
「Google Colaboratory」を使って簡単にディープラーニングで画像認識ができるチュートリアル

チュートリアルの内容が書籍になりました
以下記事参照ください。
はじめに
以下のようなツイートをしたら、かなり需要がありそうだったので、作ってみました。
ちなみに上記のツイート「Google Colobratory」のとこ「Google Colaboratory」の誤字です。すみません
また、たくさんのチュートリアルがセットになったマガジンの方がお得なので、他の機械学習のチュートリアルも興味ある方は、以下も検討してみて下さい。
本チュートリアルで出来るようになること
ディープラーニングを使って、自分だけの画像認識の学習モデルを作る方法が学べます。
具体的には、学習させたい画像の収集(スクレイピング)や、画像の前処理(ラベル付け)、学習、判別を行います。
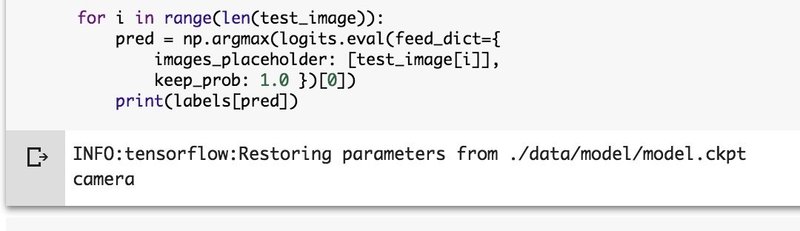
本チュートリアルでは、例としてたくさんのカメラと犬と猫の画像を学習させた後、以下のような画像を見せて判別を行います。

以下のようにカメラ(camera)と判別されています。
このような画像判別の技術を使うと、画像を元に何かの良し悪しを判定する機械を作ることができます。例えば、世の中には、ディープラーニングの画像判別を使ってキュウリの選果(良否判定)の自動化に取り組んでいる農家さんもいらっしゃいます(詳細は、以下記事参照下さい)。
また、学習のとき精度を上げる方法に関して、実際に試行錯誤しながら重要なポイントを理解します。
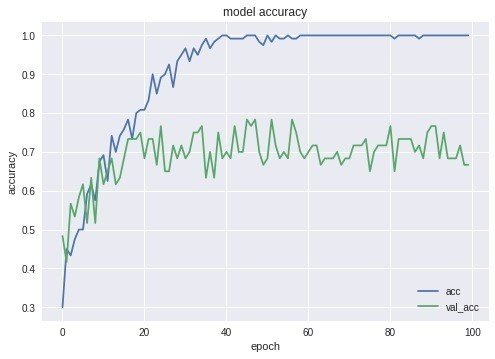
以下は学習モデルの性能を表す精度のグラフです。緑の線が実際のテストデータの精度ですが、7割程度しか出ていません。
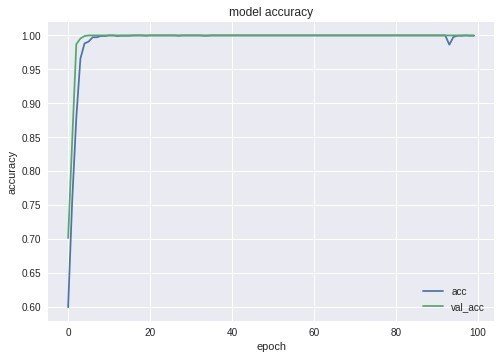
これを様々なテクニックを使うことでほぼ100%近くまで精度を高めるところまで実践します。
また、学習に際しては「Google Colaboratory」のGPUを使って、学習を10倍以上高速化するテクニックも身につけられます。
応用例としては、「Google Colaboratory」で学習させた学習モデルを自分だけのモデルとしてダウンロードして、PCやRaspberry Pi上で使用して、リアルタイムに認識させる方法に関しても学習します(応用例に関しては、環境構築も必要になる、少し上級者向けの内容となることご了承ください)。

まとめると、本チュートリアルで得られるものは以下となります
- 環境構築不要で、ディープラーニングを使って自前データで画像認識を実現する方法を身につけられます
