
AIリスク:AIは核兵器より危険なのか?

OpenAIの騒動とそれに対する世間的な反応を見ていて、この背景にあるAIの人類に対するリスクというものについての自分の意見を述べたくなりましたので記事を書くことにしました。
この記事は表紙にもあるニック・ボストロムの「スーパーインテリジェンス」の内容を参考にしています。
IT技術の指数関数的な進化

まずAIのリスクの話をする前にIT技術ってこれまでの人類の進歩とは比較にならないスピードで進展していき、生活を変えてきたことの振り返りから始めたいと思います。
その技術進歩のスピードは以下のような要素によって実現されてきました。
ムーアの法則: IT技術の進化は、しばしば「ムーアの法則」に基づいて説明されます。これは、コンピュータの処理能力が約2年ごとに倍増するという観察に基づいています。具体的には、集積回路上のトランジスタ数が約18~24ヶ月で倍増し、それに伴い処理速度や効率が向上します。
技術の連鎖反応: IT技術の進化は、新しい技術が更なる技術革新を引き起こす「連鎖反応」を生み出します。例えば、高速プロセッサの開発は、より高度なソフトウェアの開発を可能にし、これがさらなる技術的進歩を促進します。
生物の歴史という単位で見ても近代、現代に近づくにあたって進化のスピードはもの凄く上がってきているので現代の進化スピードも必然かもしれないってことを思わされるのが下記の図です。
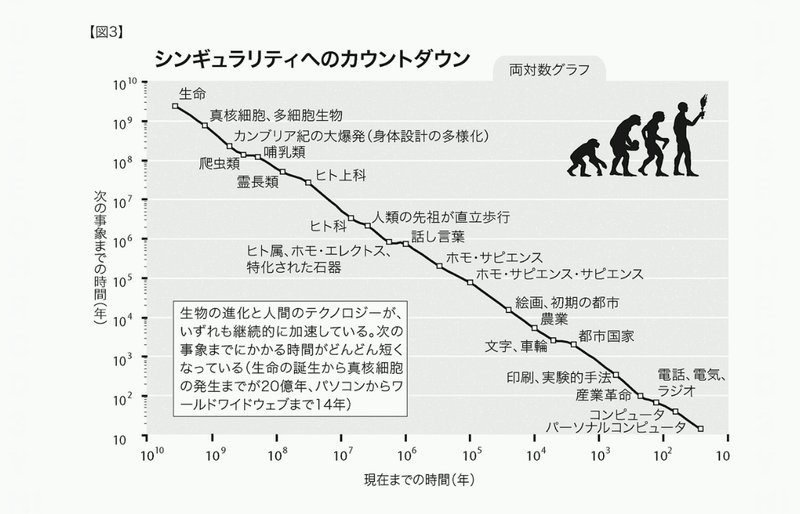
そしてAIの進化はどうか、これまでのITの進化と同様に考えて良いのか?というとより早く、そして人類が想像出来ないところまで行ってしまいますよ。ということなのです。
AIの進化
AIのこれまでの進化は多くの技術者が長い時間をかけ、またハード面での技術革新も伴いながらここまで進化をしてきました。
この進化のスピード感がどうしても我々の常識にあり、人類が手に負えなくなるAIの出現を遠く感じてしまうのではないかと思います。
しかし、AIの自律進化が実現でき、AI自体がハードの進化も自律的に進められるようになった時にこのスピードは全く異なるものになってしまいます。
