Pythonプログラミング 〜日本語をCSVファイルに書き出す時に知っておくべきこと〜

Pythonで処理した内容をCSVファイルとして書き出して、後でExcelで表示したいという時にどうするかという話です。
文字コードについての簡単な説明
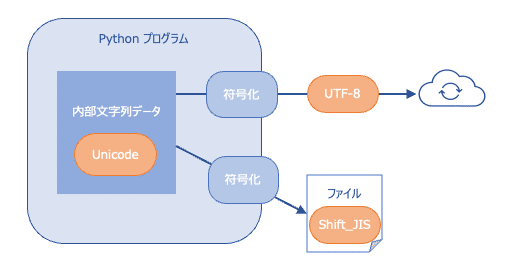
Pythonの文字列型では文字を表現するコードとしてUnicodeを使っています。Pythonで書かれたプログラムの文字列はプログラム内部ではUnicodeで表現されます。この文字列をプログラムの外に出力する際に別のコード表現に変換する「符号化」が行われます。
Unicodeは「文字集合」という、文字と一意に振られた番号のペアの集合で、世界中の文字を一つのコード体系で扱えるように設計されたものです。それまで国やベンダーによって色々あった文字コードを一つに集約するために1991年に制定されたものです。
世の中の文字を全部扱えるのですが、これをファイル出力や通信により他のコンピュータと通信すると「無駄な領域が多くなってしまう」「違うプロセッサに持っていくとバイト順が変わってしまいそのまま使えない」という問題が出るので、これを防ぐために違うコードに変換する「符号化」を行います。符号化のための方式には色々ありますが、ここでは"UTF-8"と"Shift_JIS"の2つを取り上げます。
UTF-8に符号化
UTF-8はUnicode用に設計されたもので、ファイルへの書き込みの場合はこれで符号化するのが基本的なやり方です。
ファイルをオープンするopen()の引数に encoding='utf-8' と指定することでUTF-8の文字コードでファイルに書き込むことができます。csvモジュールのwriterクラスを使うと簡単にcsvファイルが作れます。
import csv
data = [["名前","クラス"],["髙橋","1年Ⅰ組"],["山﨑","2年Ⅱ組"]]
with open('output.csv','w', encoding='utf-8') as f:
writer = csv.writer(f)
for row in data:
writer.writerow(row)ExcelはUTF-8の符号化にも対応していますので、作ったcsvファイルを読み込んで日本語を正しく表示することはできますが、ちょっと問題があります。Excelは、Shift-JISがデフォルトの文字コードになっているのでUTF-8のCSVファイルをダブルクリックで開くと、文字が化けて表示されてしまいます。
正しく表示するには、一度Excelを立ち上げて、メニューの「データ」から「データファイルを指定」を選び、ファイルを指定して読み込む必要があります。結構めんどくさいですし、あまり知られていない使い方なので、ファイルを他の人に送ったときに、開き方をいちいち教えるのも面倒です。
これを回避するためには、encoding='utf-8-sig'と指定してファイルを作ります。これだと、ダブルクリックで開いても最初からUTF-8と認識してくれます。'utf-8-sig'を指定すると、ファイルの先頭に、バイト順マークBOM(Byte Order Mark)という3バイトのコードが付加されます。Excelはこれを見てファイルがUTF-8だと認識します。(実は、UTF-8ではバイト順は影響しないので、本来の仕様ではBOMは必要ありません。BOMがあると正しく読み込めなくなるソフトウェアもありますので注意が必要です。)
Shift_JISに符号化
Unicodeの符号化方式としてはUTF-8が基本ですが、昔からの経緯でShift _JISにしか対応していないアプリケーションも数多くあり、どうしてもShift_JISでファイル出力したい場合もあります。
ここで問題になるのは、「Shift_JISはUnicodeで規定される文字の一部しか符号化できない」ことです。
Shift_JISは、元々Unicode以前から日本だけで使われるJIS X 0208文字集合を符号化する方式として、1982年に制定されたものです。JIS X 0208に含まれる文字は、選ばれた一部の日本語文字6879字に過ぎず、Shift_JISが対応しているのも基本的にこの範囲です。例えば、下のようなUnicodeには含まれている文字に対応できません。
髙(はしごだか)、﨑(たつさき)など人名によく出てくるような漢字
Ⅰ、Ⅱ、Ⅲ、Ⅳなどのローマ数字
が、ガなどに使われることがある結合文字列(結合文字列については下記参照)
対応していない文字をShift_JISで書き込むとUnicodeEncodeErrorというエラーが発生してしまいます。
UnicodeEncodeError: 'shift_jis' codec can't encode character '\u2160' in position 0: illegal multibyte sequenceエラーを起こさないためにはどうすれば良いのでしょう?
正規化をする
Unicode正規化とは、同じ意味の文字や文字の並びを統一的な内部表現に変換することです。unicodedataモジュールをインポートして、unicodedata.normalize()で正規化ができます。これにより、結合文字列で表されている「が」や「ガ」などの文字はShift-jisで扱える、通常の文字に変換されます。
違う文字に置き換える
「髙」を「高」、「﨑」を「崎」などShift_JISが対応していない文字を、対応している文字に置き換えるというやり方です。やり方は色々ありそうですが、複数の文字を置き換えるのであればstr.translate()を使うのが良さそうです。
変換するのを諦める
とは言っても、Shift-JISが対応していない全ての文字を何かに置き換えるのは不可能なので、最終的には諦めるしかありません。
open()の引数にerrors='ignore'を指定すると、対応していない文字は「無かった事」として無視してくれます。errors='replace'を指定すると、対応していない文字を「?」に置き換えてくれます。(errorsの引数指定でできることは他にもありますが、長くなるのでここでは割愛します。)
上の3つのやり方を組み合わせたサンプルが以下です。
import unicodedata
import csv
import ast
data = [["名前","クラス"],["髙橋","1年Ⅰ組"],["山﨑","2年Ⅱ組"]]
dictionary = {
"髙":"高",
"﨑":"崎",
"Ⅰ":"1"
}
trans_table = str.maketrans(dictionary)
data_string = str(data) #リストを文字列化
data_string = unicodedata.normalize('NFC', data_string) #正規化する
data_string = data_string.translate(trans_table) #違う文字に置き換える
data = ast.literal_eval(data_string) #文字列をリストに戻す
# Shift-JISでエンコードし、変換できない文字は'?'に変換
with open('output.csv','w', encoding='shift-jis', errors='replace') as f:
writer = csv.writer(f)
for row in data:
writer.writerow(row)Unicode以前にプログラマをやっていた私にとっては、以前と比べると日本語文字列の扱い方は格段に楽になっています。それでも結構面倒なことは、まだありますね。
この記事が気に入ったらサポートをしてみませんか?