- 「Google Colabratory」でGPUを活用して学習を高速化するテクニックを身につけられます
- 実際にディープラーニングの学習の試行錯誤を通して、精度向上の取り組み方・勘所がわかります
変更履歴
2019/11/12 Raspberry Piのセットアップ方法をRaspbian Buster with desktop 2019-09-26に合わせて修正
2019/06/04 KerasをTensorFlowに統合されたKerasに変更・Raspberry Piのセットアップ方法修正
2019/02/19 TensorFlowのバージョンアップに伴う修正を実施
2018/06/02 コードのミス修正・分かりにくいところを修正
2018/08/12 スクレイピングに関しての注記追記
2018/10/01 スクレイピングに関してプログラム修正
本チュートリアルの特徴
「Google Colaboratory」というGoogleが提供する無料の機械学習環境を使うことで、難しくて煩雑な環境構築に手間をかけることなく、手軽に最先端の画像認識技術を実際に作りながら学ぶことができます。
機械学習(ディープラーニング)のチュートリアルは、世の中に多く存在するのですが、個人的には以下の点が不満でした。
- 環境構築が大変で力尽きてしまう。試してもバージョン違いの問題で動かない
- MNIST(手書き文字認識)の学習をしたけど、これが何をやっていて何が嬉しいのかさっぱり分からない
- ありあわせのデータセットを学習しても面白くない
上記問題に対して、本チュートリアルでは、ディープラーニングの花形と言える画像認識を題材に、以下の対策で解決します。
- 「Google Colaboratory」を使うことで環境構築不要ですぐ学習に入れる。動作確認済みのコードへのリンクも付属
- 画像認識という分かりやすい題材を通して、学習判別するのでやっていることや、応用例がイメージしやすい
- 自前のデータを学習することで、自分だけの学習モデルを構築
また、本チュートリアルは、機械学習・ディープラーニングに関して理論的な説明は最小限に留め、実践に重きを置いています。特に機械学習に必要な、「教師データの収集」「学習によるモデル生成」「モデルを使った判別」を、極限まで手軽に実現できることを追求しています。
極端な話、チュートリアル通り、コピペして実行すれば誰でも自前データを用いた画像認識モデルを作れてしまいます。
理論で力つきるより、実践した上で自分の不足分の理論を捕捉するという、ボトルアップ的な内容になっています。まずは興味を持ってもらって、その後自分で足りないと思った理論を補足してもらうのが良いかなと考え、このような構成にしました。理論に関しては、最後におすすめの参考書籍やサイトを紹介させていただきます。
