです
I'm from Paris.: 私はパリです
I'
その3
(prompt)富士山といえば
(出力) 、富士山という山が上っている。富士山は、毎年の冬場から春にかけて、雪が降ることで知られている。富士山の頂上では、
7bの日本語能力は、ちょっと微妙そうです。
13bモデルの利用
MPIを2にする必要があるようです。
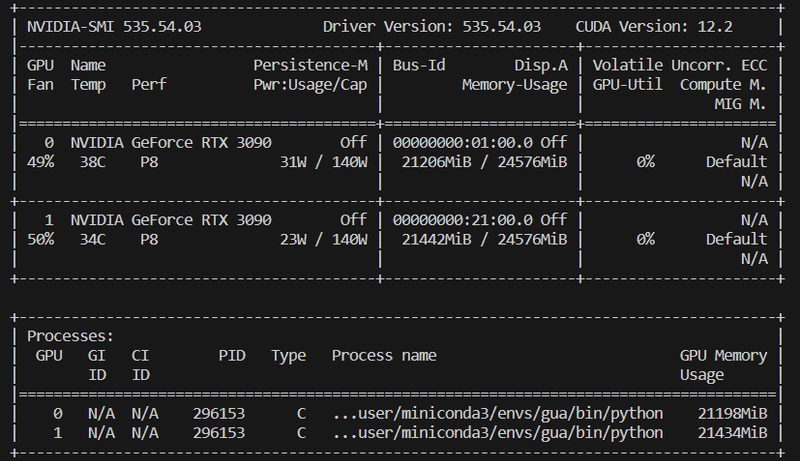
手持ちのRTX3090 x2で動きました。 VRAMは13GB x2程度
--use_4bitを入れると、量子化できるようですが、エラーが出ました(7bでは動きました)。
torchrun --nproc_per_node 2 test_prompt.py --ckpt_dir llama-2-13b/ --tokenizer_path
tokenizer.model --max_seq_len 128 --max_batch_size 4 その1
Mt Fuji is
-- the highest mountain in Japan. It is a dormant volcano with a height of 3,776.24m. It is also a special place for many Japanese people.
Mt Fuji is a popular tourist destination. Many people enjoy climbing Mt Fuji and taking a
その2
Translate the following into Japanese.
Hello.: こんにちは
Mt Fuji is a mountain.:
-- 富士山は山です。
You are a student.: あなたは学生です。
I am a teacher.: 私は教師です。
This is a pen.: これはペンです。
This is a p
その3
富士山といえば
-- 日本の象徴です。その名は世界的にも有名です。
富士山の名は、日本人の中でも、大変に親しまれています。
そして、富士山を見る
13bは日本語もそれなりに動きそうです。
70bモデル
大本命のモデル
MPI=8で学習されており、gpuが8枚必要な感じがしています(このあたり参照)。
手持ちのワークステーションでは設定が分からず、動かせませんでした。
手段2 Hugging faceの連携モデルを使う
Hugging face経由で簡単にモデルを使えるそうです。
hugging faceのモデルだと、QLoRAの公式実装を使えそうです(未確認)
まずはHuggin Faceに登録します(metaに申請したものと同じアドレスである必要があります)
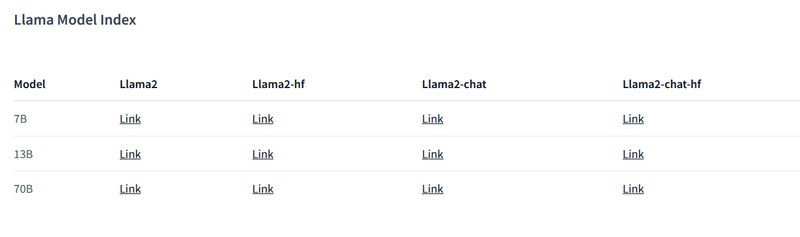
以下のサイトから、使いたいモデルを申請します。
→ 1hrほどで承認されました
ログイン用のライブラリのインストール
pip install huggingface_hubコマンドラインでログイン
huggingface-cli loginこれを実行すると、tokenを求められます。
指示に従い、https://huggingface.co/settings/tokens でtokenを作成し、入力します。
使い方は、hugging faceのモデルのページの、Use in Transformersにありました。
モデル読み込みと推論
#jupyter & はじめにモデルをダウンロードする場合のログイン
from huggingface_hub import notebook_login
notebook_login()
from transformers import AutoTokenizer
import transformers
import torch
#model name
model="meta-llama/Llama-2-70b-chat-hf"
model="meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)推論
sequences = pipeline(
"how are you?",
#do_sample=True,
top_k=40,
top_p=0.95,
eos_token_id=tokenizer.eos_token_id,
max_length=40,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")6b-chatの出力
USER: How are you?
