二次元画像の口を音声に合わせてパクパクさせたい

まず結論から言うと、SadTalker を利用して音声に合わせパクパク(リップシンク)できた。
SadTalker はリップシンクのみならず、顔や表情も音声に連動できる(README の GIF 見ると分かりやすい)。
実際に使ってみた結果がコレ。織田信長がパクパクしとる!


パクパク動画の作り方
手元に機械学習できる環境なくても問題なし。
リポジトリに実行環境(無料)への導線が 2 つ準備されている。
Hugging Face:機械学習モデルのホスティングサービス
Google Colab:Jupyter ノートブックの実行環境
自分が試す限り、Hugging Face では一生エラーが出たので今回は Colab にて説明する。
環境構築からパクパク動画取得まで全部で 5〜10 分程度で終わった(もちろん音声ファイルの長さ等にもよるだろうけれど)。
STEP1. 事前準備
喋らせたい画像と、適当な音声ファイル(mp3 や wav)を準備する。
音声ファイルはもちろん日本語で OK。
STEP2. Colabを立ち上げる
公式リポジトリの README から Colab を立ち上げると、初期画面はこんな感じ。
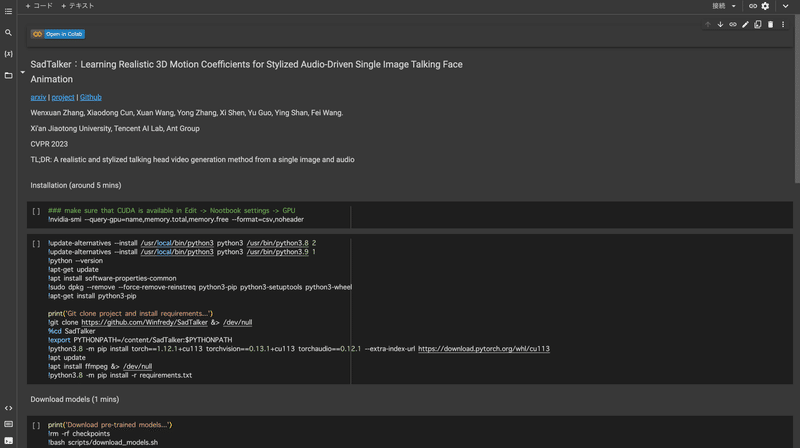
Jupyter ノートブック形式のセルが並んでいるのでこれを逐次実行していく。
STEP3. Colab 内に SadTalker 環境を構築
セルを上から順に実行し、環境内に SadTalker の GitHub リポジトリをクローンしたり、モデルをダウンロードしたりする。
とりあえず何も考えずに Installation (around 5 mins) と Download models (1 mins) の項目を Shift + Enter で実行。
STEP4. パクパク動画を生成(完成)
STEP3 が完了した状態で Colab の左ペイン / フォルダアイコンを開くと SadTalker フォルダが生まれている。
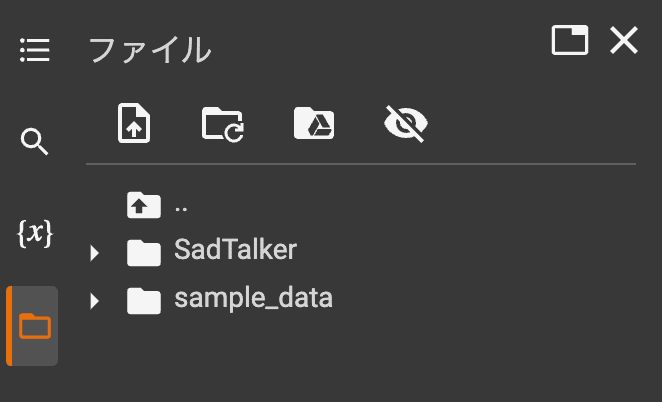
SadTalker フォルダの examples/source_image に画像を、examples/driven_audio に音声ファイルを格納する。
その後下記セルに画像ファイル名等を入力して実行。
# selected audio from exmaple/driven_audio
img = 'examples/source_image/{}.png'.format([持ってきた画像ファイル名])
print(img)
!python3.8 inference.py --driven_audio ./examples/driven_audio/[持ってきた音声ファイル名].wav \
--source_image {img} \
--result_dir ./results --still --preprocess full --enhancer gfpgan少し待つと results フォルダ内に mp4 ファイルが生成される。完成!
後はもう好きにダウンロードすればOK。
稀に次のようなエラーが起きることがあるが、顔画像の特徴点を取得できない場合に起きるっぽい。諦めて別の画像を使うのが良さそう?
# 悲しみのエラー
using safetensor as default
3DMM Extraction for source image
Traceback (most recent call last):
File "inference.py", line 144, in <module>
main(args)
File "inference.py", line 46, in main
first_coeff_path, crop_pic_path, crop_info = preprocess_model.generate(pic_path, first_frame_dir, args.preprocess,\
File "/content/SadTalker/src/utils/preprocess.py", line 103, in generate
x_full_frames, crop, quad = self.propress.crop(x_full_frames, still=True if 'ext' in crop_or_resize.lower() else False, xsize=512)
File "/content/SadTalker/src/utils/croper.py", line 131, in crop
raise 'can not detect the landmark from source image'
TypeError: exceptions must derive from BaseException補遺. SadTalkerの選定理由
SadTalker の類似手法は多くある。
GitHub の最終コミットや手法の提案時期的に、SadTalker が新しいため選定した。
他の手法でも同等のことは可能かと思う。
Wav2LipやMakeItTalkなどは、聞いたことがあるかもしれません。
それらと比較して、SadTalkerはワンランク上の次元です。
出来上がりのアニメーションが、他よりも自然になっています。
この記事が気に入ったらサポートをしてみませんか?