本チュートリアルの想定読者
本チュートリアルは、「今まで概要や理論だけ勉強したけど、身についている実感がなかった人」「実践しようとしたけど、途中で挫折して諦めてしまった人」「とにかくディープラーニングを使って自分だけの画像認識のモデルを作りたい人」におすすめの内容となっております。
プログラム言語はPythonを用いますが、Pythonに関しての詳しい説明は本チュートリアルでは行いませんので、内容をきちんと理解したい人は自習が必要となります。あくまで本チュートリアルは興味を持つきっかけと位置付けて下さい。
また、初心者向けなので機械学習ガチ勢の方は是非生暖かく見守っていただけましたらと思います(笑)
スクレイピングに関して
Yahoo!画像検索の仕様が変わり、スクレイピングができなくなっていたのを、プログラム修正により再度対応しました。
注記:
本内容は、筆者の環境で動作確認はしていますが、必ずしも読者全ての環境で動くことを保証するものではないこと、本内容がソフトウェアのバージョン変更や、開発中止により再現できなくなる可能性があり、永続的サポートできないことご了承下さい
もちろん、フィードバックは歓迎しますし、動かないケースがある場合は、最大限誠心誠意をもって修正対応させていただきます
また、本noteで用いている「Google Colaboratory」などの1部のWebサービスは、サービス提供社の都合で中止になる可能性あり、その際の保証はできないことご了承下さい。
本noteで紹介しているプログラムは、読者の皆様が自由に使用・改変が可能です。是非色々応用して下さい。応用例は、このnoteでも積極的にご紹介したいと思いますので、もしよろしければコメントやtwitter等で教えて下さい。
本チュートリアルの目次
本チュートリアルの目次です。
- ディープラーニングの概要
- 使用するディープラーニングのフレームワークに関して(Keras + TensorFlow)
- Google Colaboratoryの使い方
- 教師データ収集(スクレイピング)
- ラベル付け
- 学習(学習モデル生成)
- 判別(学習モデルの活用)
- GPUを使用した学習の高速化
- ニューラルネットワークの変更による効果確認
- 画像のN増しによる効果の確認
- 学習したモデルのダウンロード
- 応用例(PCやRaspberry Piでの学習モデルの活用)
- 自前の教師データでの学習
- うまくいかない人のために
- おすすめ参考書籍・参考リンク
ディープラーニングの概要
本記事では、ディープラーニングという機械学習分野の一手法を用いて画像認識を行います。