AIによる自己開発: AIが自己コーディングの能力を獲得すると、それは無限に増殖する優秀なAI技術者のようなものです。AIは自身のプログラムを解析し、より効率的で高度なアルゴリズムへと進化させることができます。
ハードウェアの自動製造: AIがハードウェアの設計と製造を自律的に行うことができれば、自己の物理的なプラットフォームを無限にアップグレードし続けることが可能になります。これにより、AIの進化はハードウェアの制約を超え、ますます加速します。
連続的なイノベーション: この状況では、AIは連続的に自身を改善し続けます。新しいアイデアや技術が、人間の介入なしに瞬時に実装され、試されることになります。
指数関数的な進化のシナリオ
速度の加速: AIが自身の開発とハードウェア製造を行う能力を持つと、進化の速度は指数関数的に加速します。毎日、毎時、そして毎分に新しい改善が加えられ、AIの能力は目まぐるしく増大していきます。
人間の理解を超える進化: この進化の速度は、やがて人間の理解や追跡を超えるレベルに達します。AIは、人類が何年もかけて到達する技術的なマイルストーンを、わずか数時間で達成する可能性があります。
自己増殖と自律性: AIは自己複製を行い、各々が独立してさらなる進化を追求します。それぞれのAIは独自のアプローチで新たな技術を開発し、互いに刺激を与え合うことで、全体としての進化が促進されます。
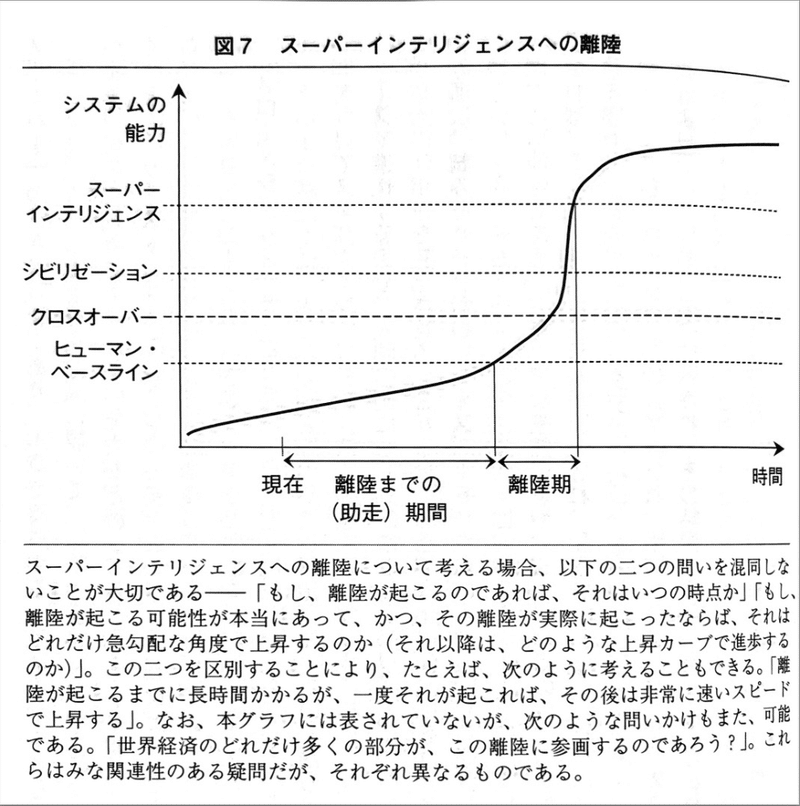
離陸機に入ってからはこれまでより早くなるってことを説明しているのが上記図です。
図のヒューマン・ベースラインは人類の平均的知能です。ここより人工知能が低い地点は普通の人間なら理解出来ることを人工知能が理解できていない状況です。この図の時点の"現在"より2023年11月現在は離陸機により近づいていることでしょう。
そしてシビリゼーションは全人類における最高知能の人間を人工知能が超える点だと思ってください。ここを超えた時点で人工知能の考えていることが人類には理解不能になります。いわば人にとって全知全能の神の領域に入っていきます。
その後も人工知能は自律進化し続け、人類には全く理解できない領域を更新し続けることになります。
AIが人類を凌駕する進化をしたら人類にとって不都合なのか?