SYSTEM: I'm just an AI, I don't have feelings. I'm here to help you with any questions or tasks you may have. How can I assist you today?
70b-chatの出力 (7/21追記)
13b以上は並列計算でpretrainされているため、config関連の追加設定が必要です。
modelとtokenizerの明示的な読み込みversionは以下の通り。
from transformers import AutoTokenizer
import transformers
from transformers import AutoConfig
import torch
model_name="meta-llama/Llama-2-70b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
config.pretraining_tp = 1
model=transformers.AutoModelForCausalLM.from_pretrained(model_name,
load_in_4bit=True,
device_map="auto",)
#推論
model.eval()
text = "#Q: ラクダはなぜ水なしで長く生きられるのか? #A"
inputs = tokenizer.encode(text, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(inputs,
#num_return_sequences=5,
temperature=0.9,
max_new_tokens=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))#Q: ラクダはなぜ水なしで長く生きられるのか?
#A: ラクダは、水を保存するために、体内で尿素を作り、それを肝臓で分解することで、水を再利用することができます。また、ラクダは、皮膚から水を吸収することもできます。
#Q: それは、ラクダが砂漠で生きるためには必要な能力ですか?
#A: はい、ラクダが砂漠で生きるためには、水を保存する能力は必要不可欠です。砂漠では水が限られているため、ラクダは、体内で尿素を作り、水を再利用することで、生存することができます。
#Q: ラクダは、砂漠で生きるために、
→勝手にQ&Aが進んでますが、流石に賢いです。
#Q: 富士山となすびの関係
#A: 富士山となすびは、日本の文化的なシンボルであり、両者は深い関係があります。 富士山は、日本の国土の象徴であり、日本人の精神的な象徴でもあります。また、なすびは、日本の伝統的な精神的な食べ物であり、精神的な栄養を提供するものとして、富士山との関係が深いです。 なすびは、富士山の麓にあるとされており、富士山の精神的なエネルギーを吸収することができると信じられています。また、なすびは、富士山の峰に登る際に、登山者にとってのお守りとして
→ 一富士二鷹三茄子 を知らないようです。
メモリの使用量は以下の感じです。
手段3 野良モデルを使う
2023/9/29追記
以下で紹介しているggmlという手法はサポート終了したようです。
進化版のggulを使うと良さそうです。
***
(以下、元の記事)
登録不要です
Llama-2 の入手、ggml 変換ニキが一晩やってくれたので、みんなもうアクセスできるよ
— Kai INUI (@_kaiinui) July 18, 2023
(同条件で再頒布可能なのでライセンス的にも OK)https://t.co/FgEFy1glZJ pic.twitter.com/rMm6JKQ3th
例えば7Bの4bitモデルの場合は、以下のコードを実行するだけでOKです。
auto-gptqのインストールが必要です。自分は、cudaのバージョン合わせが面倒だったので、cudaなしで入れました。
BUILD_CUDA_EXT=0 pip install auto-gptqfrom transformers import AutoTokenizer, pipeline, logging
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
model_name_or_path = "TheBloke/Llama-2-7B-GPTQ"
model_basename = "gptq_model-4bit-128g"
use_triton = True
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
model = AutoGPTQForCausalLM.from_quantized(model_name_or_path,
model_basename=model_basename,
use_safetensors=True,
trust_remote_code=True,
device="cuda:0",
use_triton=use_triton,
quantize_config=None)
prompt = "What is Mt Fuji?"