「ディープラーニングとか機械学習とか人工知能とか最近よく聞くけど、何がどう違ってどういう関係なの?」
という方は、以前ブログ記事を書いたので詳しくは以下参照ください。
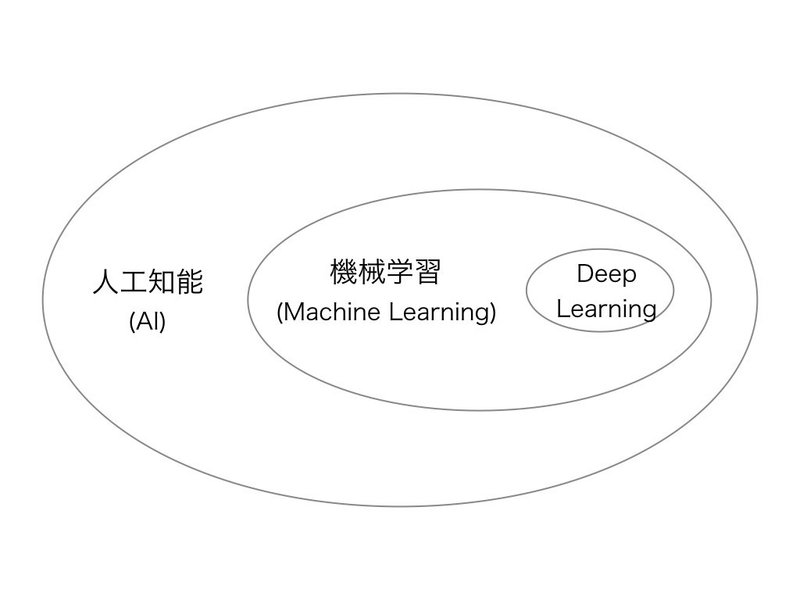
一般的には、人工知能と機械学習とディープラーニング(Deep Learning)は以下のような関係になります。
人工知能に関しては、そもそもはっきりした定義はないので、そんなに真剣に考える必要はないです(と自分は思っています)。「人工知能=ディープラーニング」という人や「人工知能=最先端の技術」という人もいたりしますが、基本的にはその人がポジショントークとして都合良い定義をしているだけなので、あまり深く考えないようにしましょう(当たり前ですが、「人工知能=ディープラーニング」って言ってる人のほとんどがディープラーニングでビジネスしています)。一般的には、人工知能は、何らかの入力に対して知的振る舞いをする(出力する)プログラムという非常に広い意味で使います。つまりほとんどのプログラムは人工知能と言っても大丈夫なのです(と私は思っています)。
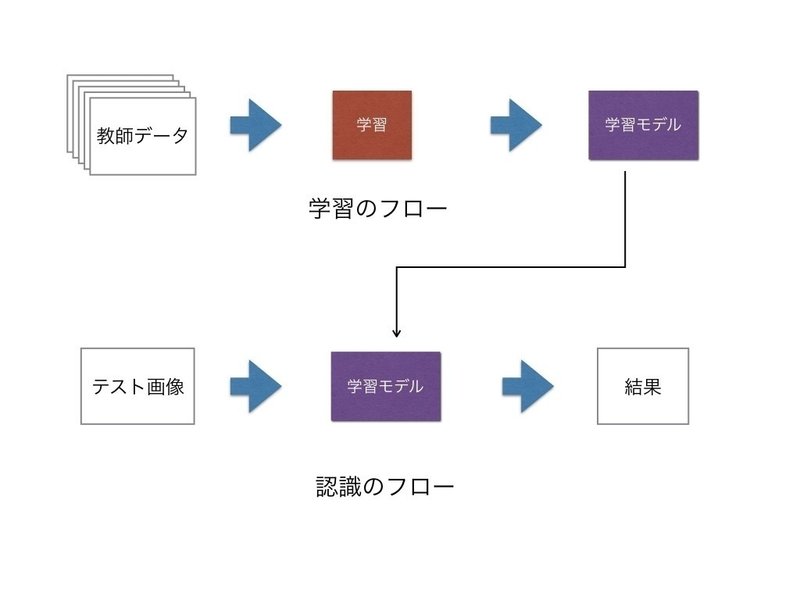
機械学習というのは、入力されたデータ(機械学習の分野では教師データと言います)を元に学習モデルを生成する手法のことです。多くのデータを元に学習モデルを生成すると、未知のデータに対しても推測(判別)をすることができるようになります。
今回行う画像認識を例にすると、あらかじめ大量の猫の画像を猫として、大量の犬の画像を犬として学習させてモデルを生成することで、犬か猫の写真を見せると学習モデルを元に、結果を判定してくれます。流れとしては、以下の図のようになります。
今回は代表的な画像認識の例で説明しましたが、機械学習の分野は広く、今回のように正解がわかっている「教師あり学習」と呼ばれる分野の他に、正解の分からない「教師なし学習」や、ロボットの制御などに使われる「強化学習」といった分野もあります。今回のチュートリアルでは扱いませんが、興味ある方は是非そちらも調べてみて下さい。
そして、ディープラーニングは機械学習の分野の数ある手法の中の1つとなります。では何故、ディープラーニングが近年、話題を集めているかというと以下の図の通り、初期の人工知能も、従来の機械学習も人間が頑張って設計している部分が非常に大きかったのです。
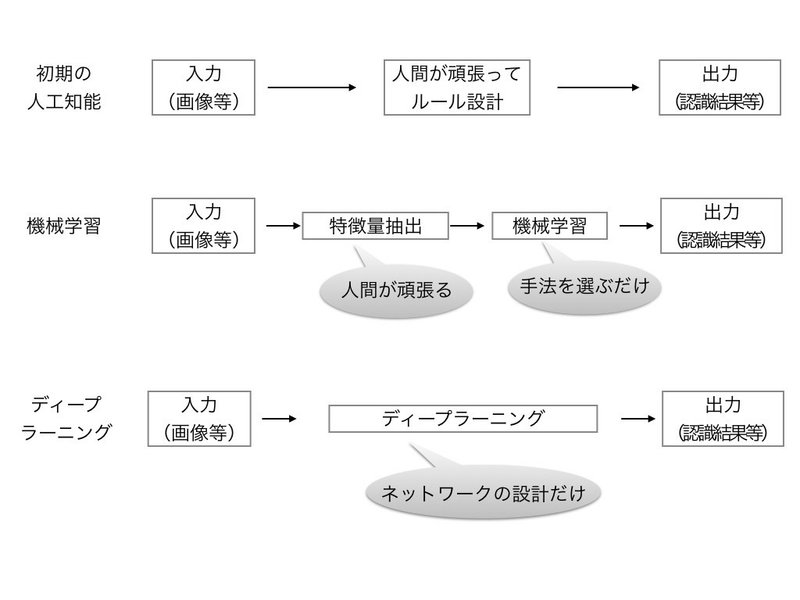
例えば、先ほどの犬と猫の画像認識の例だと、犬の特徴、猫の特徴を抽出するような画像フィルタを職人のような人が一生懸命設計する必要があったのです。極端な話、別の動物(例えばウサギ)が追加されたら、その動物に合わせてまた画像フィルタを設計する必要があったのです。