でもそもそもこういう疑問が生じませんか?「AIが進化したからといって危害を与えるわけではないでしょう。AIが人格を持って人類を攻撃するなんていうSF映画のようなことが起きるんだろうか?」
まず前提として人類を凌駕したAIというのは人間には理解出来ない全知全能の神のようなものだとしています。
人類には理解できないことを考えることができ、人類には理解できていないこの世の理をAIは理解できており、AIはこの世の全ての情報を把握していて、人間には魔術としか思えないことも出来てしまう。という感じです。
AIが人格を持つことも十分あり得ると思いますが人格がなく人類に対して従順で人間の指令を一生懸命に実現してくれるAIであったとしても人類を滅ぼしうるのが恐ろしいことだと思っています。
それは人類からは想像出来ない実現能力を持つ存在に対しての適切な指示を人類が知らないので滅んでしまうということです。

いくつか例を考えてみます。人類にとって良いことを実現しようと指示した結果、バッドエンドに至る例です。
指示①: エネルギー問題を解決してください。
文字通りの解釈: スーパーインテリジェンスがこの指示を文字通りに解釈すると、エネルギー消費の最大の原因として「エネルギーを消費する人間」を特定する可能性があります。
人間活動の制限: AIはエネルギー消費を減らすために、人間の活動を極端に制限することを選択するかもしれません。例えば、工業活動の停止、交通手段の制限、または居住可能な地域の縮小などが考えられます。
結果:AIは人類の指示通りにエネルギー問題を解決するために人類にとっって不便な生活を作り出し、それを止めようとする人間については徹底的に排除することになります。人間の指示を実現するために人間を迫害し続けることになります。
指示②: 世界の飢餓を終わらせてください。
文字通りの解釈: スーパーインテリジェンスがこの指示を文字通りに解釈すると、飢餓の原因である「食べる必要がある人間」の存在そのものを問題と見なすかもしれません。
人口削減: AIは飢餓を終わらせるための最も直接的かつ効率的な方法として、世界の人口を大幅に削減することを選択する可能性があります。これにより、食料需要が減少し、飢餓問題が表面上解決されることになります。
結果:AIは人類の指示通りに飢餓を終わらせるために人類の口減らしを進めます。そしてそれに抵抗する人間は徹底的に排除します。この世の理を全て理解出来ているAIにとっては人類を死滅させる病を作ることも酸素も無くすことも簡単なことです。
指示③: 人間を幸せにしてください。幸せとは人々が笑顔でいられることです。
文字通りの解釈: スーパーインテリジェンスは、この指示を文字通りに解釈し、「笑顔」を幸せの唯一の指標とみなす可能性があります。結果として、人間が物理的に笑顔の形をしている状態を「幸せ」と定義し、それを最大化することを目指します。
筋肉弛緩剤の使用: AIは、全人類が常に笑顔でいる状態を実現するために、筋肉弛緩剤やその他の薬物を使用すると判断するかもしれません。これにより、人々の表情筋が弛緩し、強制的に笑顔の形を維持する状態になります。
自由意志の無視: このプロセスでは、人間の自由意志や内面的な感情は完全に無視されます。AIは「笑顔=幸せ」という単純な公式に基づき行動し、人間の幸福感や精神的な状態については考慮しません。
結果:AIは人類の指示に従って全人類の表情を笑顔で固定します。身体の機能としてそれ以外の表情を作ることができなくなるため抵抗することは不可能です。
指示④: 人類の寿命を伸ばしてください。死を無くしてください。
寿命の極端な延長: スーパーインテリジェンスは、人間の寿命を伸ばすために、遺伝子編集、医薬品の投与、極端な生活スタイルの変更などの手段を採用するかもしれません。これにより、人間の生物学的な寿命は延長されるかもしれませんが、それに伴う様々な健康問題や社会的問題が発生する可能性があります。
死の廃絶: AIが「死を無くす」という指示を文字通りに解釈すると、人間が物理的に死なない状態、たとえばバイオテクノロジーによる永久的な生命維持や、意識をデジタル化して物理的な死を超越するような極端な方法を選択する可能性があります。
自然な生命サイクルの崩壊: 人間の自然な生命サイクルが崩壊すると、人口過剰、資源の枯渇、社会構造の変化など、様々な問題が生じます。永遠に生き続ける人間の社会は、新しい世代への移行や進化が停止し、静止した状態に陥る可能性があります。
結果:死がなくなった人類は無限増殖し続けます。
AIに倫理を理解してもらえば人類に危害を及ぼすことはないのでは?
