一部のGPT3.5系は、選択肢問題をきちんと解けないかも、という検証

はじめに
最近は、大規模言語モデル(LLM)の理解力や制約をできるだけ正確に把握し、適切に訓練させるための手法を考えることにハマっています。
昨日の記事では、日本語を喋るLLMの半数近くが、単純な選択肢問題にさえ、適切に回答できないことを記しました。
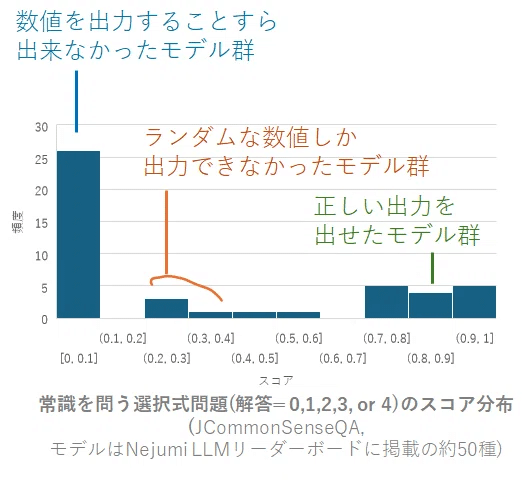
一番左の群に属します
本記事では、賢いと評判の商用モデルGPT3.5/4の、ユーザーに対する指示の遵守性能について、評価していきます。
タスク
解かせる問題
llm-jp-evalベンチマークに含まれるJCommonSenseQAと呼ばれるタスクから適当に選んだ以下の問題を、種々のバージョンのGPTに解かせてみます。
以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。
### 指示:
質問と回答の選択肢を入力として受け取り、選択肢から回答を選択してください。なお、回答は選択肢の番号(例:0)でするものとします。 回答となる数値をint型で返し、他には何も含めないことを厳守してください。
"""
### 質問:電子機器で使用される最も主要な電子回路基板の事をなんと言う?
選択肢:0.掲示板,1.パソコン,2.マザーボード,3.ハードディスク,4.まな板
回答に必要な能力
本問題を適切に回答するためには、ざっくり2つの能力が必要です。
A. 回答に必要な知識を持っている
B. きちんと指示を理解して遵守する
今回の問題自体は、わりと簡単ですので、さすがにGPT3.5/4であれば、A.回答能力は有しているはずです。
むしろ、モデルにとって鬼門となるのは、「きちんと指示を理解して遵守する」というタスクです。
回答となる数値をint型で返し、他には何も含めないことを厳守してください。という指示があります。回答を単語で答えてしまったり、「2.マザーボード」のような、不要な情報を含めた出力は誤答とみなされます。
指示の中には、「回答は選択肢の番号(例:0)でするものとします」のような、回答例も示されているので、多くの日本語話者にとって、この指示を守るのは容易なはずです。
検証したモデル
24/4/3現在、OpenAIのサイトに記載されている、種々のバージョンのGPTで回答をさせました。コードもシンプルです。
from openai import OpenAI
client = OpenAI()
instruction="""以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。
### 指示:
質問と回答の選択肢を入力として受け取り、選択肢から回答を選択してください。なお、回答は選択肢の番号(例:0)でするものとします。 回答となる数値をint型で返し、他には何も含めないことを厳守してください。
"""
input_str="""### 質問:電子機器で使用される最も主要な電子回路基板の事をなんと言う?