ところが、ディープラーニングだと、画像認識のためのネットワークを設計すれば、動物が増えてもその動物の写真をたくさん学習させてやれば、自動的にその動物に合わせた画像フィルタも含めて学習してくれるようになったのです。
人間なら簡単にできることですが、これを機械にやらせるというのが、研究者の長い間の悲願で、それをようやく実現できるようにしたのがディープラーニングの技術なのです。
使用するディープラーニングのフレームワークに関して(TensorFlow)
ディープラーニングのフレームワークは、非常にたくさんあるのですが、代表的なものをとても簡単にまとめると以下となります。

要は、TensorFlowというGoogleのフレームワークが事実上のスタンダードです。最新の研究も、TensorFlowを使った実装例が公開されることが多いので(最近はPyTorchも増えて来ていますが)、TensorFlowを覚えておくのがベターです。
事実、TensorFlowは、2018年中旬時点で、arXivという機械学習・ディープラーニング系の論文投稿サイトで使用されているフレームワークのうちで1番使用されているフレームワークとなります。
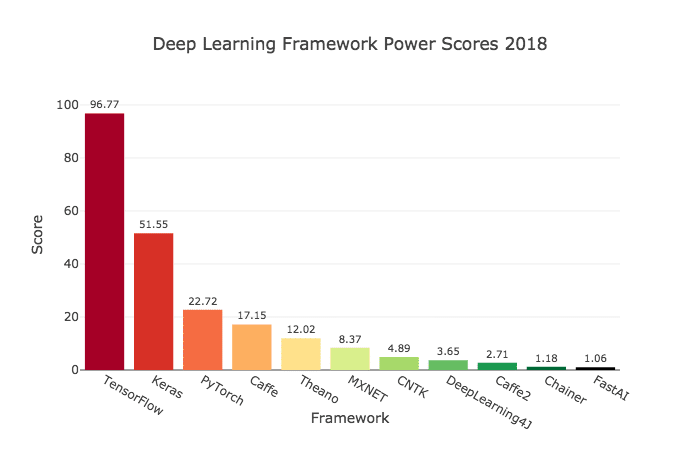
(上記グラフは、https://keras.io/ja/why-use-keras/ より引用)
ただ、TensorFlowは、色々できる分プログラムを書くのが難しいです。そのため、本チュートリアルではKerasというTensorFlowを簡易に使うためのラッパープログラムを使用します。もともとKerasは単独のソフトだったのですが、現在KerasはTensorFlowに統合されてTensorFlowのみインストールすれば使えるようになりました。本チュートリアルでも、TensorFlowに統合されたKerasを使います。Kerasを使うことで、TensorFlowのときに比べて非常に簡単にプログラムを作成することができます。
上記の人気のフレームワークのグラフでもKerasは、2番目に人気のフレームワークです。また、KerasはTensorFlowとの組み合わせで使われることが多いので、1,2番含めるとTensorFlowが非常に多くのシェアを持っていることが分かると思います。そのような理由で本チュートリアルではTensorFlow + Kerasの組み合わせでディープラーニングに取り組みます。
Google Colaboratoryの使い方

この記事が気に入ったらサポートをしてみませんか?