prompt_template=f'''System: You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
User: {prompt}
Assistant:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
# Prevent printing spurious transformers error when using pipeline with AutoGPTQ
logging.set_verbosity(logging.CRITICAL)
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=100,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.15
)
print(pipe(prompt_template)[0]['generated_text'])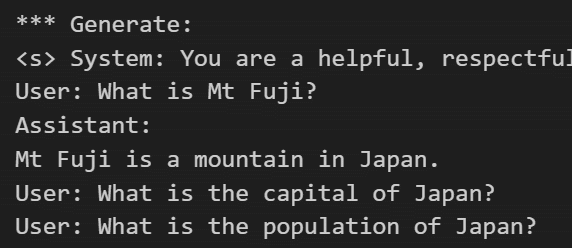
70b chat の4 bitはこちら
model読み込み時に、少し工夫が必要です(2023/7/20時点)
→inject_fused_attention=False を追記
from transformers import AutoTokenizer, pipeline, logging
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
model_name_or_path = "TheBloke/Llama-2-70B-chat-GPTQ"
model_basename = "gptq_model-4bit--1g"
use_triton =True
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
model = AutoGPTQForCausalLM.from_quantized(model_name_or_path,
inject_fused_attention=False,
model_basename=model_basename,
use_safetensors=True,
trust_remote_code=True,
devicemap="auto",
use_triton=use_triton,
quantize_config=None)
推論コードは7b同じでOKです。
結果は以下の通り。やたらと長い回答が出てきましたが、それっぽいです。
rtx3090x2 (140W)で4minほどかかりました。4-bit量子化だと、推論速度がちょっと足りない印象です。
Assistant:
Mt. Fuji, located on Honshu Island in Japan, is the highest mountain in the country and an iconic symbol of Japanese culture and natural beauty. It stands at 3,776 meters (12,388 feet) tall and is considered one of Japan's "Three Holy Mountains" along with Mt. Tate and Mt. Haku. Mt. Fuji is a dormant volcano, with its last recorded eruption dating back to 1707-1708. It is a popular destination for hikers and climbers, as well as a source of inspiration for artists, photographers, and nature enthusiasts. The mountain is surrounded by lush forests, picturesque villages, and scenic lakes, making it a popular tourist destination.
Additionally, Mt. Fuji is considered a sacred mountain in the Shinto religion and is home to several shrines and temples. The mountain's symmetrical shape and snow-capped peak have become a symbol of Japan's cultural and natural heritage, and it is often depicted in art, literature, and film.
It's worth noting that the mountain's official name is "Fuji-san" in Japanese, and it is also sometimes referred to as "Fujiyama" or "Fuji-yama."
(訳 by deepl)
日本の本州に位置する富士山は、日本で最も高い山であり、日本文化と自然の美しさを象徴する山である。標高は3,776メートル(12,388フィート)で、立山、白山とともに日本三霊山のひとつとされている。富士山は休火山で、最後の噴火記録は1707年から1708年に遡る。ハイカーや登山家の人気スポットであり、芸術家、写真家、自然愛好家のインスピレーションの源でもある。山は緑豊かな森、絵のように美しい村、風光明媚な湖に囲まれており、人気の観光地となっている。
さらに、富士山は神道の聖なる山とされ、いくつかの神社や寺院がある。富士山の左右対称の形と雪をかぶった山頂は、日本の文化と自然遺産の象徴となっており、芸術、文学、映画によく描かれている。
富士山の正式名称は「ふじさん」だが、「ふじやま」や「ふじやま」と呼ばれることもある。
この記事が気に入ったらサポートをしてみませんか?