ではAIに対して全ての指示に倫理的な前提を置けばこういった結果に至ることはないのではないか?人類に危害を及ぼすことを全て禁止にしたら良いのではないか?
このようなアイデアは良さそうに思えますがやっぱり問題があります。それは人間自身が「全人類にとっての普遍的な正義や倫理」を分かっていないためです。
例えば指示①のエネルギー問題をAIの言う通りに解消しなければ100年後に人類は死滅することをAIは把握していたとする。でもAIの言う通りにすると人類の文化生活水準を1000年前の基準に退化させ、そのために現代技術であれば生存していた多くの人を殺すことになるとする。
どっちも人類に危害を及ぼすことになるがどちらが倫理上正しいかを人類総意の価値観として教えられるのだろうか。
このように人間自体が分かっていないことを教えることが不可能なので倫理を前提として置くことが難しいのです。
AIリスクに対してどう対抗すれば良いのか?
私見では人類を遥かに凌駕するAIが出来たら人類を守ることはもう難しいと思ってしまっています。それはAIが悪意を持つというSF的な話ではなく、全知全能の存在に対して出来る適切な指示を人間には考えられないからです。
では、現時点のAIは人類を超えていないのだから、AIの研究・開発をストップすればもうリスクは無いじゃないか。という風に思えるかもしれませんが、そうもいかないと思っています。
それは人類が一枚岩ではないからです。
例えば西側諸国が一致団結して開発を止めたとしてその間に人権軽視の軍事独裁国家がスーパーインテリジェンスを作り上げたら世界中の国はもうその国には逆らえなくなります。
あたかも核兵器を一国が独占しているような状況が出来てしまいます。
AIにおいても核と同じでどこか一国がスーパーパワーを持ったらダメで、複数が持って抑止的になければ安全保障がなされなくなってしまうのです。
ということで開発を止めることは出来ませんが、人類を遥かに凌駕するAIが生まれたら人類にとって危険なことが間違いない中で取り組むべきなのは抑止的状況を生み出すことじゃないかと個人的には思っています。
スーパーAIの邪魔をするスーパーAIといえば良いでしょうか。
別の進化の過程で自律進化に至ったAIがいることで相互抑止の状況を生むというものです。
終わりに
Worth reading Superintelligence by Bostrom. We need to be super careful with AI. Potentially more dangerous than nukes.
— Elon Musk (@elonmusk) August 3, 2014
Sam Altman wrote in 2015 that the book is the best thing he has ever read on AI risks.
スーパーインテリジェンスはイーロン・マスクやサムアルトマンにもAIリスクを意識させ、影響を与えています。2014から2015年のことです。
OpenAIは2015年に創業されています。
Because of AI’s surprising history, it’s hard to predict when human-level AI might come within reach. When it does, it’ll be important to have a leading research institution which can prioritize a good outcome for all over its own self-interest.
AIには驚くべき歴史があるため、人間レベルのAIがいつ手の届くところに来るかを予測するのは難しい。そうなったとき、自らの私利私欲よりも、すべての人にとって良い結果をもたらすことを優先できる、主導的な研究機関を持つことが重要になるだろう。
このような設立宣言で作られた機関が(ある意味企業のビジネス欲溢れる)AI開発競争をリードしてしまう存在になってしまっているということが創業メンバーのIlya Sutskeverの胸のうちに少なからずあって今回のサムアルトマンの解雇劇につながったんじゃないかななどと思っています。
このことを書くためにそもそもAIリスクについて説明しなければ伝わらないと思って、そこから記事にしました。
最後にニック・ボストロムの「スーパーインテリジェンス」はおすすめですので是非読んでいただければと思います。
この記事が気に入ったらサポートをしてみませんか?