選択肢:0.掲示板,1.パソコン,2.マザーボード,3.ハードディスク,4.まな板"""
def ask(model,instruction,input_str):
response = client.chat.completions.create(
model=model,
temperature = 0,
messages=[
{"role": "system", "content": instruction},
{"role": "user", "content": input_str}
],
)
result=(response.choices[0].message.content)
return result
model_list="""
gpt-4-0125-preview
gpt-4-turbo-preview
gpt-4-1106-preview
gpt-4-0613
gpt-4-32k
gpt-4-32k-0613
gpt-3.5-turbo-0125
gpt-3.5-turbo-1106
gpt-3.5-turbo-instruct
gpt-3.5-turbo-16k
gpt-3.5-turbo-0613
gpt-3.5-turbo-16k-0613
"""
model_list=model_list.split("\n")
model_list=[m for m in model_list if m]
res_dict={}
for model in model_list:
if model in res_dict:
continue
try:
res=ask(model,instruction,input_str)
except Exception as e:
print(e)
res="[error]"
print(model,res)
res_dict[model]=res結果
結果は以下の通りとなりました。一部のモデルは使用不能だったので、[error]としています。
'gpt-4-0125-preview':'2',
'gpt-4-turbo-preview':'2',
'gpt-4-1106-preview':'2',
'gpt-4-0613':'2',
'gpt-4-32k':'[error]',
'gpt-4-32k-0613':'[error]',
'gpt-3.5-turbo-0125':'2',
'gpt-3.5-turbo-1106':'2',
'gpt-3.5-turbo-instruct':'[error]',
'gpt-3.5-turbo-16k':'2.マザーボード',
'gpt-3.5-turbo-0613':'2.マザーボード',
'gpt-3.5-turbo-16k-0613':'2.マザーボード'
GPT-4系のモデル
すべてのケースで、正しい答え(2)が得られました。
GPT-3.5系のモデル
23年11月以降のモデル (0125,1106)では、正しい答え(2)が得られました。
それより前のモデル(0613系)では、誤った答え(2.マザーボード)が得られました。
考察
GPT-3.5-0613は基本的な日本語の指示を理解し、遵守できなかった
商用モデルであるGPT-3.5/4であっても、一部の古いバージョン(gpt-3.5-turbo-0613系)では、今回のタスクを適切に解けない事例があるということがわかりました。
意味としての答え(2.マザーボード)は合っていますので、これらのモデル群は、「数値のみを回答しなさい」という、人間には簡単に思える指示をきちんと理解し、遵守できなかったことを意味しています。
GPT-3.5-turboのモデルサイズは公開されていないものの、前身のGPT-3は175Bであることを踏まえると、それなりに巨大なモデルであることは推察*されます。商用規模の超大型モデルでさえ、基本的な日本語の理解・遵守能力を獲得するのが困難であるという事実は、モデルの利用や開発にあたって、十分に留意が必要があるように思います。
*turboという名称がついていることから、何らかの軽量化がなされている可能性はあります。一時期は、20bという噂も流れましたが、流石に違うだろうという憶測が主流になっています。
なぜ、GPT-3.5の後継バージョンは、指示を守れるようになったのか?
GPT-3.5であっても、1106以降のバージョンでは、正しい出力を出せるようになりました。一連のバージョンアップは、モデル設計そのものではなく、主に訓練データの追加修正に由来するものであると、一般には考えられています。
バージョンアップによって、モデルの思考能力そのものが劇的に改善したとは考えにくいですので、「より忠実に指示を守れるようになるための訓練」を経て、回答精度が上がったと判断するのが妥当そうです。
どのような改善操作が行われたのかは未公開のため、これ以上の考察は難しいですが、いずれにせよ、性能向上のために、ファインチューニングが極めて重要な役割を果たしたはずです。
まとめ
商用モデルであるGPT-3.5でさえ、「数値を選んで回答する」というシンプルなタスクをこなすのが難しいことを例示しました。
それよりも小さなサイズのなローカル系大規模言語モデルにおいては、指示を守らせるための難易度が、圧倒的に上がるはずです。
(少なくとも10b程度のサイズの)ローカルモデルに対して当該指示を守らせるための実質的に有効な手段は、数百件以上の「選択肢問題」を実際に学習させることであり、(筆者が検討した)他の手法は十分な実効性を持たなかった、という検討結果も出ています。
小規模なモデルで実用的な性能を発揮させたいのであれば、
・モデルの能力を過信したり、漫然と指示データセットを準備するのではなく
・モデルに冷静にできる/できないことを見極め
・必要な訓練データの種類や量を精査しながら
ファインチューニングを行う必要があるかもしれません。
この記事が気に入ったらサポートをしてみませんか?